tensorflow:实战Google深度学习框架第四章02神经网络优化(学习率,避免过拟合,滑动平均模型)
1、学习率的设置既不能太小,又不能太大,解决方法:使用指数衰减法
例如:
假设我们要最小化函数 y=x2y=x2, 选择初始点 x0=5x0=5
import tensorflow as tf
TRAINING_STEPS = 10
LEARNING_RATE = 1
x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x")
y = tf.square(x) train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y) with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
sess.run(train_op)
x_value = sess.run(x)
print "After %s iteration(s): x%s is %f."% (i+1, i+1, x_value)
After 1 iteration(s): x1 is -5.000000.
After 2 iteration(s): x2 is 5.000000.
After 3 iteration(s): x3 is -5.000000.
After 4 iteration(s): x4 is 5.000000.
After 5 iteration(s): x5 is -5.000000.
After 6 iteration(s): x6 is 5.000000.
After 7 iteration(s): x7 is -5.000000.
After 8 iteration(s): x8 is 5.000000.
After 9 iteration(s): x9 is -5.000000.
After 10 iteration(s): x10 is 5.000000.
2. 学习率为0.001的时候,下降速度过慢,在901轮时才收敛到0.823355
TRAINING_STEPS = 1000
LEARNING_RATE = 0.001
x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x")
y = tf.square(x) train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y) with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
sess.run(train_op)
if i % 100 == 0:
x_value = sess.run(x)
print "After %s iteration(s): x%s is %f."% (i+1, i+1, x_value)
After 1 iteration(s): x1 is 4.990000.
After 101 iteration(s): x101 is 4.084646.
After 201 iteration(s): x201 is 3.343555.
After 301 iteration(s): x301 is 2.736923.
After 401 iteration(s): x401 is 2.240355.
After 501 iteration(s): x501 is 1.833880.
After 601 iteration(s): x601 is 1.501153.
After 701 iteration(s): x701 is 1.228794.
After 801 iteration(s): x801 is 1.005850.
After 901 iteration(s): x901 is 0.823355.
3. 使用指数衰减的学习率,在迭代初期得到较高的下降速度,可以在较小的训练轮数下取得不错的收敛程度
TRAINING_STEPS = 100
global_step = tf.Variable(0)
LEARNING_RATE = tf.train.exponential_decay(0.1, global_step, 1, 0.96, staircase=True) x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x")
y = tf.square(x)
train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y, global_step=global_step) with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
sess.run(train_op)
if i % 10 == 0:
LEARNING_RATE_value = sess.run(LEARNING_RATE)
x_value = sess.run(x)
print "After %s iteration(s): x%s is %f, learning rate is %f."% (i+1, i+1, x_value, LEARNING_RATE_value)
After 1 iteration(s): x1 is 4.000000, learning rate is 0.096000.
After 11 iteration(s): x11 is 0.690561, learning rate is 0.063824.
After 21 iteration(s): x21 is 0.222583, learning rate is 0.042432.
After 31 iteration(s): x31 is 0.106405, learning rate is 0.028210.
After 41 iteration(s): x41 is 0.065548, learning rate is 0.018755.
After 51 iteration(s): x51 is 0.047625, learning rate is 0.012469.
After 61 iteration(s): x61 is 0.038558, learning rate is 0.008290.
After 71 iteration(s): x71 is 0.033523, learning rate is 0.005511.
After 81 iteration(s): x81 is 0.030553, learning rate is 0.003664.
