2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)
Rich feature hierarchies for accurate object detection and semantic segmentation
Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik
UC Berkeley
丰富多级特征用于精准对象检测和语义分割
------------------------------------------------------------------------------------鉴于前一篇篇幅太长,此处采用缩略翻译
摘要:
开头大意就是说在权威(canonical)的PASCAL VOC数据集上,过去的人们都是搞一坨坨特征,然后再进行图像上下文分析(也就是空间几何结构,类似DPM),现在我们用CNNs达到了53.3%准确率。文章关键信息:(1)使用cnn对图像区域(region)进行检测和分割(2)因为标注好的训练数据太少,我们基于不同领域细调(domain-soecific fine-tuning)得到了很好提升效果。这种CNN+Region的组合,就是R-CNN。我们还和一种Overfeat方法进行了比较,他也是一种基于CNN的方法,但我们比他效果牛多了,测试数据集ILSVRC2013,200个类别。源码在这儿:http://www.cs.berkeley.edu/˜rbg/rcnn
1介绍:
大家都认同,特征真的TM的重要,过去人们搞了一堆堆特征,HOG啊,sift啊,balabala的。。。但图像对象检测的效果自从2012之后就提升很慢。
SIFT、HOG都是基于块直方图统计,某种意义上和我们视觉皮层规律相符合。但我们整个看东西的过程从皮层到大脑还会经历各种神经系统,中间可能产生的许多有用分级特征(hierarchical features)。
Fukushima提出过一种类似生物学的模型,Lecun提出过随机梯度下降法+反向传播的CNN架构。CNN在1990年代很多人使用,但后来因为SVM就冷下来。直到2012年的Alexnet出来才又火了(参考上一篇翻译)。
CNN分类火了之后,大家各种兴奋,开始讨论怎么把这个模型用到VOC数据集检测问题上呢???
我们来解答这个问题!本文展示了CNN用在检测上的效果,比HOG之流的方法效果牛B多了。主要也就两个问题:1、如何使用深度神经网络做检测?2、如何用小规模标注的数据集来训练大型神经网络模型?
检测(detection)和分类(classification)不同的就是检测需要定位(localization)(定位就是找一个点,检测就是再加上bindingbox),我们把定位看成一个回归问题(也就是特征和响应值的拟合)。其他也有人这么做,但效果很烂(我们的平均准确率(map)58.5%,他们的30.5%)。另外一种方法就是使用一个滑动窗口检测。过去CNN其实在检测上已经用了20多年,但结构都很简单,两个卷积层的样子,主要是行人,人脸检测,层数少的原因是想保留下高清图像细节。我们的有5个卷积层,有很大的感受野(receptive field)195*195和大步长32(感受野是个什么玩意,看这个:http://blog.sciencenet.cn/blog-597740-979117..html),这使得基于滑动窗口来进行精准定位变得很难。
而我们是采用产生区域的方法,产生区域的方法在检测和分割上都很有用。测试的时候我们每张图产生2000个区域,每个区域都用CNN提取特征,后用SVM分类。输入区域(region)的时候,我们会调整成固定大小。图1是整体架构和结果。
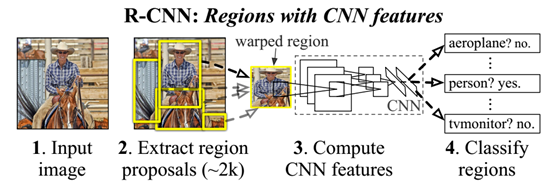
图1:对象检测整体框架:1、输入图像。2、提取2000个region。3、计算每隔区域特征。4、线性svm分类,准确率53.7%。不用CNN特征,而是用词袋模型,只有31.4%,DPM是3.4%。在200个类别的ILSVRC2013数据集上我们的准确率31.4%,overfeat24.3%
另外刚刚第二个问题:数据不够多。解决这个问题办法是:无监督预训练+细调。明白点说就是:在Imagenet上训练CNN,然后在VOC上细调。这样的效果是很好的,例子就是好多人直接用Alexnet提取特征然后做好多其他研究,什么场景识别啊,效果都不错。
我们训练速度也很高效,类别相关的计算项目就是一个小型的矩阵向量相乘,和非极大值抑制(Non-maximum suppression,http://blog.csdn.net/pb09013037/article/details/45477591),另外,我们的特征维数比起之前的要下降两个数量级(two order of magnitude)
我们发现加一个Bindingbox回归算法可以很好地降低错误率
我们发现我们的方法用在分割也很好,VOC2011上准确率47.9%
2 使用R-CNN进行对象检测
方法简单概括就是:region提取 + CNN 特征提取 + SVM分类。

