通过java api统计hive库下的所有表的文件个数、文件大小
更新hadoop fs 命令实现:
[ss@db csv]$ hadoop fs -count /my_rc/my_hive_db/*
18/01/14 15:40:19 INFO hdfs.PeerCache: SocketCache disabled.
3 2 0 /my_rc/my_hive_db/.hive-staging_hive_2017-08-19_16-52-39_153_7217997288202811839-170149
2 0 0 /my_rc/my_hive_db/.hive-staging_hive_2018-01-03_15-23-10_240_5147839610865108930-52517
1 0 0 /my_rc/my_hive_db/BusinessGtUser
4 1 321008 /my_rc/my_hive_db/ZJ2_SenseSta
1 1 143 /my_rc/my_hive_db/anthgain
1 1 27228 /my_rc/my_hive_db/anthgainpoint
1 1 70 /my_rc/my_hive_db/antvgain
1 1 27429 /my_rc/my_hive_db/antvgainpoint
通过hadoop fs -du 或者 hadoop fs -count只能统计指定的某个hdfs路径(hive表目录)的总文件个数及文件的大小,但是通过hadoop命令没有办法实现批量处理hive中多个表一次进行统计,如果一次性统计多个hive表目录的文件个数、文件总大小只能通过java程序使用hadoop api实现。
package com.my.hdfsopt; import java.io.FileNotFoundException;
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; public class HdfsPathMonitor {
// submit shell
/*
* main类的路径不需要指定,否则会被认为是参数传递进入。
* yarn jar /app/m_user1/service/Hangzhou_HdfsFileMananger.jar /hive_tenant_account/hivedbname/
*/
public static void main(String[] args) throws Exception {
System.out.println("the args is " + String.join(",", args));
String dirPath = args[0]; Configuration conf = new Configuration();
/*
* <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value>
* </property>
*/
conf.set("fs.defaultFS", "hdfs://mycluster"); FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path(dirPath); // 获取文件列表
FileStatus[] files = fileSystem.listStatus(path);
if (files == null || files.length == 0) {
throw new FileNotFoundException("Cannot access " + dirPath + ": No such file or directory.");
} System.out.println("dirpath \t total file size \t total file count");
for (int i = 0; i < files.length; i++) {
String pathStr = files[i].getPath().toString(); FileSystem fs = files[i].getPath().getFileSystem(conf);
long totalSize = fs.getContentSummary(files[i].getPath()).getLength();
long totalFileCount = listAll(conf, files[i].getPath());
fs.close(); System.out.println(("".equals(pathStr) ? "." : pathStr) + "\t" + totalSize + "\t" + totalFileCount);
}
} /**
* @Title: listAll @Description: 列出目录下所有文件 @return void 返回类型 @throws
*/
public static Long listAll(Configuration conf, Path path) throws IOException {
long totalFileCount = 0;
FileSystem fs = FileSystem.get(conf); if (fs.exists(path)) {
FileStatus[] stats = fs.listStatus(path);
for (int i = 0; i < stats.length; ++i) {
if (!stats[i].isDir()) {
// regular file
// System.out.println(stats[i].getPath().toString());
totalFileCount++;
} else {
// dir
// System.out.println(stats[i].getPath().toString());
totalFileCount += listAll(conf, stats[i].getPath());
}
}
}
fs.close(); return totalFileCount;
} }
执行命令:
yarn jar /app/m_user1/tommyduan_service/Hangzhou_HdfsFileMananger.jar /hive_tenant_account/hivedbname/
执行结果:
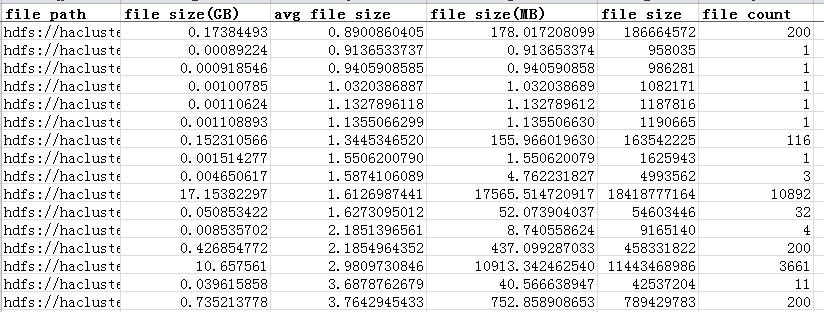
通过java api统计hive库下的所有表的文件个数、文件大小的更多相关文章
- mysql下批量清空某个库下的所有表(库不要删除,保留空库)
总所周知,mysql下要想删除某个库下的某张表,只需要切换到该库下,执行语句"drop table tablename"即可删除!但若是该库下有成百上千张表,要是再这样一次次执行d ...