After 91 iteration(s): x91 is 0.028727, learning rate is 0.002436. 2、过拟合
要避免过拟合,解决办法:正则化
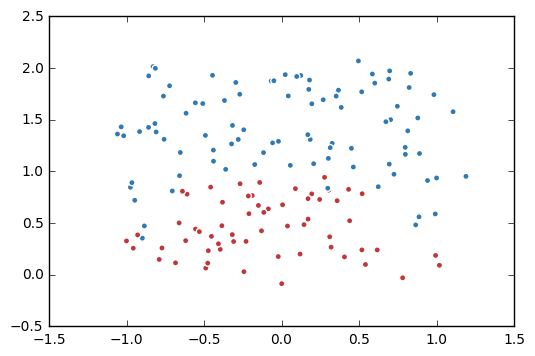
1. 生成模拟数据集。
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np data = []
label = []
np.random.seed(0) # 以原点为圆心,半径为1的圆把散点划分成红蓝两部分,并加入随机噪音。
for i in range(150):
x1 = np.random.uniform(-1,1)
x2 = np.random.uniform(0,2)
if x1**2 + x2**2 <= 1:
data.append([np.random.normal(x1, 0.1),np.random.normal(x2,0.1)])
label.append(0)
else:
data.append([np.random.normal(x1, 0.1), np.random.normal(x2, 0.1)])
label.append(1) data = np.hstack(data).reshape(-1,2)
label = np.hstack(label).reshape(-1, 1)
plt.scatter(data[:,0], data[:,1], c=label,
cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.show()
2. 定义一个获取权重,并自动加入正则项到损失的函数
def get_weight(shape, lambda1):
var = tf.Variable(tf.random_normal(shape), dtype=tf.float32)
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lambda1)(var))
return var
3. 定义神经网络。
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
sample_size = len(data) # 每层节点的个数
layer_dimension = [2,10,5,3,1] n_layers = len(layer_dimension) cur_layer = x
in_dimension = layer_dimension[0] # 循环生成网络结构
for i in range(1, n_layers):
out_dimension = layer_dimension[i]
weight = get_weight([in_dimension, out_dimension], 0.003)
bias = tf.Variable(tf.constant(0.1, shape=[out_dimension]))
cur_layer = tf.nn.elu(tf.matmul(cur_layer, weight) + bias)
in_dimension = layer_dimension[i] y= cur_layer # 损失函数的定义。
mse_loss = tf.reduce_sum(tf.pow(y_ - y, 2)) / sample_size
tf.add_to_collection('losses', mse_loss)
loss = tf.add_n(tf.get_collection('losses'))
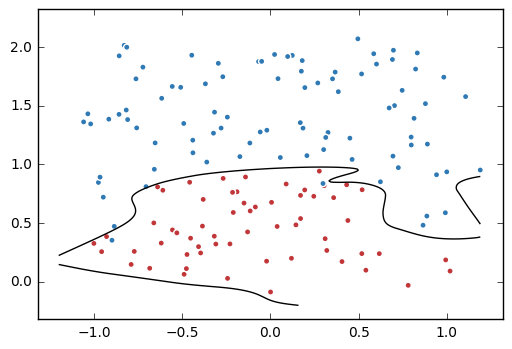
4. 训练不带正则项的损失函数mse_loss
# 定义训练的目标函数mse_loss,训练次数及训练模型
train_op = tf.train.AdamOptimizer(0.001).minimize(mse_loss)
TRAINING_STEPS = 40000 with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
sess.run(train_op, feed_dict={x: data, y_: label})
if i % 2000 == 0:
print("After %d steps, mse_loss: %f" % (i,sess.run(mse_loss, feed_dict={x: data, y_: label}))) # 画出训练后的分割曲线
xx, yy = np.mgrid[-1.2:1.2:.01, -0.2:2.2:.01]
grid = np.c_[xx.ravel(), yy.ravel()]
probs = sess.run(y, feed_dict={x:grid})
probs = probs.reshape(xx.shape) plt.scatter(data[:,0], data[:,1], c=label,
cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.contour(xx, yy, probs, levels=[.5], cmap="Greys", vmin=0, vmax=.1)
plt.show()
After 0 steps, mse_loss: 2.315934
After 2000 steps, mse_loss: 0.054761
After 4000 steps, mse_loss: 0.047252
After 6000 steps, mse_loss: 0.029857
After 8000 steps, mse_loss: 0.026388
After 10000 steps, mse_loss: 0.024671
After 12000 steps, mse_loss: 0.023310
After 14000 steps, mse_loss: 0.021284
After 16000 steps, mse_loss: 0.019408
After 18000 steps, mse_loss: 0.017947
After 20000 steps, mse_loss: 0.016683
After 22000 steps, mse_loss: 0.015700
