R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)论文理解
论文地址:https://arxiv.org/pdf/1311.2524.pdf
翻译请移步:
https://www.cnblogs.com/xiaotongtt/p/6691103.html
https://blog.csdn.net/v1_vivian/article/details/78599229
背景:
1、近10年以来,以人工经验特征为主导的物体检测任务mAP【物体类别和位置的平均精度】提升缓慢;
2、随着ReLu激励函数、dropout正则化手段和大规模图像样本集ILSVRC的出现,在2012年ImageNet大规模视觉识别挑战赛中,Hinton及他的学生采用CNN特征获得了最高的图像识别精确度;
3、上述比赛后,引发了一股“是否可以采用CNN特征来提高当前一直停滞不前的物体检测准确率“的热潮。
4、目标检测(mAP) = 目标识别(accuracy)+定位(IOU):

mAP指标请移步:https://blog.csdn.net/katherine_hsr/article/details/79266880
5、传统目标检测流程:
区域选择(穷举策略:采用滑动窗口,且设置不同的大小,不同的长宽比对图像进行遍历,时间复杂度高)
特征提取(SIFT、HOG等;形态多样性、光照变化多样性、背景多样性使得特征鲁棒性差)
分类器(主要有SVM、Adaboost等)
6、传统目标检测的主要问题:
基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余
手工设计的特征对于多样性的变化没有很好的鲁棒性
R-CNN算法流程:
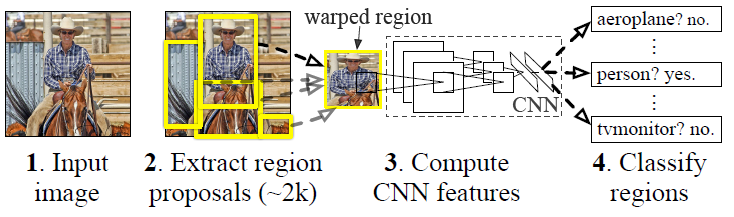
测试过程:
1、输入一张多目标图像,采用selective search算法提取约2000个建议框;
候选区域生成(Selective Search)
step0:图片采用一定过分割方法生成区域集R
step1:计算区域集R里每个相邻区域的相似度(颜色、纹理、尺寸和空间交叠)S={s1,s2,…}
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
Selective Search进一步详解请移步:https://blog.csdn.net/ibunny/article/details/79396754
2、先在每个建议框周围加上16个像素值为建议框像素平均值的边框,再直接变形为227×227的大小;
为什么要将建议框变形为227×227?怎么做?
本文采用AlexNet CNN网络进行CNN特征提取,为了适应AlexNet网络的输入图像大小:227×227,故将所有建议框变形为227×227。
那么问题来了,如何进行变形操作呢?作者在补充材料中给出了四种变形方式:
① 考虑context【图像中context指RoI周边像素】的各向同性变形,建议框像周围像素扩充到227×227,若遇到图像边界则用建议框像素均值填充,下图第二列;
② 不考虑context的各向同性变形,直接用建议框像素均值填充至227×227,下图第三列;
③ 各向异性变形,简单粗暴对图像就行缩放至227×227,下图第四列;
④ 变形前先进行边界像素填充【padding】处理,即向外扩展建议框边界,以上三种方法中分别采用padding=0下图第一行,padding=16下图第二行进行处理;
经过作者一系列实验表明采用padding=16的各向异性变形即下图第二行第三列效果最好,能使mAP提升3-5%。

3、先将所有建议框像素减去该建议框像素平均值后【预处理操作】,再依次将每个227×227的建议框输入AlexNet CNN网络获取4096维的特征【比以前的人工经验特征低两个数量级】,2000个建议框的CNN特征组合成2000×4096维矩阵;
4、将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘【20种分类,SVM是二分类器,则有20个SVM】,获得2000×20维矩阵表示每个建议框是某个物体类别的得分;
5、分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框;
非极大值抑制NMS(Non Maximum Suppression)
目的:为了保留一个最优窗

6、分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
为什么要采用回归器?回归器是什么有什么用?如何进行操作?
首先要明确目标检测不仅是要对目标进行识别,还要完成定位任务,所以最终获得的bounding-box也决定了目标检测的精度。
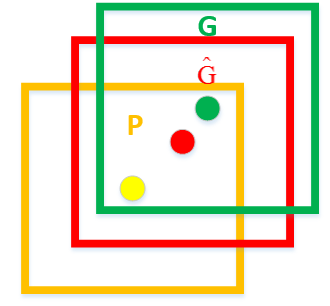
这里先解释一下什么叫定位精度:定位精度可以用算法得出的物体检测框与实际标注的物体边界框的IoU值来近似表示。
如下图所示,绿色框为实际标准的卡宴车辆框,即Ground Truth;黄色框为selective search算法得出的建议框,即Region Proposal。即使黄色框中物体被分类器识别为卡宴车辆,但是由于绿色框和黄色框IoU值并不大,所以最后的目标检测精度并不高。采用回归器是为了对建议框进行校正,使得校正后的Region Proposal与selective search更接近, 以提高最终的检测精度。论文中采用bounding-box回归使mAP提高了3~4%。



训练过程:
1、有监督预训练
使用ILSVRC样本集(ImageNet挑战赛数据集),仅用图像类别标签,没有图像物体位置标注;
采用AlexNet CNN网络进行有监督预训练,学习率=0.01;
该网络输入为227×227的ILSVRC训练集图像,输出最后一层为4096维特征->1000类的映射,训练的是网络参数。
2、特定样本下的微调
PASCAL VOC 2007样本集上既有图像中物体类别标签,也有图像中物体位置标签;
采用训练好的AlexNet CNN网络进行PASCAL VOC 2007样本集下的微调,fine-tune的Loss仍采用AlexNet网络的softmax的loss,该网络输入为建议框【由selective search而来】变形后的227×227的图像,将最后一个全连接层的输出(分类数)从1000改为21维【20类+背景】输出,然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变(SGD,学习率0.001【0.01/10为了在学习新东西时不至于忘记之前的记忆】),mini-batch为32个正样本和96个负样本【由于正样本太少】;
3、SVM训练

