multi-GPU环境下的batch normalization需要特殊实现吗?
3年前曾经写过关于分布式环境下batch normalization是否需要特殊实现的讨论:
batch normalization的multi-GPU版本该怎么实现? 【Tensorflow 分布式PS/Worker模式下异步更新的情况】
==============================================
当时我给出的观点就是在多卡环境下batch normalization使用每个step内的各显卡batch上的相关值进行同步的话会和单卡情况取得相似的结果,因此我给出的结论就是多卡情况下是没有必要针对batch normalization算子开发什么高深的替代版本,你不论是同步更新还是异步更新的情况下对每个显卡上运行得到的batch normalization算子中的参数进行同样的update就可以了,因为从我之前做的仿真使用中可以看出不论是单机情况还是多卡同/异步更新情况下都是对batch normalization算子中参数的估计,而这几种方法之间的差别其实不大,可以说极为相近,也正是如此在几年前我就得出了没有必要为多卡/分布式环境下设计特殊的batch normalization算子,不管是同步更新还是异步更新同时对batch normalization算子中的参数进行同样操作就和单卡情况下不会有太大的差距。几年前得到这个结论的时候只是考个人推断和仿真实验获得的,并没有在实际的代码上跑过,当时主要的原因就是省时、省力,同时也是对但是网上的各种针对多卡/分布式环境下开发出的特殊batch normalization算子的一种反对意见,最近看到一篇可以佐证我观点的文章这里给出相关链接并摘录出部分内容:
https://zhuanlan.zhihu.com/p/402198819
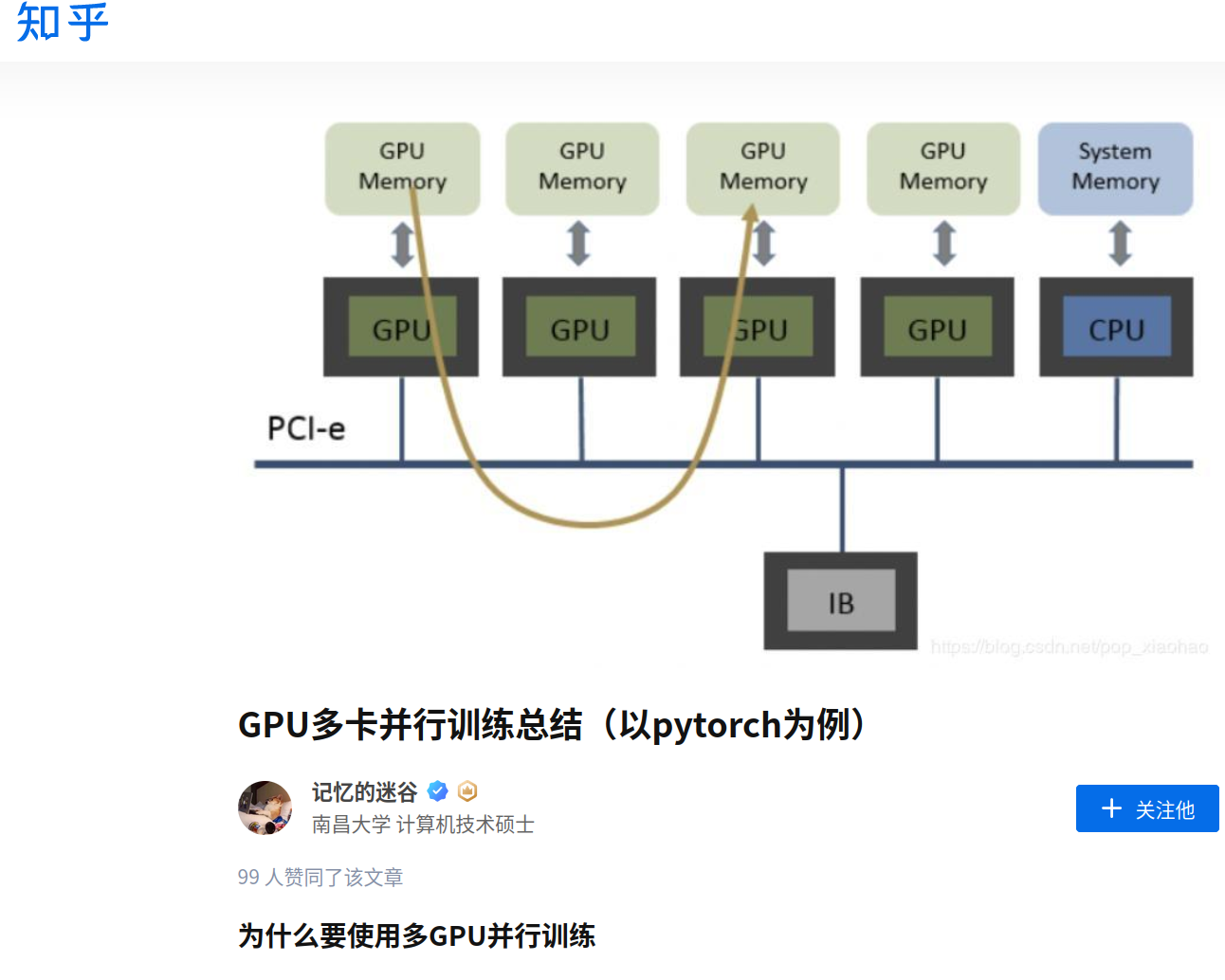
=========================================
在上面的那个文章中给出了讨论和实验:
-------------------------------------------------
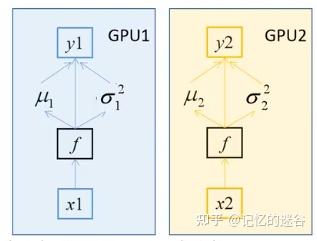
假设batch_size=2,每个GPU计算的均值和方差都针对这两个样本而言的。而BN的特性是:batch_size越大,均值和方差越接近与整个数据集的均值和方差,效果越好。使用多块GPU时,会计算每个BN层在所有设备上输入的均值和方差。如果GPU1和GPU2都分别得到两个特征层,那么两块GPU一共计算2 4 个特征层的均值和方差,可以认为batch_size=4。注意:如果不用同步BN,而是每个设备计算自己的批次数据的均值方差,效果与单GPU一致,仅仅能提升训练速度;如果使用同步BN,效果会有一定提升,但是会损失一部分并行速度。
BN如何在不同设备之间同步?
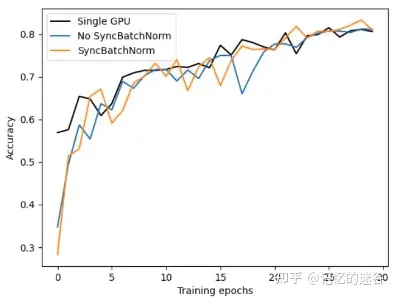
下图为单GPU、以及是否使用同步BN训练的三种情况,可以看到使用同步BN(橙线)比不使用同步BN(蓝线)总体效果要好一些,不过训练时间也会更长。使用单GPU(黑线)和不使用同步BN的效果是差不多的。
