Python之scrapy linkextractors使用错误
1.环境及版本
python3.7.1+scrapy1.5.1
2.问题及错误代码详情
优先贴上问题代码,如下:
import scrapy
from scrapy.linkextractors import LinkExtractor class MatExamplesSpider(scrapy.Spider):
name = 'mat_examples'
# allowed_domains = ['matplotlib.org']
start_urls = ['https://matplotlib.org/gallery/index.html'] def parse(self, response):
le = LinkExtractor(restrict_xpaths='//a[contains(@class, "reference internal")]/@href')
links = le.extract_links(response)
print(response.url)
print(type(links))
print(links)
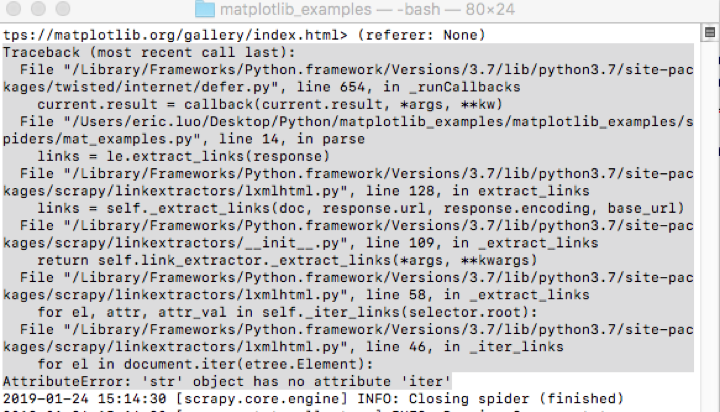
运行代码后报错如下:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/twisted/internet/defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "/Users/eric.luo/Desktop/Python/matplotlib_examples/matplotlib_examples/spiders/mat_examples.py", line 14, in parse
links = le.extract_links(response)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/lxmlhtml.py", line 128, in extract_links
links = self._extract_links(doc, response.url, response.encoding, base_url)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/__init__.py", line 109, in _extract_links
return self.link_extractor._extract_links(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/lxmlhtml.py", line 58, in _extract_links
for el, attr, attr_val in self._iter_links(selector.root):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/lxmlhtml.py", line 46, in _iter_links
for el in document.iter(etree.Element):
AttributeError: 'str' object has no attribute 'iter'
出现错误后自检代码并未发现问题,上网查找也未发现相关的问题;于是将代码改成(restrict_css)去抓取数据,发现是能正常获取到数据的,于是改回xpath;但这次先不使用linkextractor,采用scrapy自带的response.xpath()方法去获取对应链接所在标签的href属性值;发现这样是可以获取到正常的数据的:
即将:
le = LinkExtractor(restrict_xpaths='//a[contains(@class, "reference internal")]/@href')
links = le.extract_links(response)
改成:
links = respon.xpath(‘//a[contains(@class, "reference internal")]/@href').extract()
然后又发现报错是: 'str' object has no attribute 'iter'
而正常返回的links数据类型应该是list才对,不应该是str,所以猜测可能是由于规则写错了导致获取的数据不是list而变成了一个不知道的str;这样针对性的去修改restrict_xpaths中的规则,最后发现去掉/@href后能够获取我所需要的正常的数据;
即将:
le = LinkExtractor(restrict_xpaths='//a[contains(@class, "reference internal")]/@href')
改成:
le = LinkExtractor(restrict_xpaths='//a[contains(@class, "reference internal")]')
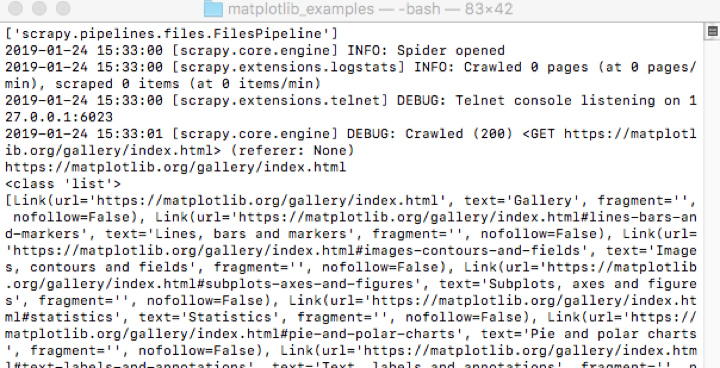
重新运行代码,发现成功获取数据,输出结果如下截图所示:
*****爬虫初学者,不喜勿喷*****
Python之scrapy linkextractors使用错误的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- python之scrapy框架基础搭建
一.创建工程 #在命令行输入scrapy startproject xxx #创建项目 二.写item文件 #写需要爬取的字段名称 name = scrapy.Field() #例 三.进入spide ...