After 24000 steps, mse_loss: 0.014854
After 26000 steps, mse_loss: 0.014021
After 28000 steps, mse_loss: 0.013597
After 30000 steps, mse_loss: 0.013161
After 32000 steps, mse_loss: 0.012915
After 34000 steps, mse_loss: 0.012671
After 36000 steps, mse_loss: 0.012465
After 38000 steps, mse_loss: 0.012251
5. 训练带正则项的损失函数loss。
# 定义训练的目标函数loss,训练次数及训练模型
train_op = tf.train.AdamOptimizer(0.001).minimize(loss)
TRAINING_STEPS = 40000 with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
sess.run(train_op, feed_dict={x: data, y_: label})
if i % 2000 == 0:
print("After %d steps, loss: %f" % (i, sess.run(loss, feed_dict={x: data, y_: label}))) # 画出训练后的分割曲线
xx, yy = np.mgrid[-1:1:.01, 0:2:.01]
grid = np.c_[xx.ravel(), yy.ravel()]
probs = sess.run(y, feed_dict={x:grid})
probs = probs.reshape(xx.shape) plt.scatter(data[:,0], data[:,1], c=label,
cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.contour(xx, yy, probs, levels=[.5], cmap="Greys", vmin=0, vmax=.1)
plt.show()
After 0 steps, loss: 2.468601
After 2000 steps, loss: 0.111190
After 4000 steps, loss: 0.079666
After 6000 steps, loss: 0.066808
After 8000 steps, loss: 0.060114
After 10000 steps, loss: 0.058860
After 12000 steps, loss: 0.058358
After 14000 steps, loss: 0.058301
After 16000 steps, loss: 0.058279
After 18000 steps, loss: 0.058266
After 20000 steps, loss: 0.058260
After 22000 steps, loss: 0.058255
After 24000 steps, loss: 0.058243
After 26000 steps, loss: 0.058225
After 28000 steps, loss: 0.058208
After 30000 steps, loss: 0.058196
After 32000 steps, loss: 0.058187
After 34000 steps, loss: 0.058181
After 36000 steps, loss: 0.058177
After 38000 steps, loss: 0.058174

3、滑动平均模型
可以使模型有更好的表现
1. 定义变量及滑动平均类
import tensorflow as tf
v1 = tf.Variable(0, dtype=tf.float32)
step = tf.Variable(0, trainable=False)
ema = tf.train.ExponentialMovingAverage(0.99, step)
maintain_averages_op = ema.apply([v1])
2. 查看不同迭代中变量取值的变化。
with tf.Session() as sess:
# 初始化
init_op = tf.global_variables_initializer()
sess.run(init_op)
print sess.run([v1, ema.average(v1)])
# 更新变量v1的取值
sess.run(tf.assign(v1, 5))
sess.run(maintain_averages_op)
print sess.run([v1, ema.average(v1)])
# 更新step和v1的取值
sess.run(tf.assign(step, 10000))
sess.run(tf.assign(v1, 10))
sess.run(maintain_averages_op)
print sess.run([v1, ema.average(v1)])
# 更新一次v1的滑动平均值
sess.run(maintain_averages_op)
print sess.run([v1, ema.average(v1)])
[0.0, 0.0]
[5.0, 4.5]
[10.0, 4.5549998]
[10.0, 4.6094499]
tensorflow:实战Google深度学习框架第四章02神经网络优化(学习率,避免过拟合,滑动平均模型)的更多相关文章
- tensorflow:实战Google深度学习框架第四章01损失函数
深度学习:两个重要特性:多层和非线性 线性模型:任意线性模型的组合都是线性模型,只通过线性变换任意层的全连接神经网络与单层神经网络没有区别. 激活函数:能够实现去线性化(神经元的输出通过一个非线性函数 ...
- Tensorflow 实战Google深度学习框架 第五章 5.2.1Minister数字识别 源代码
import os import tab import tensorflow as tf print "tensorflow 5.2 " from tensorflow.examp ...