由于SVM是二分类器,需要为每个类别训练单独的SVM;
SVM训练时输入正负样本在AlexNet CNN网络计算下的4096维特征,输出为该类的得分,训练的是SVM权重向量;
由于负样本太多,采用hard negative mining的方法在负样本中选取有代表性的负样本。
4、Bounding-box regression训练

测试和训练更多细节详见:
https://blog.csdn.net/WoPawn/article/details/52133338
https://blog.csdn.net/ibunny/article/details/79396754
还存在什么问题
1、很明显,最大的缺点是对一张图片的处理速度慢,这是由于一张图片中由selective search算法得出的约2k个建议框都需要经过变形处理后由CNN前向网络计算一次特征,这其中涵盖了对一张图片中多个重复区域的重复计算,很累赘;
2、知乎上有人说R-CNN网络需要两次CNN前向计算,第一次得到建议框特征给SVM分类识别,第二次对非极大值抑制后的建议框再次进行CNN前向计算获得Pool5特征,以便对建议框进行回归得到更精确的bounding-box,这里文中并没有说是怎么做的,博主认为也可能在计算2k个建议框的CNN特征时,在硬盘上保留了2k个建议框的Pool5特征,虽然这样做只需要一次CNN前向网络运算,但是耗费大量磁盘空间;
3、训练时间长,虽然文中没有明确指出具体训练时间,但由于采用RoI-centric sampling【从所有图片的所有建议框中均匀取样】进行训练,那么每次都需要计算不同图片中不同建议框CNN特征,无法共享同一张图的CNN特征,训练速度很慢;
4、整个测试过程很复杂,要先提取建议框,之后提取每个建议框CNN特征,再用SVM分类,做非极大值抑制,最后做bounding-box回归才能得到图片中物体的种类以及位置信息;同样训练过程也很复杂,ILSVRC 2012上预训练CNN,PASCAL VOC 2007上微调CNN,做20类SVM分类器的训练和20类bounding-box回归器的训练;这些不连续过程必然涉及到特征存储、浪费磁盘空间等问题。
其余参考:
https://blog.csdn.net/u014380165/article/details/72851035
https://blog.csdn.net/shenxiaolu1984/article/details/51066975
R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)论文理解的更多相关文章
- Rich feature hierarchies for accurate object detection and semantic segmentation(理解)
0 - 背景 该论文是2014年CVPR的经典论文,其提出的模型称为R-CNN(Regions with Convolutional Neural Network Features),曾经是物体检测领 ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
- 2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick Jeff ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- 论文笔记(一)---翻译 Rich feature hierarchies for accurate object detection and semantic segmentation
论文网址: https://arxiv.org/abs/1311.2524 RCNN利用深度学习进行目标检测. 摘要 可以将ImageNet上的进全图像分类而训练好的大型卷积神经网络用到PASCAL的 ...
- 【CV论文阅读】:Rich feature hierarchies for accurate object detection and semantic segmentation
R-CNN总结 不总结就没有积累 R-CNN的全称是 Regions with CNN features.它的主要基础是经典的AlexNet,使用AlexNet来提取每个region特征,而不再是传统 ...
随机推荐
- cocos代码研究(2)Layer学习笔记
auto layer = Layer::create(); /*************华丽分割线*************/ auto layer = LayerColor::create(Colo ...
- Object-C-NSArray
NSArray *fruitArray=[[NSArray alloc] initWithObjects:@"apple",@"banana",@"p ...
- 小试---EF5.0简介
简介 实体框架Entity Framework 是 ADO.NET 中的一组支持开发面向数据的软件应用程序的技术.是微软的一个ORM框架.简单的说就是把关系型数据库映射成面向对象模型. 一篇更加详细的 ...
- 20165207 Exp2 后门原理与实践
20165207 Exp2 后门原理与实践 〇.实验准备 两个虚拟机,一个kali一个win7.kali的ip是192.168.43.72,win7的ip是192.168.43.116,在win7关掉 ...
- python中的对象(三)
一.python对象 python使用对象模型来存储数据.构造任何类型的值都是一个对象. 所有python对象都拥有三个特性:身份.类型.值 身份:每个对象都有一个唯一的身份标识自己,任何对象的身份可 ...
- QEvent postEvent/sendEvent
可以自訂事件類型,最簡單的方式,是透過QEvent::Type指定事件類型的常數值,在建構QCustomEvent時作為建構引數並透過postEvent()傳送事件,例如: const QEvent: ...
- Linux中Postfix邮件安装Maildrop(八)
Postfix使用maildrop投递邮件 Maildrop是本地邮件投递代理(MDA), 支持过滤(/etc/maildroprc).投递和磁盘限额(Quota)功能. Maildrop是一个使用C ...
- Python之路----迭代器与生成器
一.迭代器 L=[1,,2,3,4,5,] 取值:索引.循环for 循环for的取值:list列表 dic字典 str字符串 tuple元组 set f=open()句柄 range() enumer ...
- vc编辑器常用设置
代码格式化 1.选中代码: 2.ctrl+K: 3.ctrl+F; 显示行号
- C_Learning(2)
/指针 /指针变量指向一个变量的地址 /给指针变量赋的值只能是地址 /指针变量的赋值 /{ int a; int *p; p=&a; } or { int a; int *p=&a; ...