BP原理 - 前向计算与反向传播实例
Outline
很多事情不是需要聪明一点,而是需要耐心一点,踏下心来认真看真的很简单的。
假设有这样一个网络层:

第一层是输入层,包含两个神经元i1 i2和截距b1;
第二层是隐含层,包含两个神经元h1 h2和截距b2,
第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数默认为sigmoid函数。
赋初值为:
输入数据 i1=0.05,i2=0.10;
输出数据 o1=0.01, o2=0.99;
初始权重 w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w5=0.40,w6=0.45,w7=0.50,w8=0.55
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
Step 1 前向计算
1. 输入层—>隐含层:
计算神经元h1的输入加权和:

神经元h1的输出o1:(此处用到激活函数为sigmoid函数):

同理,可计算出神经元h2的输出o2:

2. 隐含层—>输出层:
计算输出层神经元o1的值:

同理,计算o2:
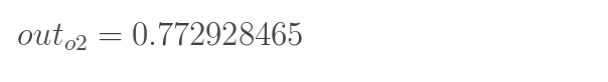
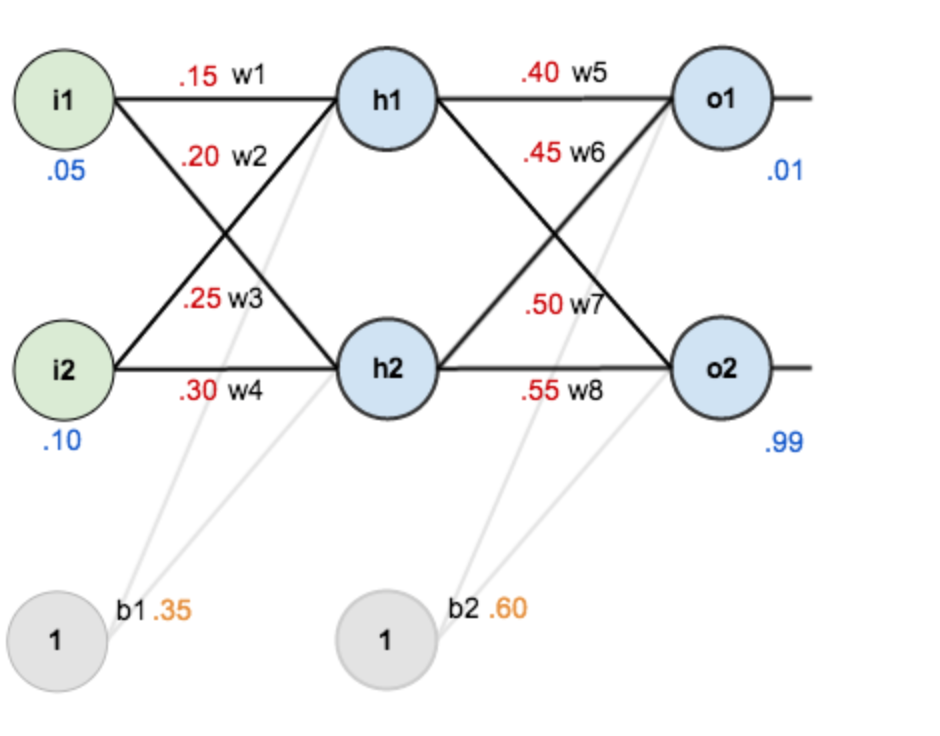
前向计算过程结束,得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差很远,对误差进行反向传播,更新权值,重新计算输出。
Step 2 反向传播
1. 计算总误差
总误差:(square error)
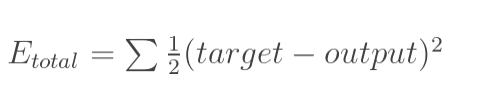
分别计算o1和o2的误差,总误差为两者之和:


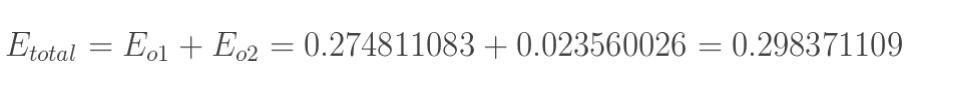
2. 输出层—>隐含层的权值更新
以权重参数w5为例,如果想知道w5对整体误差产生了多少影响,用整体误差对w5求偏导求出:(链式法则)

如图所示:

现在分别计算每个式子的值: loss--Sigmoid--weight
计算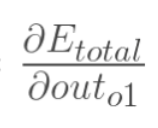 :
:

计算下一步之前,先来看一下Sigmoid函数求导:
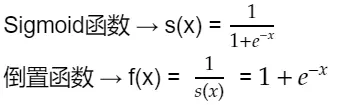
根据倒数法则从f(x)开始推导得出:
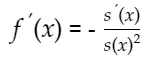

有以上两个式子可推出:
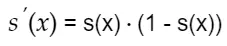
计算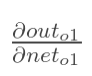 :
:

计算 :
:
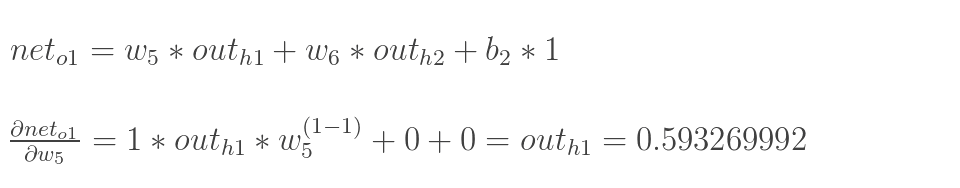
最后三者相乘:

这样我们就计算出整体误差E(total)对w5的偏导值。
综合以上四步计算过程可得:

为了表达方便,用 来表示输出层的误差:
来表示输出层的误差:

因此,整体误差E(total)对w5的偏导公式可以写成:

如果输出层误差计为负的话,也可以写成:

最后,更新w5的值,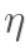 是学习速率,这里设为0.5:
是学习速率,这里设为0.5:
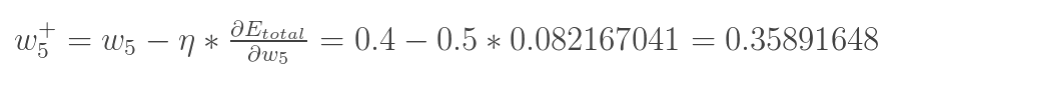
同理,可更新w6,w7,w8:

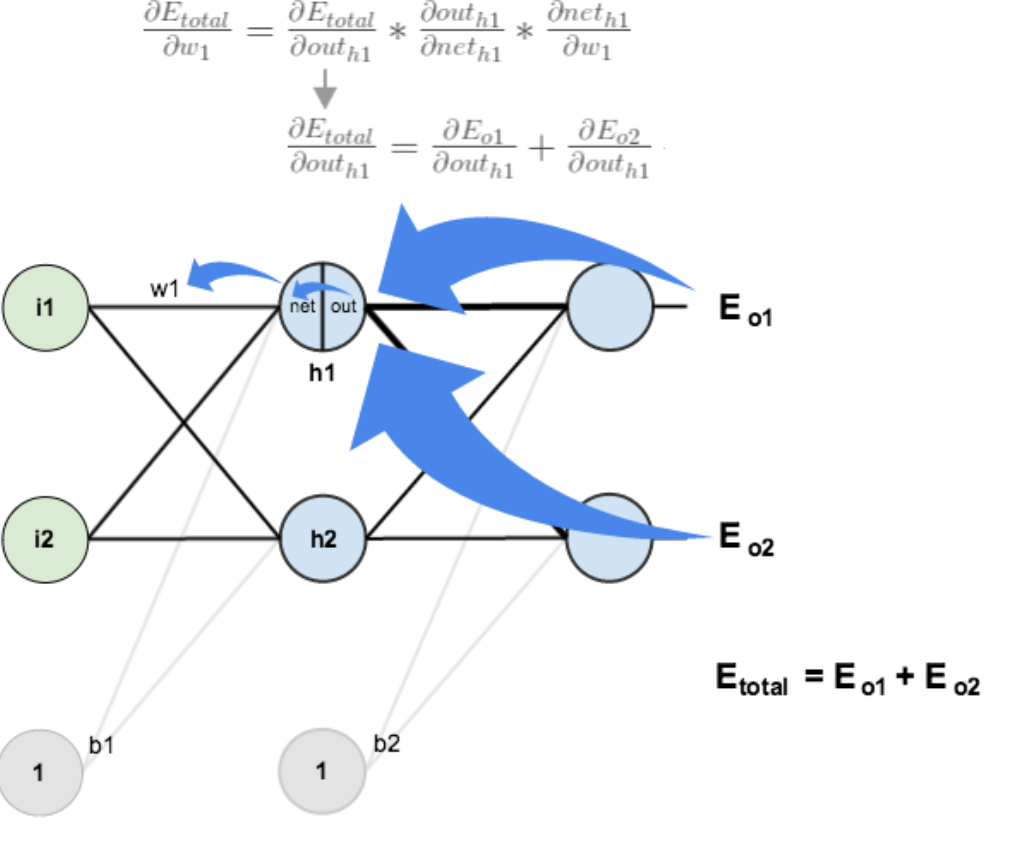
3. 隐含层—>输入层的权值更新
上一部分传播过程为:out(o1)—>net(o1)—>w5;
此处:out(h1)—>net(h1)—>w1,注意out(h1)会接受E(o1)和E(o2)两个地方传来的误差,两个都要计算。
计算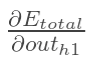 :
:

先计算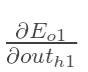 :
:
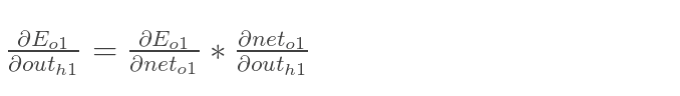

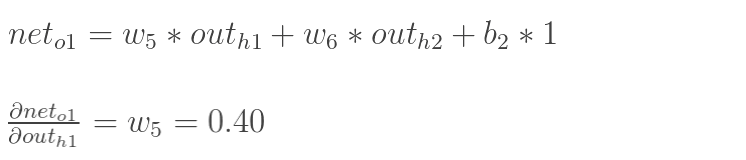
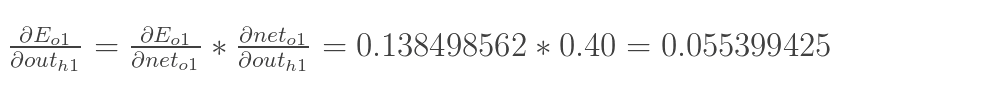
同理,计算出:
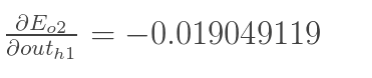
两者相加得到总值:
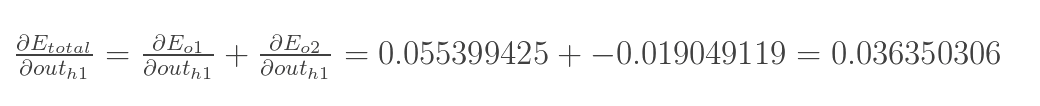
再计算 :
:

再计算 :
:

最后,三者相乘:

为了简化公式,用sigma(h1)表示隐含层单元h1的误差:

最后,更新w1的权值:

同理,额可更新w2,w3,w4的权值:

一次误差的反向传播完成,之后再把更新的权值重新计算,得到新的误差,该例中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734](原输入为[0.01,0.99])。
BP原理 - 前向计算与反向传播实例的更多相关文章
- 实现属于自己的TensorFlow(二) - 梯度计算与反向传播
前言 上一篇中介绍了计算图以及前向传播的实现,本文中将主要介绍对于模型优化非常重要的反向传播算法以及反向传播算法中梯度计算的实现.因为在计算梯度的时候需要涉及到矩阵梯度的计算,本文针对几种常用操作的梯 ...
- pytorch中的前项计算和反向传播
前项计算1 import torch # (3*(x+2)^2)/4 #grad_fn 保留计算的过程 x = torch.ones([2,2],requires_grad=True) print(x ...
- [图解tensorflow源码] MatMul 矩阵乘积运算 (前向计算,反向梯度计算)
- [tensorflow源码分析] Conv2d卷积运算 (前向计算,反向梯度计算)
- 深度学习与CV教程(4) | 神经网络与反向传播
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- BP(back propagation)反向传播
转自:http://www.zhihu.com/question/27239198/answer/89853077 机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定 ...
- 再谈反向传播(Back Propagation)
此前写过一篇<BP算法基本原理推导----<机器学习>笔记>,但是感觉满纸公式,而且没有讲到BP算法的精妙之处,所以找了一些资料,加上自己的理解,再来谈一下BP.如有什么疏漏或 ...
- cs231n(三) 误差反向传播
摘要 本节将对反向传播进行直观的理解.反向传播是利用链式法则递归计算表达式的梯度的方法.理解反向传播过程及其精妙之处,对于理解.实现.设计和调试神经网络非常关键.反向求导的核心问题是:给定函数 $f( ...
- CS231n课程笔记翻译5:反向传播笔记
译者注:本文智能单元首发,译自斯坦福CS231n课程笔记Backprop Note,课程教师Andrej Karpathy授权翻译.本篇教程由杜客翻译完成,堃堃和巩子嘉进行校对修改.译文含公式和代码, ...
随机推荐
- SQL Server 删除日志文件
-- 查询日志文件名,用于下面删除 USE [data_name] GO SELECT file_id, name FROM sys.database_files /*删除指定数据库的日志文件*/ U ...
- 51 Nod 1072 威佐夫游戏
https://baike.baidu.com/item/%E5%A8%81%E4%BD%90%E5%A4%AB%E5%8D%9A%E5%BC%88/19858256?fr=aladdin&f ...
- 第03组 Alpha冲刺(4/4)
队名:不等式方程组 组长博客 作业博客 团队项目进度 组员一:张逸杰(组长) 过去两天完成的任务: 文字/口头描述: 制定了初步的项目计划,并开始学习一些推荐.搜索类算法 GitHub签入纪录: 暂无 ...
- CUDA-F-1-1-异构计算-CUDA
开篇废话 成熟与智慧其实和年龄相关,但绝不是完全由年龄决定,少年老成的人肯定是存在的,不是长得老,而是心态成熟,当然大多数老年人其实有些事情思考起来还是老原则,所以他们有时候做事没那么周到,所以一个人 ...
- 灰度图像--图像增强 直方图匹配(规定化)Histogram Specification
学习DIP第39天 转载请标明本文出处:http://blog.csdn.net/tonyshengtan,欢迎大家转载,发现博客被某些论坛转载后,图像无法正常显示,无法正常表达本人观点,对此表示很不 ...
- IDEA如何将写好的java类(UDF函数)打成jar包上传linux
一.编写一个UDF函数,实现将字符串大写转小写 import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; ...
- Java并发编程(十一)——原子操作CAS
一.原子操作 syn基于阻塞的锁的机制,1.被阻塞的线程优先级很高,2.拿到锁的线程一直不释放锁怎么办?3.大量的竞争,消耗cpu,同时带来死锁或者其他安全. CAS的原理 CAS(Compare A ...
- win10专业版安装docker实战
在win10专业版上安装docker 一,下载Docker for Windows Installer.exe 二,在程序面板---程序----程序和功能中找到启动或关闭windows功能,将hype ...
- uni-app 尺寸单位
uni-app 支持的通用 css 单位包括 px.rpx px 即屏幕像素 rpx 即响应式px,一种根据屏幕宽度自适应的动态单位.以750宽的屏幕为基准,750rpx恰好为屏幕宽度.屏幕变宽,rp ...
- MemoScope.Net
What is MemoScope.Net ? It's a tool to analyze .Net process memory: it can dump an application's mem ...