网页为什么会乱码?浅析字符集编码ASCII和Unicode
因为编码不对!
什么是编码?编码不对为什么会乱码?
……??
编码转换为什么会丢失数据?
……??
不管是数据库还是网页,都可能碰到过乱码问题

在计算机世界里,所有数据都使用二进制存储,即只有1和0,在人的世界里有中文/英文/阿拉伯文等,还有图片/视频/音频,如何使用二进制存储和显示它们呢?具体使用哪些二进制字符表示哪个符号的这样一种规则就叫编码。编码充当着一个翻译的角色,计算机是美国人发明的,为了存储他们使用的语言abcd等26个英文字母以及常用的符号~!@#¥%……&*()-+,美国有关标准化组织出台了ASCII编码,但是,ASCII编码是单字节编码系统,最多只能表示256个字符,因此ASCII只适用于拉丁文字子母,而其他国家有各种各样的语言文字,比如中文字符有好几万个,于是有了GB2312双子节编码。
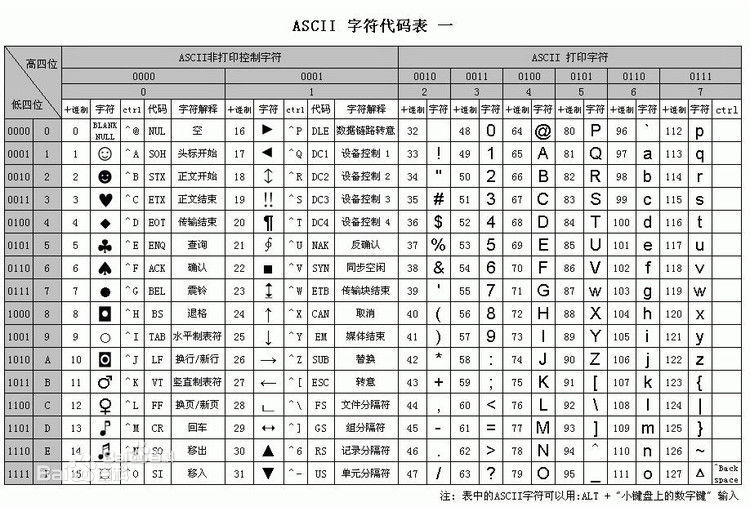
GB2312适用于汉字处理、汉字通信等系统之间的信息交换,GB2312共收录6763个常用中文和非汉字图形字符682个,由中国国家标准总局于1980年发布,随着汉字标准的发展,GB2312收录的6千多字明显不够用了,1995年又发布了GBK编码,GBK是GB2312的扩展,向下兼容GB2312编码,GBK编码共收录了21003个汉字。
观察ASCII会发现,ASCII编码只能表示寥寥256个字符,而GB2312共收录6千多个字符,假如想用ASCII编码来表示六千多个中文,很明显ASCII里面并没有与中文对应的映射关系,所以就显示乱码了。
每个国家都有自己相应的编码规则,为了解决编码不统一的问题,Unicode编码方案应运而生。Unicode也叫统一码或万国码,它是计算机科学领域里的一项业界标准,Unicode把所有语言都统一到一套编码里,以满足跨语言、跨平台进行文本转换、处理的要求,这样就不会再有乱码问题了,它于1994年正式公布。UTF8就是Unicode编码方案的一种。
UTF8的长度是1-4位(最初是1-6位),GB2312长度是2位,一个长度为3位的UTF8字符转换成GB2312就会丢失信息,显示乱码,再转换回UTF8也无济于事,因为信息已经丢失。这就是我们有时候在转换编码的时候乱码的原因。
作者:王美建
出处:http://www.cnblogs.com/wangmeijian
本文版权归作者和博客园所有,欢迎转载,转载请标明出处。
如果您觉得本篇博文对您有所收获,请点击右下角的 [推荐],谢谢!
网页为什么会乱码?浅析字符集编码ASCII和Unicode的更多相关文章
- 2.数码相框-编码(ASCII/GB2312/Unicode)介绍,并使LCD显示汉字字符(2)
在上章-学习了数码相框的框架分析(1)了 本章主要内容如下: 1)熟悉ASCII/GB2312/Unicode编码 2)写应用程序,使LCD显示汉字和字符 大家都知道,数据传输的是二进制,而字符和汉字 ...