- Python:Scrapy(三) 进阶:额外的一些类ItemLoader与CrawlSpider,使用原理及总结
学习自:Python Scrapy 爬虫框架实例(一) - Blue·Sky - 博客园 这一节是对前两节内容的补充,涉及内容为一些额外的类与方法,来对原代码进行改进 原代码:这里并没有用前两节的代码 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- dota玩家与英雄契合度的计算器,python语言scrapy爬虫的使用
首发:个人博客,更新&纠错&回复 演示地址在这里,代码在这里. 一个dota玩家与英雄契合度的计算器(查看效果),包括两部分代码: 1.python的scrapy爬虫,总体思路是pag ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
随机推荐
- 系统服务-----Activity服务的获取getSystemService
android的后台存在非常多service,它们在系统启动的时候被SystemServer开启.来为系统的正常执行做支撑.Activity中要调用这些service就得使用getSystemServ ...
- vim gvim技巧大全(9)(转载)
vim gvim技巧大全(9) 2 用命令}移动到这个段落的底部,标记为b3 输入命令:'a,'b move来移动文本.老版本的Vi编辑器不能很好的来处理多文件.但是Vim在处理多文件上却显得优秀得多 ...
- 网易UI自动化测试工具Airtest中导入air文件中的方法
最近看了一下网易的Airtest ,UI测试工具,写了一些后在导入其他air文件中的.py文件,卡了一下,现在博客中纪录一下导入其他air文件的方式: 在Airtest 测试工具中,导入其他air文件 ...
- HTML+CSS+JS总结
==================HTML(超文本标记语言)========== <!DOCTYPE> 声明位于文档中的最前面的位置,处于 <html> 标签之前.此标签可告 ...
- 5.27 indeed 第三次网测
1. 第一题, 没有看 2. 暴力枚举.每一个部分全排列, 然后求出最大的请求数. #include<bits/stdc++.h> #define pb push_back typedef ...
- 禁止tomcat扫描jar包的tld文件
禁止tomcat扫描jar包的tld文件tomcat/conf/logging.properties 取消注释org.apache.jasper.compiler.TldLocationsCache. ...
- Java面试概念之String、StringBuffer与StringBuilder的区别
参考博客 http://www.cnblogs.com/lchzls/p/6711375.html java中String.StringBuffer.StringBuilder是Java编程中经常使用 ...
- 大白话理解cookie
HTTP协议是一个无状态的协议,服务器无法区分出两次请求是否发送自同一服务器. 需要通过会话控制来解决这个问题,会话控制主要有两种方式Cookie 和 Session. Cookie就是一个头,Coo ...
- Java 开源博客 Solo 1.2.0 发布 - 一键启动
Solo 1.2.0 正式发布了,感谢一直以来关注 B3log 开源的朋友! 在这个版本中,我们引入了一个新的特性 -- 独立模式: 不需要安装数据库.Servlet 容器 只需要安装好 Java 环 ...
- Ubuntu16下安装lamp
1.安装php7 sudo apt-get install php7.0 php7.0-mcrypt 2.安装MySQL sudo apt-get install mysql-server 输入 su ...