- [Tensorflow实战Google深度学习框架]笔记4
本系列为Tensorflow实战Google深度学习框架知识笔记,仅为博主看书过程中觉得较为重要的知识点,简单摘要下来,内容较为零散,请见谅. 2017-11-06 [第五章] MNIST数字识别问题 ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
- TensorFlow+实战Google深度学习框架学习笔记(5)----神经网络训练步骤
一.TensorFlow实战Google深度学习框架学习 1.步骤: 1.定义神经网络的结构和前向传播的输出结果. 2.定义损失函数以及选择反向传播优化的算法. 3.生成会话(session)并且在训 ...
- 学习《TensorFlow实战Google深度学习框架 (第2版) 》中文PDF和代码
TensorFlow是谷歌2015年开源的主流深度学习框架,目前已得到广泛应用.<TensorFlow:实战Google深度学习框架(第2版)>为TensorFlow入门参考书,帮助快速. ...
- TensorFlow实战Google深度学习框架-人工智能教程-自学人工智能的第二天-深度学习
自学人工智能的第一天 "TensorFlow 是谷歌 2015 年开源的主流深度学习框架,目前已得到广泛应用.本书为 TensorFlow 入门参考书,旨在帮助读者以快速.有效的方式上手 T ...
- TensorFlow实战Google深度学习框架1-4章学习笔记
目录 第1章 深度学习简介 第2章 TensorFlow环境搭建 第3章 TensorFlow入门 第4章 深层神经网络 第1章 深度学习简介 对于许多机器学习问题来说,特征提取不是一件简单的事情 ...
- TensorFlow实战Google深度学习框架10-12章学习笔记
目录 第10章 TensorFlow高层封装 第11章 TensorBoard可视化 第12章 TensorFlow计算加速 第10章 TensorFlow高层封装 目前比较流行的TensorFlow ...
随机推荐
- Windows程序设计(1)——Win32运行原理(二)
创建进程 1 进程和线程 2 应用程序的启动过程 3 CreateProcess函数 4 实例 3 创建进程 3.1 进程和线程 进程通常被定义为一个存在运行的程序的实例.进程是一个正在运行的程序,它 ...
- Codeforces Round #373 (Div. 2) Anatoly and Cockroaches —— 贪心
题目链接:http://codeforces.com/contest/719/problem/B B. Anatoly and Cockroaches time limit per test 1 se ...
- 千锋很火的SpringBoot实战开发教程视频
springboot是什么? Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员 ...
- 花了5天时间,终于解决了一个bug,心情非常愉快,憋了这么久,不吐不快
http://www.cnweblog.com/fly2700/archive/2011/12/06/318916.html (转载) 花了5天时间,终于解决了一个bug,心情非常愉快,憋了这么久,不 ...
- codeforces B. Marathon 解题报告
题目链接:http://codeforces.com/problemset/problem/404/B 题目意思:Valera 参加马拉松,马拉松的跑道是一个边长为a的正方形,要求Valera从起点( ...
- Win8风格的WPF按钮
Win8将Windows的风格又进行了一次变革,我还挺喜欢的,有简洁大气的感觉,华丽绚丽的东西看多了之后总会返璞归真寻找简洁大气的感觉才能心情舒畅. 下面就给个WPF下Button的自定义写法. ...
- slim.flatten——将输入扁平化但保留batch_size,假设第一维是batch
slim.flatten(inputs,outputs_collections=None,scope=None) (注:import tensorflow.contrib.slim as slim) ...
- html5 WebWorkers 防止浏览器假死
在Web开发的时候经常会遇到浏览器不响应事件进入假死状态,甚至弹出“脚本运行时间过长“的提示框,如果出现这种情况说明你的脚本已经失控了. 一个浏览器至少存在三个线程:js引擎线程(处理js).GUI渲 ...
- POJ2217(最长公共子串)
Secretary Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 992 Accepted: 408 Descripti ...
- sql语句之查询操作
语法顺序: select distinct 字段1,字段2,字段3 from 库.表 where 条件 group by 分组条件 having 过滤 # 执行顺序的话,到这步会返回运行select语 ...