- 编码 ASCII, GBK, Unicode+utf-8
0. 1.参考 网页编码就是那点事 阮一峰 字符编码笔记:ASCII,Unicode 和 UTF-8 2.总结 美国 ASCII 码 发音: /ˈæski/ :128个字符,只占用了一个字节的后面7位 ...
- 字符编码 ASCII、Unicode和UTF-8的关系
摘抄自廖雪峰 教程 字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机 ...
- Java 字符编码 ASCII、Unicode、UTF-8、代码点和代码单元
1 ASCII码 统一规定英语字符与二进制位之间的关系.ASCII码一共规定了128个字符的编码.例如,空格“SPACE”是32(二进制00100000),大写字母A是65(二进制01000001). ...
- 2.数码相框-编码(ASCII/GB2312/Unicode)介绍
转载:https://www.cnblogs.com/lifexy/p/8485634.html 在上章-学习了数码相框的框架分析(1)了 本章主要内容如下: 1)熟悉ASCII/GB2312/Uni ...
- 【基础】字符编码-ASCII、Unicode、utf-8
一.各自背景 1. ASCII ASCII 只有127个字符,表示英文字母的大小写.数字和一些符号.但由于其他语言用ASCII编码表示字节不够,例如:常用中文需要两个字节,且不能和ASCII冲突,中国 ...
- 字符编码(ASCII,Unicode和UTF-8) 和 大小端
本文包括2部分内容:“ASCII,Unicode和UTF-8” 和 “Big Endian和Little Endian”. 第1部分 ASCII,Unicode和UTF-8 介绍 1. ASCII码 ...
- 字符编码(ASCII,Unicode和UTF-8) 和 大小端(zz)
本文包括2部分内容:“ASCII,Unicode和UTF-8” 和 “Big Endian和Little Endian”. 第1部分 ASCII,Unicode和UTF-8 介绍 1. ASCII码 ...
- 字符编码ASCII、Unicode、GB
计算机的存储都是二进制的,那么我们平时看到的各种字符都需要通过按照一定的格式转换成为二进制才能在被计算机识别与处理.这个过程便成为编码.常见的编码方式有ASCII.Unicode.GB2312等. 1 ...
随机推荐
- 重载new和delete运算符
内存管理运算符 new.new[].delete 和 delete[] 也可以进行重载,其重载形式既可以是类的成员函数,也可以是全局函数.一般情况下,内建的内存管理运算符就够用了,只有在需要自己管理内 ...
- DOM Composition 事件
做实时的表单表单校验时,如果输入的是非拉丁语言,那你可能会遇到下面的问题: 如上图所示,文本框不允许输入 ' 之类的特殊字符,当用户在敲击拼音.还未最终输入时就已经触发了校验,提示输入不合法,有点尴尬 ...
- STL备忘
STL备忘 lower_bound 查找第一个大于或等于的数,返回该数字的地址,地址减去首地址即得到数组下标(首地址下标为0) upper_bound 查找第一个大于的数 unique 去重,常用于离 ...
- TensorFlow(五):手写数字识别加强版
# 该版本的最终识别准确率达到98%以上 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_d ...
- 带着历史提交记录迁移git仓库
1. git push --mirror --mirror模式会把本地的分支都克隆 // 先用--bare克隆裸仓库 git clone git@gitee.com:zhangamie/testApp ...
- Redis批量删除缓存数据
背景: 在使用redis中,经常会遇到批量删除缓存的情况,但是对于在客户端中,如果一个一个的删除key,则需要较长时间及相对麻烦,可以使用以下命令,批量删除缓存. 本地批量删除KEY: ./redis ...
- MongoDB下载不了的问题
官网上,mongoDB数据库下载不了,搜了半天,在知乎上找到答案:在MongoDB download center中选择community-server,拖到底部有一个all versions bin ...
- TripleDES加解密Java、C#、php
TripleDES说明: TripleDES(3Des)和Des都是对称加密算法,TripleDes是Des加密算法的增强版本,这里主要说的是TripleDes加密算法的应用. 工作中 ...
- Flutter移动电商实战 --(52)购物车_数据模型建立和Provide修改
根据json数据生成模型类 {"goodsId":"2171c20d77c340729d5d7ebc2039c08d","goodsName" ...
- cv相关博客文章
收藏些图像处理,机器学习,深度学习方面比较不错的文章,时常学习,复习和膜拜吧... 图像方面(传统CV): 1. SIFT特征 https://www.cnblogs.com/wangguchangq ...