python内置数据结构
数据类型:
数值型
- int
- float
- complex
- bool
序列对象
- 字符串 str
- 列表 list
- 元组 tuple
键值对
- 集合 set
- 字典dict
数值型:
- int、float、complex、bool都是class,1、5.0、2+3j都是对象既实例
- int:python3的int就是长整型,且没有大小限制、受限于内存区域的大小
- float:有整数部分和小数部门组成,支持十进制和科学计数法表示,只有双精度型。
- complex:有实数和虚数部分组成,实数部分和虚数部分都是浮点型。3+4.2j
- bool:int的子类,仅有2个实例True、False对应1和0,可以和整数值直接运算
类型转换:
- int(x) 返回一个整数
- float(x) 返回一个浮点数
- complex(x)、complex(z,y) 返回一个复数
- bool(x) 返回一个布尔值,前面讲过False等价对象
数字处理函数:
import math
#向下取值,地板
print(math.floor(2.5),math.floor(-2.5))
#向上取值,天花板
print(math.ceil(2.5), math.ceil(-2.5))
#测试四舍六入五取偶
print(round(3.5), round(3.5001), round(3.6), round(3.3))
#判断类型,但会一个bool值
print(isinstance(6, str))
print(isinstance(6, (str, bool, int)))
- round(),四舍六入五取偶
- floor(),向下取整,ceil(),向上取整
- int(),取整
- // 取整且向下取整
- min() 最小值
- max() 最大值
- pow(x,y) 等于x**y
- math.sqrt() 平方函数
- bin(x) 二进制 返回值是字符串
- oct(x) 八进制 返回值是字符串
- hex(x) 十六进制 返回值是字符串
- math.pi π
- math.e 自如常数
类型判断
- type(obj) ,返回类型,而不是字符串
- isinstance(obj, class_or_tuple),返回一个bool值
序列对象
列表(list)
- 一个队列,一个排列整齐的队伍
- 列表内的个体称作元素,由若干元素组成列表
- 元素可以是任意对象(数字、字符串、对象、列表等)
- 列表内元素有顺序,可以使用索引
- 线性的数据结构
- 使用[]表示
- 列表是可变的
- 列表list、链表、queue、stack的差异
列表list定义
- list()
- list(iterable)
- 列表不能一开始定义大小
lst = list()
lst = []
lst = [2,6,9,'ab']
lst = list(range(5))
列表索引访问
- 索引、也叫下标
- 正索引:从左到右,从0开始为列表中每一个元素编号
- 负索引:从右到左,从-1开始
- 正负索引不可以超界,否则引发异常IndexError
- 为了理解方便,可以认为列表是从左到右排列的,左边是头部,右边是尾部,左边是下界,右边是上界。
- 列表通过索引访问 list[index] ,index就是索引,使用中括号访问
列表查询
index(value,[start,[stop]])
- 通过值value,从指定区间查找列表内的元素是否匹配
- 匹配第一个就立即返回索引
- 匹配不到,抛出异常ValueError
count(value)
- 返回列表中匹配value的次数
时间复杂度
- index和count方法都是O(n)
- 随着列表数据规模的增大,而效率下降
如何返回列表元素的个数?如果遍历?如何设计高效?
- len()
列表元素修改
索引访问修改
- list[index] = value
- 索引不要超界
l = [1,2,3,4,5]
l[3] = "jaxzhai"
l
列表增加、插入元素
append(object) ->None
- 列表尾部追加元素、返回None
- 返回None就意味着没有新的列表产生,就地修改
- 时间复杂度是O(1)
insert(index,object) -> None
- 在指定的索引index处插入元素object
- 返回None就意味着没有新的列表产生,就地修改
- 时间复杂度是O(n)
- 索引能超越上下界吗?
