大数据(3):基于sogou.500w.utf8数据Hbase和Spark实践
1. HBase安装部署操作
a) 解压HBase安装包
tar –zxvf hbase-0.98.0-hadoop2-bin.tar.gz
b) 修改环境变量 hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_71/
c) 修改配置文件 hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property> <name>hbase.cluster.distributed</name>
<value>true</value> </property>
<property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbase</value>
</property> <property>
<name>hbase.zookeeper.quorum</name>
<value>master</value> </property>
</configuration>
d) regionservers
将文件中的localhost改为slave
e) 设置环境变量
vi .bash_profile
export HBASE_HOME=hbase的安装路径
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*
f) 复制HBase安装文件到slave节点
g) 验证启动 start-hbase.sh
http://master:60010 访问HBase集群
jps 查看进程
1. 查询HBase版本信息
hbase > version

2. 查询服务器状态信息
hbase> status

3. 列出所有表
list --类似于show tables;

4. 创建一张表table1(包含两个列族)
create ‘table1’, ‘columnsfamily1’, ‘columnsfamily2’
5. 查看表的描述信息
describe ‘table1’

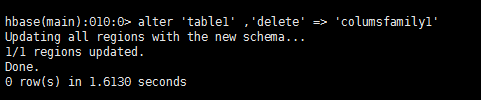
6. 修改表的模式,删除列族columnsfamily1
alter ‘table1’ , ‘delete’ => ‘columnsfamily1’
注意:修改表模式之前请将表disable
disable ‘table1’
7. 删除一张表
disable ‘table1’
drop ‘table1’
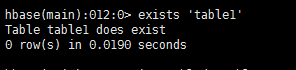
8. 查询表的状态
exists ‘table1’
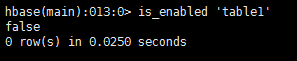
is_enabled ‘table1’
is_disabled ‘table1

9. 插入若干行数据(创建一张学生表,包含两个列族)
put ‘student’, ‘95001’, ‘cf1:name’, ‘xiaoming’
put ‘student’, ‘95001’, ‘cf1:gender’, ‘male’
put ‘student’, ‘95001’, ‘cf2:address’, ‘zhanjiang’
put ‘student’, ‘95002’, ‘cf1:name’, ‘wangli’
put ‘student’, ‘95002’, ‘cf2:address’, ‘guangzhou’
10.获取数据
get ‘student’ , ‘95002’
get ‘student’, ‘95002’, ‘cf1’

get ‘student’, ‘95001’, ‘cf1:name’

11. 更新数据
put ‘student’, ‘95001’, ‘cf2:address’ , ‘maoming’
可通过时间戳查看修改前的数据(两条都还在)

get ‘student’,’95001’, {COLUMN =>’cf1:address’, TIMESTAMP =>29837173123}

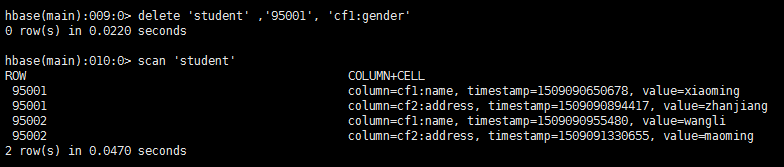
12. 全表扫描
scan ‘student’

13.删除95001的性别字段值
delete ‘student’ ,’95001’, ‘cf1:gender’
14. 删除整行
deleteall ‘student’,’95002’

15. 查询表中的行数
count ‘student’

16. 清空表
truncate ‘student’

