[论文理解] Acquisition of Localization Confidence for Accurate Object Detection
Acquisition of Localization Confidence for Accurate Object Detection
Intro
目标检测领域的问题有很多,本文的作者捕捉到了这样一个问题,就是nms算法根据类别置信度为准则去删掉与他iou大于一定阈值的算法是否合理?事实是,分类置信度没法评估回归框是否回归的准确,这就造成了一种情况,分类置信度高的不一定回归的准,那么回归的准的又因为与之iou更高而被剔除了。为什么回归的准的反而类别置信度可能不高,而类别置信度高的可能回归的不准呢?本文一一给出了解答,并提出了IOUNet作为解决方案。
先验知识
NMS算法
参见该博客:https://www.cnblogs.com/king-lps/p/9031568.html
NMS是一个比较基础的东西,貌似面试的时候也经常要写NMS。
回归方式
一般有两种回归方式
- 直接回归坐标,端到端
- 根据预定于的Anchor去回归偏移量
此外,回归的的具体值也有很多不同的做法。
- 回归x、y、w、h,也就是回归中心点的坐标和框的宽高。
- 回归x1、y1、x2、y2,也就是直接回归左上角的点和右下角的点。
- 回归dl、dr、du、db,根据anchor去回归anchor中心到各个边的offset。
4.回归Ox、Oy、w、h,回归距离anchor的中心offset和宽高。
其中,一般会对回归的值进行缩放,使得回归的结果更容易学习。
比如x1/w,y1/h,x2/w,y2/h等等
对于宽高一般回归logw和logh。
一般认为通过学习平移缩放这样的线性变换能够使得回归出来的框更加接近真实结果。具体解释见:
https://www.jianshu.com/p/2c0995908cc3
问题
Misaligned classification and localization accuracy

由上面的直观的图我们可以看出,类别置信度其实是不能作为先决条件来排除回归框的,因为类别置信度高的框不一定标的是准的。
显然这么一两张图还是没办法说明这个问题,所以只有下面这张图才能很清楚的说明类别置信度是否能作为回归框的标准。

横轴是iou,纵轴是cls score,从图中可以看出,iou其实与cls score并不是一个线性关系,有很多点其实并没有分布在中间,这说明,尽管cls score的值有很多点是比较大的但是其iou并不是很大的,如图有很多cls score接近1的点的iou却只有0.6-0.8,所以,cls score其实并不能衡量框的准确。此外,cls score和iou的相关系数只有0.217,而使用本文的方法相关系数和达到0.617。
因而,作者认为可以直接设计一种结构来让网络学习到iou的值,即给定一张图,通过RPN得到ROI,然后将ROI输入网络,输出IOU的值,然后用得到的IOU去引导NMS,而非使用cls score去引导。
Non-monotinic bounding box regression
简单来说就是,回归的效果不一定越学学好。
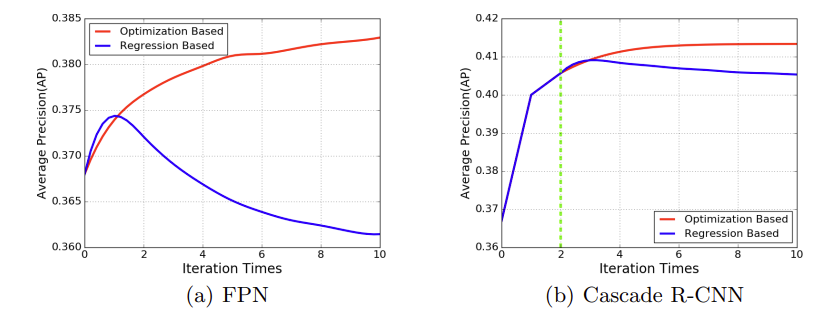
通过这张图可以看出,通过简单的回归方法学习出来的结果,随着迭代次数的增加,其AP并不一定是增加的,而是先上升再下降的,所以,这种回归方式也有弊端。
而本文提出的Optimization Based 回归方式就能很好的改善这个问题。
Roi Pooling