- 超越上界,尾部追加
- 超越下界,头部追加
extend(iteratable) -> None
- 将可迭代对象的元素追加进来,返回None
- 就地修改
+ -> list
- 连接操作,将两个列表连接起来
- 产生新的列表,源列表不变
- 本质上调用的是_add_()方法
* -> list
- 重复操作,将本列表元素重复N次,返回新的列表
列表删除元素
remove(value) -> None
- 从左至右查找第一个匹配value的值,移除该元素,返回None
- 就地修改
- 效率慢(因为要查找这个值, 如果这个值是最后一个值,这时候已经遍历了一遍列表了)
pop([index]) -> item
- 不指定索引index,就从列表尾部弹出一个元素
- 指定索引index,就从索引处弹出一个元素,索引超界抛出IndexError错误
- 效率?不指定索引的话效率会高,指定索引的话效率会低
clear() -> None
- 清除列表所有元素,剩下一个空列表
列表其它操作
reverse() -> None
- 将列表元素反转,返回None
- 就地修改
sort(key=None,reverse=False) -> None
- 对列表元素进行排序,就地修改,默认升序
- reverse为True,反转,降序
- key一个函数,指定key如何排序
in
- [3,4] in [1,2,[3,4]]
- for x in [1,2,3,4]
列表复制
lst0 = list(range(4))
lst2 = list(range(4))
print(lst0==lst2)
lst1 = lst0
lst1[2] = 10
print(lst0)
- lst0和lst2的内容是相等,内存地址不同。
- lst1和lst0的内容相等,内地地址也相同
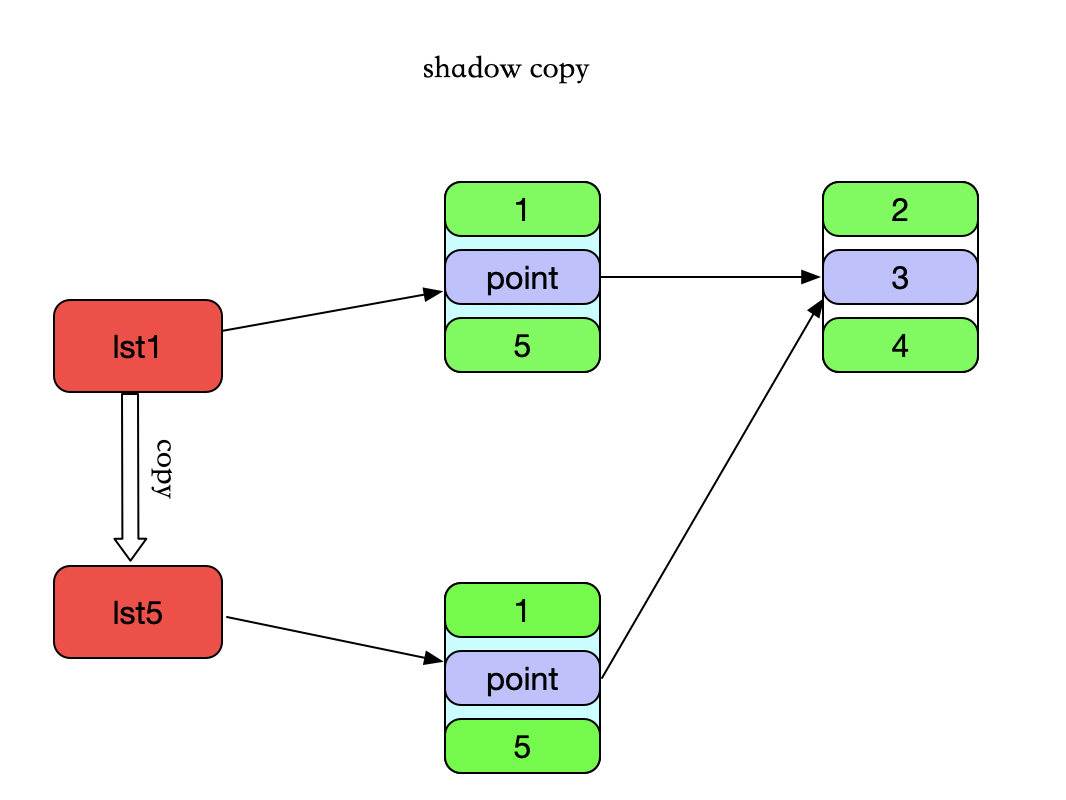
copy() -> list
- shadow copy(浅拷贝)一个新的列表
浅拷贝
- 影子拷贝,遇到引用类型,只是复制一个引用而已。(例如列表,字典等。既引用同样的内存地址)
深拷贝
- copy模块提交了deepcopy

import copy
lst0 = [1, [2, 3, 4], 5]
lst5 = copy.deepcopy(lst0)
lst5[1][1] = 20
lst5 == lst0 这个执行结果就是False
随机数
random模块
- randint(a,b) 返回[a,b]之间的整数
- choice(seq) 从非空的元素序列中随机挑选一个元素,例如:random.choice(range(10)),从0到9中随机挑选一个整数。
- randrange([start],stop,[step])从指定范围内,按指定基数递增的集合中获取一个随机数,基数缺省值为1。random.randrange(1,7,2)
- random.shuffle(lsit) -> None 就地打乱列表顺序。
- sample(population,k)从样本中随机取出k个不同的元素,返回一个新列表。
python内置数据结构的更多相关文章
- Python内置数据结构之列表list
1. Python的数据类型简介 数据结构是以某种方式(如通过编号)组合起来的数据元素(如数.字符乃至其他数据结构)集合.在Python中,最基本的数据结构为序列(sequence). Python内 ...
- Python内置数据结构--列表
本节内容: 列表 元组 字符串 集合 字典 本节先介绍列表. 一.列表 一种容器类型.列表可以包含任何种类的对象,比如说数字.子串.嵌套其他列表.嵌套元组. 任意对象的有序集合,通过索引访问其中的元素 ...