图2:VOC2007训练集图片打包样例
2.1 模块设计
区域提取:现今有很多区域提取算法:objectness、selective
search、CPMC等等,由于R-CNN对于区域算法并不挑,所以为了好对比,我们使用selecttive search。
特征提取:直接使用Alexnet,五卷积和三全连接
我们会把region都resize到Alexnet要求的固定大小,但因为要平移裁剪,我们把region扩张16个像素。
2.2. 测试
把刚才的过程又复述一遍……一堆废话之后开始讨论下我们的算法时间。
13s/image on a GPU
53s/image on a CPU
一张图特征矩阵2000*4096,然后表述一大堆,意思就是我们的这个特征已经很小了,还适用于所有类别,还很省内存。
2.3. 训练
有监督预训练
这一步就是使用caffe+alexnet,我们的准确率稍差,因为训练集被我们精简了。
基于领域的精调(Domain-specific fine-tuning)
为了检测,我们在模型基础上调整,替换最后1000维输出变成我们的N+1维的输出,初始值随机,N是类别数目,1是背景。
然后输入区域作为图像来调整模型,还是用随机梯度下降(SGD),学习速率0.001(以前的1/10), 同一批(batch)训练样本128个包括96个正样本,32个负样本
对象类别分类器
怎样的算正样本,我们选择和标注结果(groundtruth)overlap 0.3以下的作为负样本。这是通过验证集严格筛选的,从{0,0.1,0.2,0.3……0.5}中尝试一遍会发现,选择0.5作为阈值,准确率下降5个百分点,选择0作为阈值,平均准确率下降4个百分点。注:正样本是严格groundtruth。
而我们的SVM分类器是在每个类别上优化的,使用了Hard-negative mining 技术,只需要遍历一遍所有样本就可以很快收敛。
附录B会讨论下,在SVM分类器和训练神经网络中,正负样本的定义是不同的。另外讨论为什么要用SVM替换softmax。
2.4.
PASCAL VOC 2010-12的结果
废话不说,看结果。在12数据集上我们贴出来使用和不使用包围盒回归的结果(with
and without bounding-box regression)。

表 1: VOC2010平均检测准确率 (%)
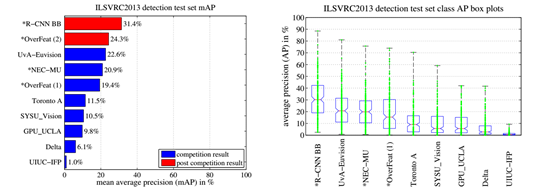
图 3: (左)
ILSVRC2013 平均检测准确率,(右) 每种方法两百个包围盒的箱形图(Box-plot)。没有 OverFeat的箱形图,因为每个类别结果没有公开,红线代表平均AP,盒底部和上部表示25%和75%The
red
line marks the median AP, the box bottom and top are the 25th and 75th
percentiles. 而上方和下方是最大最小AP. AP都画成绿点。
3. 可视化,剥离本质,和错误模型
3.1 可视化学习特征
第一层的特征很容易可视化,他们抓取了边缘和对比强烈的颜色,而如果要理解更上层就比较困难。Zeiler and Fergus (第0篇翻译中)使用了反卷积操作,而我们使用一种更加简便的方法。我们计算出region的响应度,然后进行排序,大概有1000万个,我们把这些区域进行最大值抑制然后显示出来。

2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)的更多相关文章
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- Rich feature hierarchies for accurate object detection and semantic segmentation(理解)
0 - 背景 该论文是2014年CVPR的经典论文,其提出的模型称为R-CNN(Regions with Convolutional Neural Network Features),曾经是物体检测领 ...
- 目标检测论文解读1——Rich feature hierarchies for accurate object detection and semantic segmentation
背景 在2012 Imagenet LSVRC比赛中,Alexnet以15.3%的top-5 错误率轻松拔得头筹(第二名top-5错误率为26.2%).由此,ConvNet的潜力受到广泛认可,一炮而红 ...
- 论文笔记(一)---翻译 Rich feature hierarchies for accurate object detection and semantic segmentation
论文网址: https://arxiv.org/abs/1311.2524 RCNN利用深度学习进行目标检测. 摘要 可以将ImageNet上的进全图像分类而训练好的大型卷积神经网络用到PASCAL的 ...
- R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)论文理解
论文地址:https://arxiv.org/pdf/1311.2524.pdf 翻译请移步: https://www.cnblogs.com/xiaotongtt/p/6691103.html ht ...
随机推荐
- sip呼叫里SDP的一些字段的含义
v=0 o=- 1 0 IN IP4 164.135.25.51 #local ip ,即本机SIP信令交互地址 s=SNS call #用于传递会话主题 c=IN IP4 164.135.25.51 ...
- SpringBoot的启动配置原理
一.启动流程 创建SpringApplication对象 public class SpringApplication { public SpringApplication(Class... prim ...
- django inclusion用法
概述: inclusion主要的是生成html标签, 返回的是一个字典,大分部跟simple_tag类似, simple_tag可返回任意类型的值 定义inclusion from django im ...
- vue报类似警告Computed property "isLoading" was assigned to but it has no setter
一.原因:一个计算属性,当计算传入的是一个函数,或者传入的是一个对象,而没有设置 setter,也就是 set 属性,当你尝试直接该改变这个这个计算属性的值,都会报这个警告,vuex还会出现通过com ...
- centos所有版本镜像下载地址
centos所有版本镜像下载地址 版本号 下载地址 更新时间 centos2.1 iso镜像下载 2.1/ 2009/8/19 1:36 centos3.1 iso镜像下载 3.1/ 2005/ ...
- Hadoop_20_MapReduce程序的运行模式
1.MapReduce程序的运行模式 1. Windows中运行MapReduce程序 (1)mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行 (2)而处理的数据及 ...
- 车型识别API调用与批量分类车辆图片
版权声明:本文为博主原创文章,转载 请注明出处 https://blog.csdn.net/sc2079/article/details/82189824 9月9日更:博客资源下载:链接: https ...
- golang embedded structs
golang 中把struct 转成json格式输出 package main import ( "encoding/json" "fmt" ) type Pe ...
- 不同显卡对mrt 的支持
ios bits限制大概512bits 低端256bits mali 也是bits限制 2017年 Mali-T760 128bits adreno android显卡4 肯定可以 因为deferre ...
- 我对line-height及vertical-align的一点理解
张鑫旭老师在文章<我对CSS vertical-align的一些理解与认识(一)>中提到: vertical-align:middle属性的表现与否,仅仅与其父标签有关,至于我们通常看到的 ...