PostgreSQL 如何优化索引效率
使用 gin() 创建全文索引后,虽然有走索引,但是当结果集很大时,查询效率还是很底下,
SELECT keyword,avg_mon_search,competition,impressions,ctr,position,suggest_bid,click,update_time
FROM keyword
WHERE
update_time is not null and plainto_tsquery('driver') @@ keyword_participle
ORDER BY avg_mon_search DESC
LIMIT 500 OFFSET 0;
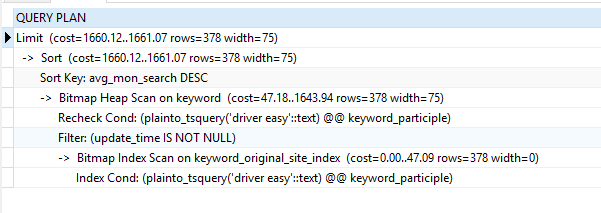
背景: keyword 表中有八千万行数据,建立了 gin( keyword_participle ) 索引,以及其他排序字段的 BTREE 索引
分析:当查询当个单词时,虽然有走全文索引,但是由于返回的结果集很大,有二十多万行数据,而且返回后需要再次进行排序,导致性能严重下降,
处理方法:限制全文索引返回的结果集行数,结果集变小了,也就减少了排序消耗的时间,况且全文索引分词返回的这么多数据,用户只是查看前面一部分,通过这种方式让用户完善搜索词,知道找到自己想要的结果。
SELECT
keyword,avg_mon_search,competition,impressions,ctr,position,suggest_bid,click,update_time, count(*) over() as res_count
FROM
(SELECT keyword,avg_mon_search,competition,impressions,ctr,position,suggest_bid,click,update_time
FROM keyword WHERE update_time is not null AND avg_mon_search > 0 AND plainto_tsquery('english_nostop', 'driver') @@ keyword_participle limit 20000
) AS tmp
ORDER BY avg_mon_search DESC
LIMIT 500 OFFSET 0;
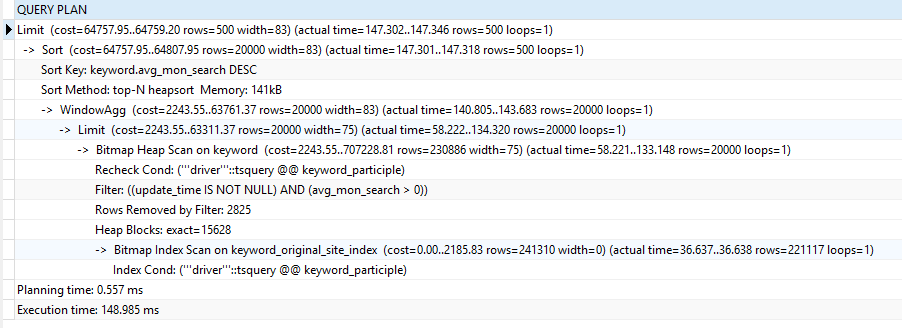
如何优化索引效率
有很多方法告诉你应该如何选择索引,但是没有提索引本身的优化,实际上数据分布会影响索引的效率。
根据索引的扫描特点,对数据进行重分布,可以大幅度优化索引查询的效率。
例如bitmap index scan(按BLOCK ID顺序读取)就是PostgreSQL用于减少离散IO的手段。
1、btree数据分布优化
线性相关越好,扫描或返回多条数据的效率越高。
2、hash数据分布优化
线性相关越好,扫描或返回多条数据的效率越高。
3、gin数据分布优化
如果是普通类型,则线性相关越好,扫描或返回多条数据的效率越高。
如果是多值类型(如数组、全文检索、TOKENs),则元素越集中(元素聚类分析,横坐标为行号,纵坐标为元素值,数据分布越集中),效率越高。
元素集中通常不好实现,但是我们可以有集中方法来聚集数据,1. 根据元素的出现频率进行排序重组,当用户搜索高频词时,扫描的块更少,减少IO放大。2. 根据(被搜索元素的次数*命中条数)的值进行排序,按排在最前的元素进行聚集,逐级聚集。
(以上方法可能比较烧脑,下次发一篇文档专门讲GIN的数据重组优化)
《索引扫描优化之 - GIN数据重组优化(按元素聚合) 想象在玩多阶魔方》
4、gist数据分布优化
如果是普通类型,则线性相关越好,扫描或返回多条数据的效率越高。
如果是空间类型,则元素越集中(例如数据按geohash连续分布),效率越高。
5、brin数据分布优化
线性相关越好,扫描或返回多条数据的效率越高。
6、多列复合索引数据分布优化
对于多列符合索引,则看索引的类型,要求与前面一样。
增加一个,多个列的线性相关性越好,性能越好。
多列线性相关性计算方法如下
《PostgreSQL 计算 任意类型 字段之间的线性相关性》
数据分布还有一个好处,对于列存储,可以大幅提升压缩比
《一个简单算法可以帮助物联网,金融 用户 节约98%的数据存储成本 (PostgreSQL,Greenplum帮你做到)》
PostgreSQL 如何优化索引效率的更多相关文章
- PostgreSQL中的索引(一)
引言 这一系列文章主要关注PostgreSQL中的索引. 可以从不同的角度考虑任何主题.我们将讨论那些使用DMBS的应用开发人员感兴趣的事项:有哪些可用的索引:为什么会有这么多不同的索引:以及如何使用 ...
