Mysql 集群环境搭建
在上一篇文章中已经详细的写了关于Mysql的安装步骤。这一篇文章在上一篇文章的基础之上接着写集群的安装与部署。
安装地址:https://www.cnblogs.com/ming-blogs/p/10962554.html
MySQL主从复制配置
主节点服务器 地址 192.168.0.105
从节点服务器 地址 192.168.0.107
主节点服务器安装好之后,直接clone 一个即可,不需要重复安装2次。
主节点服务器配置
1.进入配置页面命令
vi /etc/my.cnf
2.配置服务器id server_id
这里的server_id 尽量配置为服务器地址的后3位 以用来区分
server_id=105
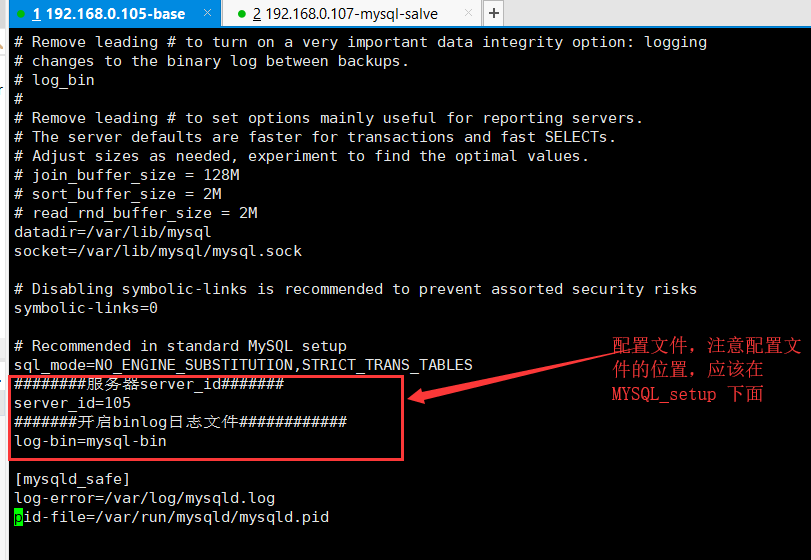
3.开启日志文件(binLog)
log-bin=mysql-bin
配置文件的地址应该在 : # Recommended in standard MySQL setup,否则配置不起作用
如下图所示
4.重启mysql服务
service mysqld restart
验证是否已经配置成功
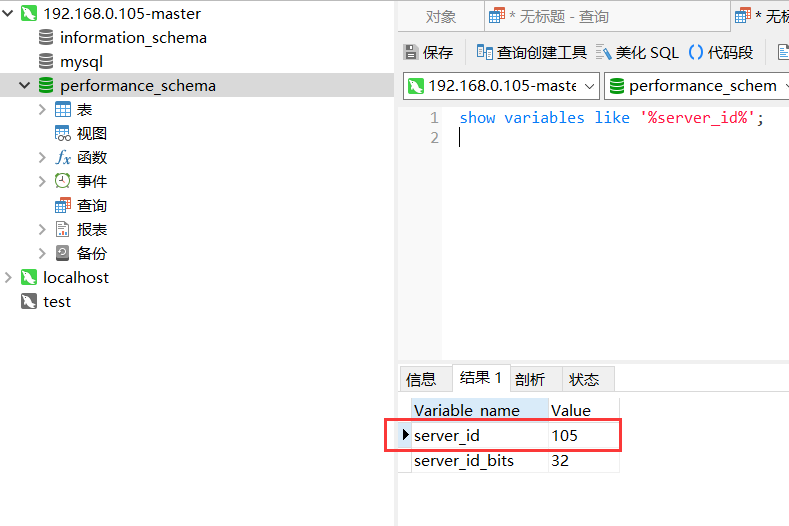
5.show variables like '%server_id%';
能够查询对应配置文件中的server_id 说明已经配置成功,如下图,则表示配置成功。server_id=105
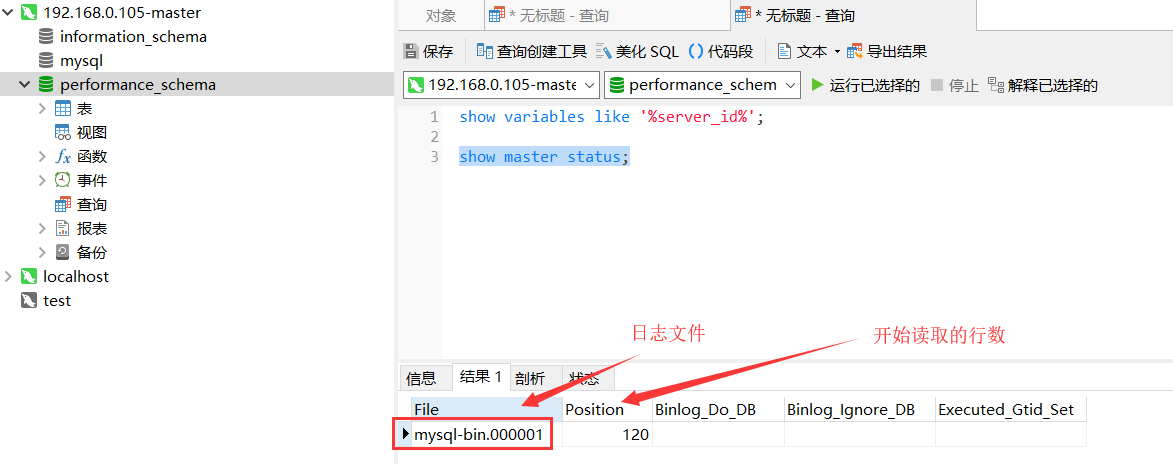
