Hadoop_08_客户端向HDFS读写(上传)数据流程
1.HDFS的工作机制:
- HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
- NameNode负责管理整个文件系统的元数据
- DataNode 负责管理用户的文件数据块(只管接收保存,不负责切片)
- 文件会按照固定的大小(blocksize)128M切成若干块后分布式存储在若干台datanode上
- 每一个文件块可以有多个副本,并存放在不同的datanode上
- Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
- HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
2.HDFS的写数据流程:
2.1.概述
客户端要向HDFS写数据,首先跟Namenode通信以确认可以写文件并获得接收文件block的datanode(切块在客户端进行),
然后客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block副本
默认情况下每个block都有三个副本,HDFS 数据存储单元(block)
2.2.详细步骤流程图:
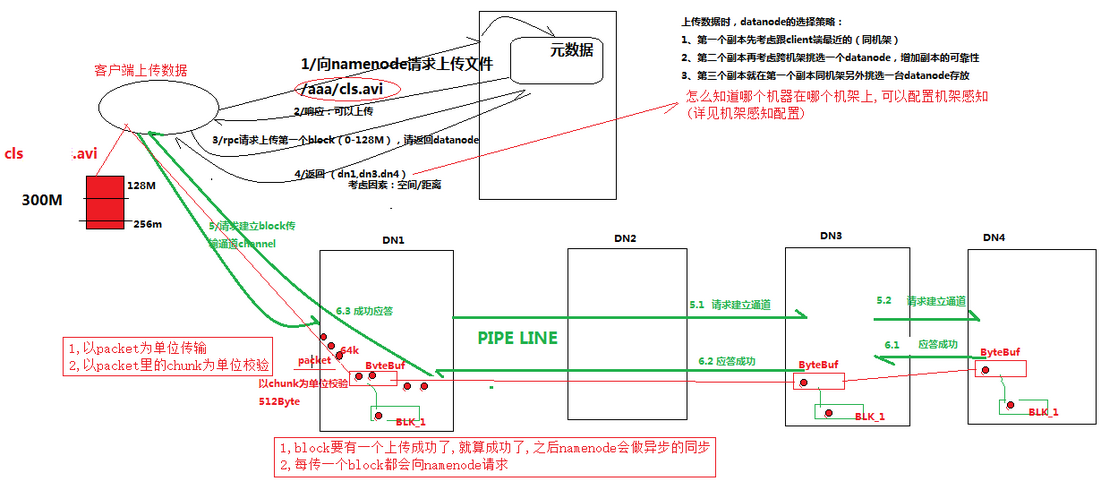
步骤详细说明
1. 跟namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2. namenode返回是否可以上传
3. client请求第一个 block该传输到哪些datanode服务器上
4. namenode返回3个datanode服务器ABC
5. client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,
将真个pipeline建立完成,逐级返回客户端
6. client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传
给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7.当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
3.HDFS的读数据流程:
客户端将要读取的文件路径发送给Namenode,Namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,
客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
读数据流程图:
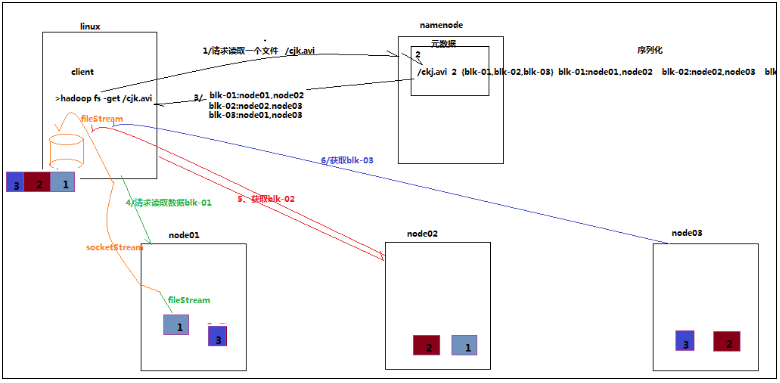
4.3.3 详细步骤解析
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
可参考文章:https://blog.csdn.net/sinat_17161487/article/details/42994021
Hadoop_08_客户端向HDFS读写(上传)数据流程的更多相关文章
- HDFS的上传下载流程
hdfs上传流程 首先客户端向nn请求上传文件.nn经过检查回应客户端是否可以上传.客户端得到同意后向nn请求上传第一块文件的dn.nn返回给客户端dn的地址.客户端与其中一个dn1建立连接然后dn1 ...
- HDFS上传数据的流程
1.当客户端输入一条指令:hdfs dfs -put text.txt /text时,这条命令会给到DistributeFileSystem. 2.通过DistributeFileSystem简称DF ...