-------------------------------------------------
我三年前的文章指出多卡/分布式情况下使用同步或异步的方式更新batch normalization算子中的参数会和单卡情况下的性能相似,而上面的这篇文章也同样验证了这个观点;甚至从上面的这个文章中可以看到多卡情况下同步更新batch normalization算子中的参数往往会得到更好的效果,当然这个性能相差的也不是十分的明显。
这里我甚至有个新的观点,那就是多卡情况下即使不对batch normalization算子在训练过程中更新(同步、异步更新都包括),而是在训练结束后再进行取均值的更新方式也不会有太大的性能差距,总结的来说就是我个人认为多卡/分布式环境下batch normalization算子的参数的计算使用下面三种方式都和单卡情况下相差不大:
1. 训练过程中同步更新batch normalization算子参数;
2. 训练过程中异步更新batch normalization算子参数;
3. 训练结束后再更新batch normalization算子参数;
不过这三种方式即使相差不大也必然虽然一个谁优谁劣的问题,而这个回答确实是难以给出的,因为这个定论需要对不同的数据集和任务进行计算,大量的获取各种情况下的最终性能指标才可以有个定论,不过这里也给出我的个人建议,那就是:
对性能要求较为严格的情况下建议使用第一种方式,即训练过程中同步更新batch normalization算子参数;而对性能要求的容忍度较大的情况下可以考虑使用第三种方式,也就是训练结束后再更新batch normalization算子;而对于第二种方式,也就是训练过程中异步更新batch normalization算子其实是要单独分析的,因为pytorch是本身不支持异步更新的,当然你可以自己来进行实现(官方只给了同步更新的code),而TensorFlow由于并不是像pytorch使用MPI而是使用自己公司的protobuffer因此可以完美的支持异步更新(异步更新需要考虑如何处理不同时延下的更新策略,需要单独设计分布式算法来决定何时合并参数何时抛弃参数),所以对于异步更新batch normalization算子参数的方式并不是很建议。
=========================================
multi-GPU环境下的batch normalization需要特殊实现吗?的更多相关文章
- Batch Normalization的算法本质是在网络每一层的输入前增加一层BN层(也即归一化层),对数据进行归一化处理,然后再进入网络下一层,但是BN并不是简单的对数据进行求归一化,而是引入了两个参数λ和β去进行数据重构
Batch Normalization Batch Normalization是深度学习领域在2015年非常热门的一个算法,许多网络应用该方法进行训练,并且取得了非常好的效果. 众所周知,深度学习是应 ...
- 手把手教你在win10下搭建pytorch GPU环境(Anaconda+Pycharm)
Anaconda指的是一个开源的Python发行版本,其主要优点如下: Anaconda默认安装了常见的科学计算包,用它搭建起Python环境后不用再费时费力安装这些包: Anaconda可以创建互相 ...