- SQL SERVER全面优化-------索引有多重要?
想了好久索引的重要性应该怎么写?讲原理结构?我估计大部分人不愿意看,也不愿意花那么多时间仔细研究.光写应用?感觉不明白原理一样不会用.举例说明?情况太多也写不全....到底该怎么写呢? 随便写吧,想到 ...
- Solrj和Solr DIH索引效率对比分析
测试软件环境: 1.16G windows7 x64 32core cpu . 2.jdk 1.7 tomcat 6.x solr 4.8 数据库软件环境: 1.16G windows7 x64 ...
- postgresql 配置文件优化
postgresql 配置文件优化 配置文件 默认的配置配置文件是保存在/etc/postgresql/VERSION/main目录下的postgresql.conf文件 如果想查看参数修改是否生效, ...
- MySql基础笔记(二)Mysql语句优化---索引
Mysql语句优化--索引 一.开始优化前的准备 一)explain语句 当MySql要执行一个查询语句的时候,它首先会对语句进行语法检查,然后生成一个QEP(Query Execution Plan ...
- mysql性能优化-慢查询分析、优化索引和配置 (慢查询日志,explain,profile)
mysql性能优化-慢查询分析.优化索引和配置 (慢查询日志,explain,profile) 一.优化概述 二.查询与索引优化分析 1性能瓶颈定位 Show命令 慢查询日志 explain分析查询 ...
- PLSQL_性能优化索引Index介绍(概念)
2014-06-01 BaoXinjian
- Mysql优化-索引
1. 索引的本质 MySQL官方对索引的定义为:索引是帮助MySQL高效获取数据的数据结构. 数据库查询是数据库的最主要功能之一.我们都希望查询数据的速度尽可能的快,因此 数据库系统的设计者会从查询算 ...
- postgresql 创建gin索引
1.创建gin类型的索引 postgresql 创建gin索引遇到的问题:1.ERROR: operator class "gin_trgm_ops" does not exist ...
随机推荐
- EEC 欧姆龙PLC输入模块算法
Option Explicit Public MyArray(20000) As Integer Public MyArraySensor(20000) As Integer Sub 生成输入 ...
- 三种zigbee网络架构详解
在万物互联的背景下,zigbee网络应用越加广泛,zigbee技术具有强大的组网能力,可以形成星型.树型和网状网,三种zigbee网络结构各有优势,可以根据实际项目需要来选择合适的zigbee网络结构 ...
- 黑幕背后的Autorelease
http://blog.sunnyxx.com/2014/10/15/behind-autorelease/ 我是前言 Autorelease机制是iOS开发者管理对象内存的好伙伴,MRC中,调用[o ...
- kubernetes-控制器Deployment和DaemonSet(八)
Pod与controllers的关系 •controllers:在集群上管理和运行容器的对象•通过label-selector相关联•Pod通过控制器实现应用的运维,如伸缩,升级等 控制器又称工作负载 ...
- 破解studio 3T
方法一: 打开注册表:regedit 计算机\HKEY_CURRENT_USER\Software\JavaSoft\Prefs\3t\mongochef\enterprise 将里面得数据清零,又是 ...
- LAMP 搭建练习
目录 LAMP 搭建 1:CentOS 7, lamp (module): http + php + phpMyAdmin + wordpress 192.168.1.7 配置虚拟主机 xcache ...
- 5-3 time模块
1.取当前时间戳和当前格式化时间 import time1 # 以时间戳的形式打印当前时间 1543849862 print(int(time.time()))#时间戳 # 取当前格式化好的时间 20 ...
- 最新Python3.6从入门到高级进阶实战视频教程
点击了解更多Python课程>>> 最新Python3.6从入门到高级进阶实战视频教程 第1篇 Python入门导学 第2篇 Python环境装置 第3篇 了解什么是写代码与Pyth ...
- 懒人的mysql管理脚本
最近常用到的命令,太懒不想打太多 1,mysql启动,重启,停止脚本 echo '/usr/local/mysql5/support-files/mysql.server $1'>>/us ...
- python读取xls文件
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/10/17 14:41 # @Author : Sa.Song # @Desc ...