2. 使用Hbase shell完成下列表格的创建和值的输入(要求能查看最近三个版本的数据);
Row Key Persondata Info
name gender address phone
1000 Alice female T3: New York
T2: Boston
T1: Los Angels
1001 John T2:3478193
T1:3749274
1002 Sam Male Houston
Shell脚本如下:
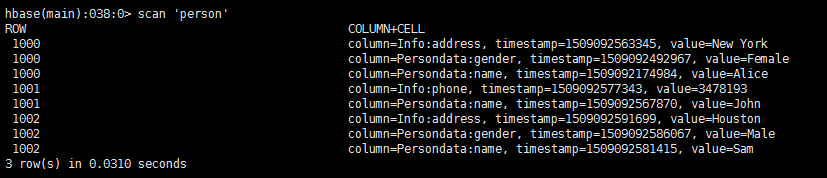
create 'person', 'Persondata','Info'
put 'person','1000', 'Persondata:name','Alice'
put 'person','1000', 'Persondata:gender','Female'
put 'person','1000', 'Info:address','Los Angels'
put 'person','1000', 'Info:address','Boston'
put 'person','1000', 'Info:address','New York'
put 'person','1001', 'Persondata:name','John'
put 'person','1001', 'Info:phone','3749274'
put 'person','1001', 'Info:phone','3478193'
put 'person','1002', 'Persondata:name','Sam'
put 'person','1002', 'Persondata:gender','Male'
put 'person','1002', 'Info:address','Houston'
输出结果:
3. Spark的安装
1)解压安装包
tar –zxvf spark-1.5.2-bin-2.5.2.tar.gz
2)配置环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
3)验证Spark安装
./spark-submit –class org.apache.spark.examples.SparkPi
--master yarn-cluster
--num-executors 3
--driver-memory 1g
--executor-memory 1g
--executor-cores 1
spark-examples-1.5.2-hadoop2.5.2.jar 10
4)查看3)的应用运行结果
5)使用scala shell完成下述操作
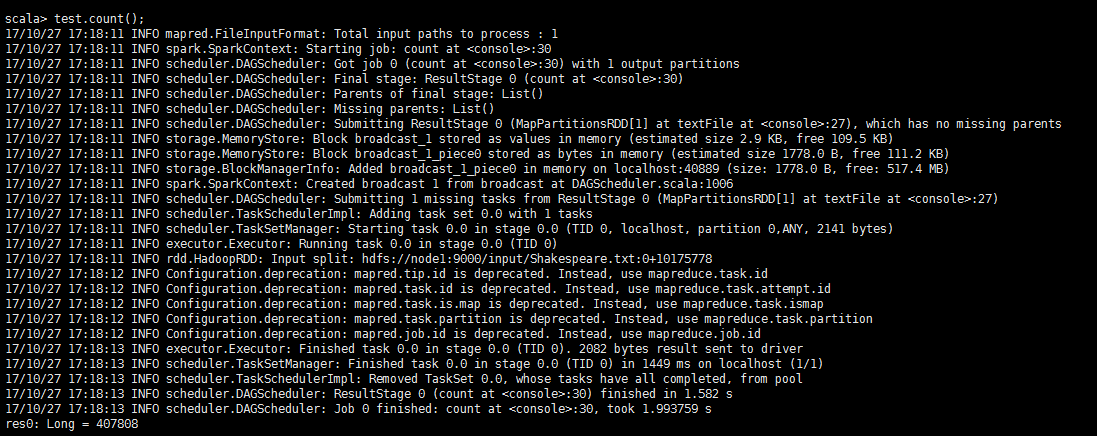
scala>val test= sc.textFile(“hdfs://node1:9000/input/ Shakespeare.txt”)
//读取hdfs上的文件,将其创建为一个名为test的RDD
scala>test.count()
//输出test的行数
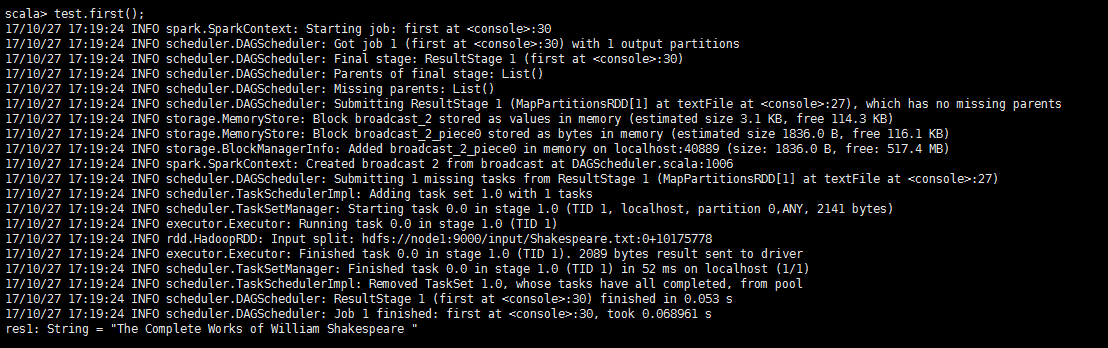
scala>test.first()
6)使用Spark完成上述文件中wordcount统计;
val test= sc.textFile("hdfs://node1:9000/input/Shakespeare.txt)
val wordCount = test.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
scala> wordCount.collect()
wordCount.collect()
相关资料:
链接:http://pan.baidu.com/s/1dFD7mdr 密码:xwu8
大数据(3):基于sogou.500w.utf8数据Hbase和Spark实践的更多相关文章
- 大数据(2):基于sogou.500w.utf8数据hive的实践
一.环境的搭建 1.安装配置mysql rpm –ivh MySQL-server-5.6.14.rpm rpm –ivh MySQL-client-5.6.14.rpm 启动mysql 创建hive ...
- 大数据(1):基于sogou.500w.utf8数据的MapReduce程序设计
环境:centos7+hadoop2.5.2 1.使用ECLIPS具打包运行WORDCOUNT实例,统计莎士比亚文集各单词计数(文件SHAKESPEARE.TXT). ①WorldCount.java ...
- hive和hbase本质区别——hbase本质是OLTP的nosql DB,而hive是OLAP 底层是hdfs,需从已有数据库同步数据到hdfs;hive可以用hbase中的数据,通过hive表映射到hbase表