通常二阶段网络都需要这么一个结构,将proposal的坐标映射成feature map的区域,然后对区域进行pooling,得到size固定的输出feature map。
通常情况下有上图中的Roi Pooling和Roi Align两种方式。本文所描述的都是avg pooling过程。
前者先对隐射到feature map的坐标进行量化,然后所有点取均值,这很显然带来了量化误差。
后者为了解决量化误差,提出了Roi Align,坐标映射完之后,使用双线性插值,得到最终的点,然后对插值后的点求平均。但是结果永远是对4个点进行平均,没法表达Roi的尺度。
本文提出了PrRoi Pooling的方案,后面会详细讨论。
解决
PrRoIPooling
第一步将坐标连续化,一张图每个点的坐标都是离散化的,而我们第一步就是将坐标连续化:
\[
f(x,y) = \sum_{i,j}IC(x,y,i,j) \times w_{i,j}
\]
这里IC是插值
\[
IC(x,y,i,j) = max(0,1-|x-i|)\times max(0,1-|y-i|)
\]
所以一张图上任意连续点都有值了。
然后就是Prpool的公式:
\[
PrPool(bin,F) = \frac{\int_{y_1}^{y_2}\int_{x_1}^{x_2}f(x,y)dxdy}{(x_2 - x_1)(y_2 - y_1)}
\]
可以看到就是对区域内所有点求均值。
IoU-Net
网络结构如图所示:
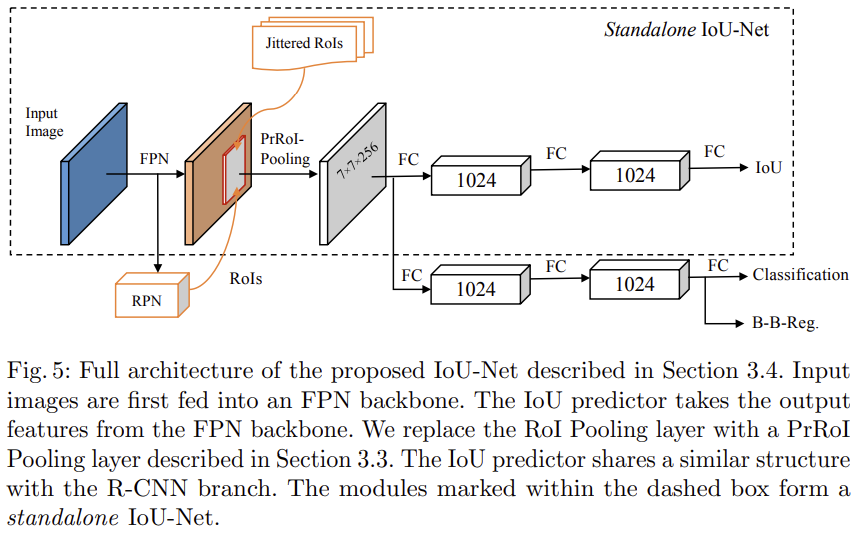
整个画黑框的部分就是IoUNet的主体,输入的图片通过RPN得到region proposal,然后使用本文提出的PrRoIPoolin池化到一个feature map,然后网络去预测iou。
这一部分的训练其实是单独的,也就是说,学习iou的训练并不是和学习cls score、bbox reg一起的,而是作者通过随机去通过gt构建偏移的框,去训练学习iou。
然后训练完成之后这一部分应该就不动了,然后再去单独训练cls 和 reg。
上面的工作都完成之后,网络就能输入一张图片,得到iou、cls score和reg的四个坐标了。
Bounding box refinement as an optimization procedure
上面说啦,回归的效果不一定越学越好,于是就要针对回归方式进行改进。
IoUNet是直接优化Iou(Box_det,Box_gt)的,使用梯度提升来最大化IoU。
算法流程如下:

第三行算的是IoU关于bj的四个梯度,然后在第6行里,之所以要scale一下grad,是因为想要不同axis的学习率不一样,比如对于x方向,这个方向的梯度就乘以w,对于y方向,这个方向的梯度就乘以h。这跟直接优化x/w和y/h是一样的。
直接利用了IoU来优化refine部分,这部分训练是端到端的。
IoU guided NMS
最后呢,网络输出的框还是要经过去重,前面说了传统nms的缺点,所以学了IoU自然要自用IoU来执行NMS,称之为IoU guided NMS。
算法流程如图:

也是比较容易理解的一部分吧。
流程梳理
经过修改,整个网络运行的过程就变成了:
- 单独训练IoU Net,使得网络输入一张ROI图就能得到其与gt的IoU。
- 单独训练RPN。
- 训练分类和回归网络,使用本文提出的优化方法对bbox位置进行优化。
- 使用iou guided nms对预测的框进行去重,保留最终结果并输出。
[论文理解] Acquisition of Localization Confidence for Accurate Object Detection的更多相关文章
- Acquistion Location Confidence for accurate object detection
Acquistion Location Confidence for accurate object detection 本论文主要是解决一下两个问题: 1.分类得分高的预测框与IOU不匹配,(我猜应 ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 目标检测论文解读1——Rich feature hierarchies for accurate object detection and semantic segmentation
背景 在2012 Imagenet LSVRC比赛中,Alexnet以15.3%的top-5 错误率轻松拔得头筹(第二名top-5错误率为26.2%).由此,ConvNet的潜力受到广泛认可,一炮而红 ...
- [论文理解] An Analysis of Scale Invariance in Object Detection – SNIP
An Analysis of Scale Invariance in Object Detection – SNIP 简介 小目标问题一直是目标检测领域一个比较难解决的问题,因为小目标提供的信息比较少 ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- [论文理解]Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
Region-Based Convolutional Networks for Accurate Object Detection and Segmentation 概括 这是一篇2016年的目标检测 ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- 2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick Jeff ...
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
随机推荐
- css,使两个在同一行内的display:inline-block的div顶部对齐。
两个都加上:vertical-align:top;
- 第四篇.python的基础
目录 第四篇.python基础01 1. 变量 2. 常量 3. python变量内存管理 4. 变量的三个特征 5. 花式赋值 6. 注释 7. 数据类型基础 8. 数字类型 9. 字符串类型 10 ...
- 基于Dockerfile搭建JAVA Tomcat运行环境
前言 在第一篇文字中,我们完全人工方式,一个命令一个命令输入,实现一个java tomcat运行环境,虽然也初见成效,但很累人.如果依靠依靠脚本构建一个Tomcat容器实例,一个命令可以搞定,何乐而不 ...
- Delphi DLL文件的静态调用
- Excutor线程池
文章:Java并发(基础知识)—— Executor框架及线程池 待完善……
- ios系统保存校园网密码
相信ios用户每次登陆时无法保存必须要重新输入账号密码的问题困扰了很多同学,特别是苹果5用户(不要问为什么,屏幕本来就小) 现在我们就一起想办法来解决它吧! 首先,我们进入设置->Safari浏 ...
- BZOJ 1008 组合数学
监狱有连续编号为1...N的N个房间,每个房间关押一个犯人,有M种宗教,每个犯人可能信仰其中一种.如果相邻房间的犯人的宗教相同,就可能发生越狱,求有多少种状态可能发生越狱 总的情况为mn不越狱的情况为 ...
- string::append
string (1) string& append (const string& str); substring (2) string& append (const strin ...
- 第六章 组件 55 组件-使用components定义私有组件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8&quo ...
- 通过CSS实现 文字渐变色 的两种方式
说明 这次的重点就在于两个属性, background 属性 mask 属性这两个属性分别是两种实现方式的关键. 方式一 解释 <!DOCTYPE html> <html> & ...