- 通过 微软 pai-fs 上传数据到HDFS (Microsoft OpenPAI)
准备环境 (个人使用记录,方便下次使用查阅~~) 首先保证PAI是登陆状态: 进入GitHub项目所在地址: https://github.com/Microsoft/pai/ 然后切换分支到 具体 ...
- hdfs文件上传机制与namenode元数据管理机制
1.hdfs文件上传机制 文件上传过程: 1.客户端想NameNode申请上传文件, 2.NameNode返回此次上传的分配DataNode情况给客户端 3.客户端开始依向dataName上传对应 ...
- hadoop学习记录--hdfs文件上传过程源码解析
本节并不大算为大家讲接什么是hadoop,或者hadoop的基础知识因为这些知识在网上有很多详细的介绍,在这里想说的是关于hdfs的相关内容.或许大家都知道hdfs是hadoop底层存储模块,专门用于 ...
- HDFS的上传流程以及windows-idea操作文件上传的注意
HDFS的上传流程 命令:hdfs dfs -put xxx.wmv /hdfs的文件夹 cd进入到要上传文件的当前目录,再输入hdfs命令上传,注意-put后tab可以自动补全, 最后加上你要上传到 ...
- Amzon MWS API开发之 上传数据
亚马逊上传数据,现有能操作的功能有很多:库存数量.跟踪号.价格.商品....... 我们可以设置FeedType值,根据需要,再上传对应的xml文件即可. 下面可以看看FeedType类型 这次我们拿 ...
- Amazon MWS 上传数据 (一) 设置服务
Amazon 上传数据的流程为: 通过 SubmitFeed 操作.加密标头和所有必需的元数据(包括 FeedType 的值在内),来提交 XML 或文本型数据文件.正如亚马逊 MWS的所有提交内容一 ...
- tftp--实现服务器与客户端的下载与上传【转】
转自:https://blog.csdn.net/xiaopangzi313/article/details/9122975 版权声明:本文为博主原创文章,未经博主允许不得转载. https://bl ...
随机推荐
- CentOS8 使用 aliyun 阿里云 镜像站点的方法
CentOS8现已可使用国内的aliyun阿里云镜像站,方法如下: 用cd命令切换到yum.repos目录,备份原始的3个repo文件:cd /etc/yum.repos.d/sudo cp Cent ...
- Spring Cloud(2):服务发现(Eureka)
Spring Cloud Eureka是Spring Cloud Netflix项目下的一个模块,作用是服务的注册和发现,并实现服务治理.它有一个(或一组,以实现高可用)服务注册中心(eureka s ...
- Windows 10 删除资源管理器中7个文件夹
Windows 10 安装完成之后 ,在资源管理器中会存在 7 个文件夹,他们分别是:图片.视频.下载.音乐.桌面.文档.3D对象. 我们可以通过修改注册表的方式,隐藏这7个文件夹.相关注册表内容如下 ...
- 20190526 - CentOS 7 中 安装 MySQL 8 并授权 root 远程访问
1. CentOS 7 中 安装 MySQL 8 CentOS 7 中内置 MariaDB 建议升级一下用,性能好很多.但如果一定要用 MySQL 8,就得自己装. 坦白的说,Oracle 升级 My ...
- 企业证书发布app到七牛云服务
---恢复内容开始--- 最近在做企业证书发布app,从申请企业证书,到测试程序发布到七牛云存储.整了几天终于实现了,整理一下资料. 1.首先,申请企业证书. 到苹果开发网站申请企业证书 https: ...
- activeMQ(1)
消息中间件 作用:解耦 削峰 异步 JMS编码总体架构: 一般代码流程 @Test public void test1(){ //创建连接工厂 ActiveMQConnectionFactory f ...
- Python 中__new__()和__init__()的区别
转自: https://blog.csdn.net/weixin_37579123/article/details/89515577 __new__方法:类级别的方法 特性: 1.是在类准备将自身实例 ...
- 腾讯云远程连接Kafka
腾讯云服务器上部署Kafka,使用server.properties中公网IP配置: 启动时候报错: ERROR [KafkaServer id=0] Fatal error during Kafka ...
- springboot 论坛项目
项目演示地址:http://www.mawen.co/ 快速搭建sprintboot项目 运行第一个springboot项目 leaf package hello; import org.spring ...
- 剑指offer5:用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
1. 题目描述 用两个栈来实现一个队列,完成队列的Push和Pop操作. 队列中的元素为int类型. 2. 思想 (1)栈的特点是先进后出,而队列的特点是先进先出: (2)因此,入队列的情况和入栈的情 ...