对于hbase当前noSql数据库的一种,最常见的应用场景就是采集的网页数据的存储,由于是key-value型数据库,可以再扩展到各种key-value应用场景,如日志信息的存储,对于内容信息不需要完 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 大数据下基于Tensorflow框架的深度学习示例教程
近几年,信息时代的快速发展产生了海量数据,诞生了无数前沿的大数据技术与应用.在当今大数据时代的产业界,商业决策日益基于数据的分析作出.当数据膨胀到一定规模时,基于机器学习对海量复杂数据的分析更能产生较 ...
- 【T-BABY 夜谈大数据】基于内容的推荐算法
这个系列主要也是自己最近在研究大数据方向,所以边研究.开发也边整理相关的资料.网上的资料经常是碎片式的,如果要完整的看完可能需要同时看好几篇文章,所以我希望有兴趣的人能够更轻松和快速地学习相关的知识. ...
- SpringMVC + ehcache( ehcache-spring-annotations)基于注解的服务器端数据缓存
背景 声明,如果你不关心java缓存解决方案的全貌,只是急着解决问题,请略过背景部分. 在互联网应用中,由于并发量比传统的企业级应用会高出很多,所以处理大并发的问题就显得尤为重要.在硬件资源一定的情况 ...
- 基于IBM Bluemix的数据缓存应用实例
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka 摘要:IBM® Data Cache for Bluemix 是快速缓存服务.支持 Web 和 ...
- 使用C#处理基于比特流的数据
使用C#处理基于比特流的数据 0x00 起因 最近需要处理一些基于比特流的数据,计算机处理数据一般都是以byte(8bit)为单位的,使用BinaryReader读取的数据也是如此,即使读取bool型 ...
随机推荐
- Yaf框架的配置
http://www.laruence.com/manual/yaf.ini.html //先看一下惠新宸鸟哥yaf官网的配置说明 我们可以在php.ini中定义开发环节配置项,把本地开发设置成dev ...
- core java
ConsoleTest,这个程序如果在IDE里运行就会因无法获得控制台而报错 import java.io.Console; public class ConsoleTest { public sta ...
- es6之let和const命令的一些笔记
let和const命令 let命令 基本用法 let命令用来声明变量,声明的变量只在命令所在的代码块内有效.for循环中很适合使用let命令. 有必要理解的例子: var a = []; for (v ...
- kubernetes 命令使用
学会命令的查找和使用,而不是死记命令,记命令不如提高英文水平 1.kubernetes环境搭建完成后,kubernetes环境搭建参考http://www.cnblogs.com/sosogengdo ...
- elasticsearch-5.1.1使用snapshot接口备份索引
如果ES是集群,那么需要使用共享存储,支持的存储有:a.shared file systemb.S3c.HDFS 我使用的是第一种,NFS共享文件系统.这里要说一下权限问题,ES一般是使用 elast ...
- 内置函数--bin() oct() int() hex()
英文文档: bin(x) Convert an integer number to a binary string. The result is a valid Python expression. ...
- 搭建多系统yum服务器
一.多系统服务器搭建 1.首先挂载光盘 2.安装vsftp 3.使用rpm -ql vsftpd查看vsftpd安装时都产生了哪些文件,找到以.server结尾的文件路径.此文件的文件名就是vsftp ...
- 关于 frame的一些基本知识
关于 frame的一些基本知识只是摘抄了一部分,供初学者参考. b.帧速率: 帧速率是每秒显示的图像数.标准影片(NTSC) 是29.97 帧第秒 (fps),电影是每秒24 帧fps.欧洲标准是(P ...
- HighCharts之2D含有负值的面积图
HighCharts之2D含有负值的面积图 1.HighCharts之2D含有负值的面积图源码 AreaNegative.html: <!DOCTYPE html> <html> ...
- 错误代码: 1045 Access denied for user 'skyusers'@'%' (using password: YES)
1. 错误描述 GRANT ALL PRIVILEGES ON *.* TO root@"%" IDENTIFIED BY "."; 1 queries exe ...