- 从Bayesian角度浅析Batch Normalization
前置阅读:http://blog.csdn.net/happynear/article/details/44238541——Batch Norm阅读笔记与实现 前置阅读:http://www.zhih ...
- 《RECURRENT BATCH NORMALIZATION》
原文链接 https://arxiv.org/pdf/1603.09025.pdf Covariate 协变量:在实验的设计中,协变量是一个独立变量(解释变量),不为实验者所操纵,但仍影响实验结果. ...
- How Does Batch Normalization Help Optimization?
1. 摘要 BN 是一个广泛应用的用于快速稳定地训练深度神经网络的技术,但是我们对其有效性的真正原因仍然所知甚少. 输入分布的稳定性和 BN 的成功之间关系很小,BN 对训练过程更根本的影响是:它让优 ...
- [C2W3] Improving Deep Neural Networks : Hyperparameter tuning, Batch Normalization and Programming Frameworks
第三周:Hyperparameter tuning, Batch Normalization and Programming Frameworks 调试处理(Tuning process) 目前为止, ...
- 深度解析Droupout与Batch Normalization
Droupout与Batch Normalization都是深度学习常用且基础的训练技巧了.本文将从理论和实践两个角度分布其特点和细节. Droupout 2012年,Hinton在其论文中提出Dro ...
- Win10环境下YOLO5 快速配置与测试
目录 一.更换官方源 二.安装Pytorch+CUDA(python版本) 三.YOLO V5 配置与验证 四.数据集测试 五.小结 不想看前面,可以直接跳到标题: 一.更换官方源 在 YOLO V5 ...
- WIN7环境下CUDA7.5的安装、配置和测试(Visual Studio 2010)
以下基于"WIN7(64位)+Visual Studio 2010+CUDA7.5". 系统:WIN7,64位 开发平台:Visual Studio 2010 显卡:NVIDIA ...
- [CS231n-CNN] Training Neural Networks Part 1 : activation functions, weight initialization, gradient flow, batch normalization | babysitting the learning process, hyperparameter optimization
课程主页:http://cs231n.stanford.edu/ Introduction to neural networks -Training Neural Network ________ ...
随机推荐
- 《Android开发卷——开卷》
打算在自己在工作中遇到的问题,技术难点都记录下来,让其他人可以借鉴或者指点,这样既可以成长自己也可以成长别人.因为自己已经在工作了,所以遇到的问题非常具有代表性,所以不能简单简单的像网上一些小学生一样 ...
- word文档生成视频,自动配音、背景音乐、自动字幕,另类创作工具
简介 不同于别的视频创作工具,这个工具创作视频只需要在word文档中打字,插入图片即可.完事后就能获得一个带有配音.字幕.背景音乐.视频特效滤镜的优美作品. 这种不要门槛,没有技术难度的视频创作工具, ...
- C# 循环枚举
foreach (int eemun in Enum.GetValues(typeof(类名))) { string sName = Enum.GetName(typeof(类名), eemun);/ ...
- DHorse的配置文件
首先看一下DHorse的配置文件,如下: #============================================================================== ...
- 未能加载文件或程序集“netstandard,Version=2.0.0.0, Culture=neutral,PublicKeyToken=cc7b13ffcd2ddd51”或它的某一个依赖项 解决
未能加载文件或程序集"netstandard,Version=2.0.0.0, Culture=neutral,PublicKeyToken=cc7b13ffcd2ddd51"或它 ...
- CSS 属性计算
CSS 属性计算过程 你是否了解 CSS 的属性计算过程呢? 有的同学可能会讲,CSS属性我倒是知道,例如: p{ color : red; } 上面的 CSS 代码中,p 是元素选择器,color ...
- C++获取商店应用(msix应用)桌面快捷方式的安装目录
传统应用的快捷方式目标指向可执行文件的路径,但是对于商店应用(也叫msix打包应用),则指向一个奇怪的字符串,使用IShellLink::GetPath获取路径时,则得到的是空字符串,而我们的最终目的 ...
- Vim有哪几种模式?
Vim有哪几种模式? 模式一:normal模式 作用主要是用来浏览,输入各种和在文档中移动. 模式二:编辑模式 用于对文件的编辑: 常用的插入命令: a在光标位置后编辑, i在光标位置前编辑, o在下 ...
- ABP框架开发实例教程-获取前端样式和脚本
1.运行生成的ABP框架,设置WEB.MVC项目为启动项目,点击开始运行,界面如下,样式和脚本文件不存在,所以导致界面无法正常显示,这个我研究ABP遇到的第二个坑,第一个坑是生成数据库. 2.为什么没 ...
- SpringBoot能同时处理多少请求
SpringBoot默认的内嵌容器是Tomcat,也就是我们的程序实际上是运行在Tomcat里的.所以与其说SpringBoot可以处理多少请求,到不如说Tomcat可以处理多少请求. 关于Tomca ...