6.show master status;
能够看到同步的文件,和行数说明已经配置成功。
从服务器节点
1.进入配置页面命令
vi /etc/my.cnf
2.配置服务器id server_id
这里的server_id 尽量配置为服务器地址的后3位 以用来区分
server_id=105
3.开启日志文件(binLog)
log-bin=mysql-bin
4.添加需用同步的数据库
binlog_do_db=test
5.重启mysql服务
service mysqld restart
验证是否已经配置成功
6.show variables like '%server_id%';
能够查询对应配置文件中的server_id 说明已经配置成功

7.从服务器同步主服务器配置
master_host 主服务器地址
master_user 主服务器用户名
master_password 主服务器密码
master_log_file 主服务器配置文件
master_log_pos 主服务器读取配置文件的开始位置,也就是从第多少行开始读取。
change master to master_host='192.168.0.105',master_user='root',master_password='root',master_log_file='mysql-bin.000001',master_log_pos=120;
8.开始同步
start slave
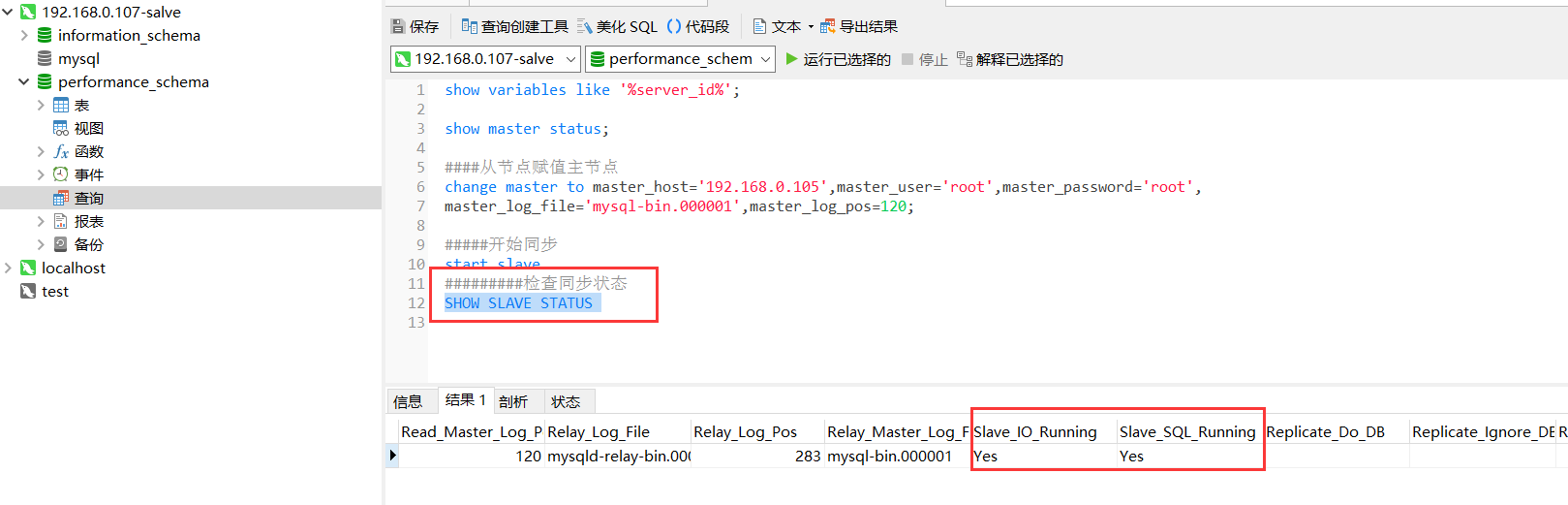
9.检查从服务器复制功能状态
SHOW SLAVE STATUS
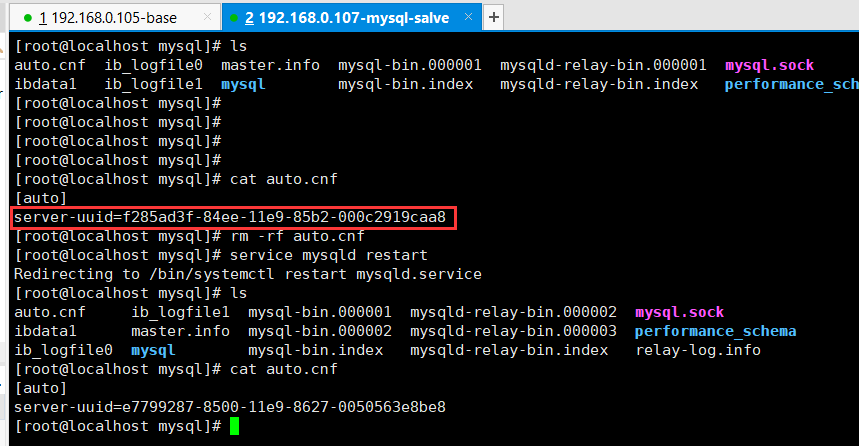
如果二个从服务器是克隆主服务器的,这时候就会出现如下图的情况,二个服务器的server-uuid 是相同的,因为是克隆过来的。这时候运行 SHOW SLAVE STATUS 就会出现 Slave_IO_Running 为 No,而Slave_SQL_Running为Yes。说明IO同步出错,在Last_IO_Error 字段可以看到错误信息,如下。错误信息的意思就是server-uuid 重复了。也就是下图展示的效果。
Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work。
如果出现这种情况,需要将 /var/lib/mysql 文件下的生成uuid 的文件删除,然后再重新启动 mysql 服务,就会重新在生成一个 server-uuid,在下图2中 也 显示了这个重新生成的server-uuid。
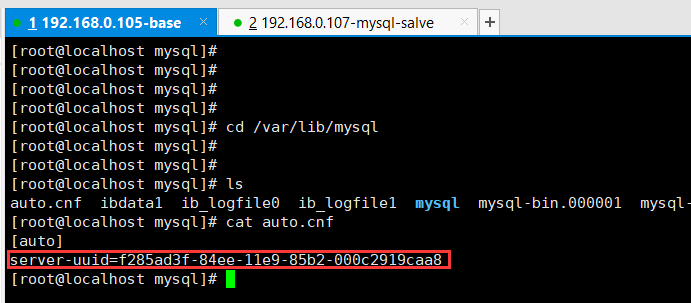
如果你的从服务器不是克隆主服务器而是重新安装的,那么就不会出现这种情况。直接运行 SHOW SLAVE STATUS 命令,如下图。则表示同步成功
存放server-uuid的 地址,可以在 /etc/my.cnf 文件中查看,如下图。

如何验证我们mysql 主从复制 集群搭建成功?