- Python内置数据结构之字符串str
1. 数据结构回顾 所有标准序列操作(索引.切片.乘法.成员资格检查.长度.最小值和最大值)都适用于字符串,但是字符串是不可变序列,因此所有的元素赋值和切片赋值都是非法的. >>> ...
- Python内置数据结构之元组tuple
1. Python序列之元组:不可修改的序列 元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能像列表式的增删改,只能查,切片,所以元组又叫只读列表. 元组用圆括号括起(这是通常采用的做法) ...
- Python内置数据结构之字典dict
1. 字典 字典是Python中唯一的内置映射类型,其中的值不按顺序排列,而是存储在键下.键可能是数(整数索引).字符串或元组.字典(日常生活中的字典和Python字典)旨在让你能够轻松地找到特定的单 ...
- python内置数据结构方法的时间复杂度
转载自:http://www.orangecube.net/python-time-complexity 本文翻译自Python Wiki 本文基于GPL v2协议,转载请保留此协议. 本页面涵盖了P ...
- python 内置数据结构 切片
切片 通过索引区间访问线性结构的一段数据 sequence[start:stop] 表示返回[start,stop]区间的子序列 支持负索引 start为0,可以省略 stop为末尾,可以省略 超过上 ...
- python 内置数据结构 字符串
字符串 一个个字符组成的有序的序列,是字符的集合 使用单引号,双引号,三引号引住的字符序列 字符串是不可变对象 Python3起,字符串就是Unicode类型 字符串定义 初始化 s1 = 'stri ...
- Python第五章-内置数据结构05-集合
Python内置数据结构 五.集合(set) python 还提供了另外一种数据类型:set. set用于包含一组无序的不重复对象.所以set中的元素有点像dict的key.这是set与 list的最 ...
随机推荐
- PHP 调用 exec 执行中文命令的坑
服务器系统Linux通过php exec 执行rar x 解压命令 保持目录结构,压缩包内英文目录正常解压中文目录解压失败,请问有什么办法可以解决直接在终端命令进行解压是没有问题的 最终解决办法 $s ...
- Gradle 的使用
gradle 工具类似于maven工具,但是gradle 减少了maven中的那种使用xml 中大量的配置文件来下载依赖的jar包.而gradle大大简化了,能够很快速的添加依赖.具体关于gradle ...
- 单元测试框架之unittest(七)
一.摘要 前篇文章已经详细介绍了unittest框架的特性,足以满足我们日常的测试工作,但那并不是unittest的全部,本片博文将介绍一些应该知道但未必能经常用到的内容 然而,想全部掌握unitte ...
- docker换源
方案一 修改或新增 /etc/docker/daemon.json # vi /etc/docker/daemon.json { "registry-mirrors": [&quo ...
- FFmpeg常用命令学习笔记(六)图片与视频互转命令
图片与视频互转命令 1.视频转图片 ffmpeg -i in.mp4 -r 1 -f image2 img-%3d.jpeg -r 1:转换图片帧率为1,也就是1秒转1张.-f image2:将媒体文 ...
- gRPC 到 JSON 代理生成器 grpc-gateway
grpc-gateway是protoc的插件,它读取protobuf服务定义并生成反向代理服务器,该服务将RESTful HTTP API转换为gRPC. 这个服务是根据你的服务定义中的google. ...
- CF46F Hercule Poirot Problem
题意: 有n个房间和m扇门,每扇门有且仅有一把钥匙 有k个人度过了两天,在第一天开始的时候所有的门都是关闭的,在第二天结束的时候,所有的门也都是关闭的 在这两天内,每个人可以执行如下操作若干次: 关上 ...
- idea快捷方式2
IntelliJ Idea 常用快捷键列表 Ctrl+Shift + Enter,语句完成“!”,否定完成,输入表达式时按 “!”键Ctrl+E,最近的文件Ctrl+Shift+E,最近更改的文件Sh ...
- Appium获取toast消息
Android获取toast,需要在参数里设置automationName:Uiautomator2 设置设备的信息 desired_caps = { 'platformName': 'Android ...
- 什么是CSR
CSR的全称是Certificate Signing Request. 是我们在申请Https证书是向CA所提供的一杯申请书.其内部储存了我们申请证书所需要的基本信息.它是一个经过Base64编码的纯 ...