- mysql5.7 mysql库下面的user表没有password字段无法修改密码
如题所述,mysql5.7 mysql库下面的user表没有password字段无法修改密码, 5.7版本已经不再使用password来作为密码的字段了 而改成了authentication_st ...
- Java API操作HA方式下的Hadoop
通过java api连接Hadoop集群时,如果集群支持HA方式,那么可以通过如下方式设置来自动切换到活动的master节点上.其中,ClusterName 是可以任意指定的,跟集群配置无关,dfs. ...
- MySQL数据库中统计一个库中的所有表的行数?
今天公司两个远端的数据库主从同步有点问题,查看下wordpress库下所有表的表的条目? mysql> use information_schema;Database changedmysql& ...
- Centos下查看当前目录大小及文件个数
查看目录及其包含的文件的大小 du -ch directory 查看当前目录下文件的个数 ls -l | grep "^-" | wc -l 查看当前目录下以.jpg为后缀文件的个 ...
- 统计hive库表在具体下所有分区大小
1 查询具体表分区大小,以字节展示 hadoop fs -du /user/hive/warehouse/treasury.db/dm_user_excercise > dm_user_exce ...
- 使用hive客户端java api读写hive集群上的信息
上文介绍了hdfs集群信息的读取方式,本文说hive 1.先解决依赖 <properties> <hive.version>1.2.1</hive.version> ...
- Spark:java api读取hdfs目录下多个文件
需求: 由于一个大文件,在spark中加载性能比较差.于是把一个大文件拆分为多个小文件后上传到hdfs,然而在spark2.2下如何加载某个目录下多个文件呢? public class SparkJo ...
- windows上使用metastore client java api链接hive metastore问题
https://github.com/sdravida/hadoop2.6_Win_x64 下载winutils.exe 添加到path中
随机推荐
- linux(ubuntu)环境下安装IDEA
想调试java虚拟机内存溢出的情况,在调试过程中总会出现一些不可预见的状况,正好在学linux,在windows上安装了虚拟机,安装的镜像是ubuntu(乌班图)装在了虚拟机中,装在虚拟机中好处是即使 ...
- 17.C++-string字符串类(详解)
C++字符串string类 在C语言里,字符串是用字符数组来表示的,而对于应用层而言,会经常用到字符串,而继续使用字符数组,就使得效率非常低. 所以在C++标准库里,通过类string从新自定义了字符 ...
- 常用的Maven依赖
一.数据库类型 1.mysql驱动 <!-- mysql驱动支持 --> <dependency> <groupId>mysql</groupId> & ...
- 笔记:Maven 依赖及配置详解
dependencies 配置节,主要用于配置项目依赖的其他包,其子节点 dependency 用来配置具体依赖包,有groupId.artifactId.version.scope等子节点来说明,配 ...
- KVM之五:KVM日常管理常用命令
1.查看.编辑及备份KVM 虚拟机配置文件 以及查看KVM 状态: 1.1.KVM 虚拟机默认的配置文件在 /etc/libvirt/qemu 目录下,默认是以虚拟机名称命名的.xml 文件,如下,: ...
- Vue的组件
1,局部组件就是在Vue对象内部注册的构造器 <!DOCTYPE html> <html lang="en"> <head> <meta ...
- vue/axios请求拦截
import axios from 'axios';import { Message } from 'element-ui';import Cookies from 'js-cookie';impor ...
- Oracle中死锁与等待
在数据库中有两种基本的锁类型:排它锁(Exclusive Locks,即X锁)和共享锁(即S锁).当数据对象被加上排它锁时,其他的事务不能不 能对它读取和修改.加了共享锁的数据对象可以被其他事务读取 ...
- 【Swift】iOS导航栏错乱的原因
#iOS开发高级技巧#导航栏错乱,也就是导航栏的显示效果与内容区不匹配,引发原因很多,其中最重要的有两个原因: 1.在viewwillappear,viewwilldisappear两个函数中,设置导 ...
- 【iOS】swift-如何理解 if let 与guard?
著作权归作者所有. 商业转载请联系作者获得授权,非商业转载请注明出处. 作者:黄兢成 链接:http://www.zhihu.com/question/36448325/answer/68614858 ...