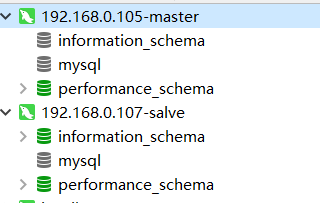
在105节点主服务器)新建test数据库,如果107节点(从服务器)能够同步过来,则说明环境搭建成功。
如下图,图一是没有创建test数据库之前,在105 服务器上创建一个test数据库,然后107关闭连接 再重新打开连接、或者直接刷新,发现test数据库已经同步过来了,如图2的效果。

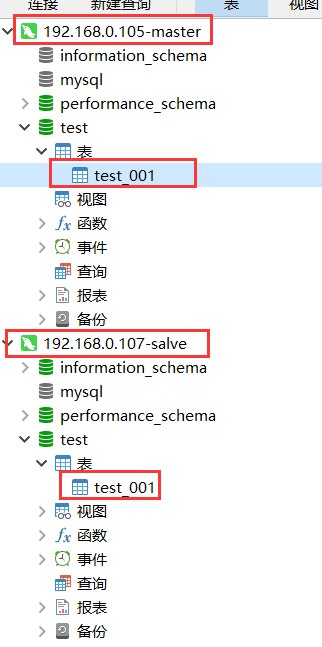
同样的,在105服务器节点中的test数据库中新建表test001,然后在107节点中刷新,test001表也同步了过来,如下图。
这时候在105节点的test数据库中的test_001数据表添加数据,107 节点也会把数据同步过来,如下图。
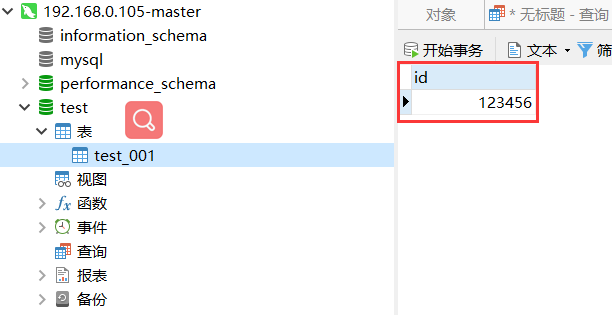

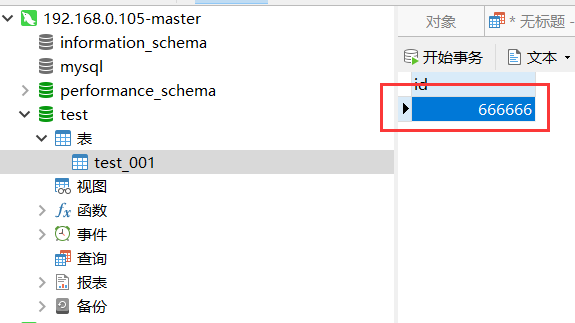
但是这时候我修改105节点数据库中数据表(test_001)的数据的时候,107节点的数据并没有更新过来,如下图。
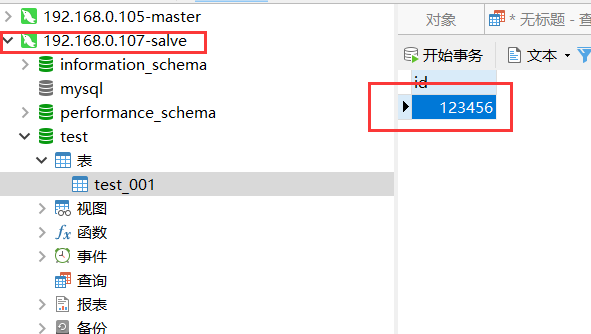
这个问题,将在下一篇读写分离博客中写出来。
如果同步执行出错,作如下修改。
show variables like '%server_id%';
show master status;
STOP SLAVE;
set GLOBAL sql_slave_skip_counter=1;
start slave;
SHOW SLAVE STATUS;
Mysql 集群环境搭建的更多相关文章
- 项目进阶 之 集群环境搭建(三)多管理节点MySQL集群
上次的博文项目进阶 之 集群环境搭建(二)MySQL集群中,我们搭建了一个基础的MySQL集群,这篇博客咱们继续讲解MySQL集群的相关内容,同时针对上一篇遗留的问题提出一个解决方案. 1.单管理节点 ...
- [原]项目进阶 之 集群环境搭建(二)MySQL集群
上次的博文中我们介绍了一下集群的相关概念,今天的博文我们介绍一下MySQL集群的相关内容. 1.MySQL集群简介 MySQL群集技术在分布式系统中为MySQL数据提供了冗余特性,增强了安全性,使得单 ...
- MHA+keepalived集群环境搭建
整个MHA+keepalived集群环境搭建 1.1. 环境简介1.1.1.vmvare虚拟机,系统版本CentOS6.5 x86_64位最小化安装,mysql的版本5.7.21,1.1.2.虚拟机器 ...
- 转 Nacos集群环境搭建
转载 送上nacos-server-1.1.3 链接:https://pan.baidu.com/s/11r3OeffHN8AwKLurmmzJmg 密码:wdu2 下载↓↓↓↓ https://g ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
随机推荐
- 完全基于卷积神经网络的seq2seq
本文参考文献: Gehring J, Auli M, Grangier D, et al. Convolutional Sequence to Sequence Learning[J]. arXiv ...
- 亚马逊AWS服务器CentOS/Linux系统Shell安装Nginx及配置自启动
领了一个亚马逊的1年免费服务器,今天尝试安装 Nginx 服务器,使用原生的 Shell 方法. 为了方便以后查看,就把过程记录一下. 注意:亚马逊(AWS)服务器默认只能用 user-ec2 账户进 ...
- 通过phpMyAdmin优化mysql 数据库可能存在的问题
通过phpMyAdmin优化mysql 数据库可能存在的问题 文章来源:外星人来地球 欢迎关注,有问题一起学习欢迎留言.评论
- SpringBoot表单数据校验
Springboot中使用了Hibernate-validate作为默认表单数据校验框架 在实体类上的具体字段添加注解 public class User { @NotBlank private St ...
- MongoDB基础笔记
MongoDB show dbs 查看当前的数据库 use test 选库 show tables/collections 查看当前库下的文档 db.help() 查看帮助 db.createColl ...
- Jmeter BeanShell 引用变量报错Error or number too big for integer
如果你通过CSV Data Set Config或者_StringFromFile函数来参数化你的请求,需要特别注意当参数为纯数字时,jmeter会默认将其识别成int型数据,说明jmeter并不是默 ...
- HTML5Audio/Video全解(疑难杂症)
1.mp4格式视频无法在chrome中播放 Chrome浏览器支持HTML5,它支持原生播放部分的MP4格式(不用通过Flash等插件).为 什么是部分MP4呢?MP4有非常复杂的含义(见http:/ ...
- 003-结构型-01-适配器模式(Adapter)
一.概述 将一个类的接口转换成客户期望的另一个接口.适配器模式让那些接口不兼容的类可以一起工作. 1.1.适用场景 已经存在的类,它的方法和需求不匹配时(方法结果相同或相似) 不是软件设计阶段考虑的设 ...
- java cpu 使用率100%
--宝典开始 top :查看 进程 ,选CPU使用率高的 获取进程ID,pid top -Hp pid:查看线程,选CPU使用率高的 获取线程ID,threadid printf "%X\n ...
- sehll变量比较
1.比较符号解释 $# 表示提供到shell脚本或者函数的参数总数: $1 表示第一个参数. -ne 表示 不等于 $?是shell变量,表示"最后一次执行命令"的退出状态.0为成 ...