hive:框架理解

|
Hive
|
RDBMS
|
|
|
查询语言
|
HQL
|
SQL
|
|
数据存储
|
HDFS
|
Raw Device or Local FS
|
|
执行
|
MapReduce
|
Excutor
|
|
执行延迟
|
高
|
低
|
|
处理数据规模
|
大
|
小
|
|
索引
|
0.8版本后加入位图索引
|
有复杂的索引
|
Hive是基于Hadoop平台的,它提供了类似SQL一样的查询语言HQL。有了Hive,如果使用过SQL语言,并且不理解Hadoop MapReduce运行原理,也就无法通过编程来实现MR,但是你仍然可以很容易地编写出特定查询分析的HQL语句,通过使用类似SQL的语法,将HQL查询语句提交Hive系统执行查询分析,最终Hive会帮你转换成底层Hadoop能够理解的MR Job。
对于最基本的HQL查询我们不再累述,这里主要说明Hive中进行统计分析时使用到的JOIN操作。在说明Hive JOIN之前,我们先简单说明一下,Hadoop执行MR Job的基本过程(运行机制),能更好的帮助我们理解HQL转换到底层的MR Job后是如何执行的。我们重点说明MapReduce执行过程中,从Map端到Reduce端这个过程(Shuffle)的执行情况,如图所示(来自《Hadoop: The Definitive Guide》)
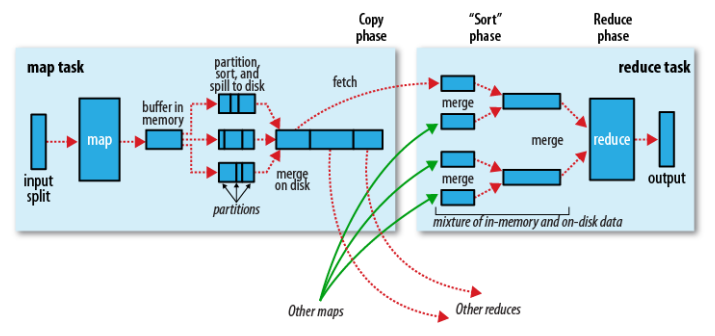
基本执行过程,描述如下:
一个InputSplit输入到map,会运行我们实现的Mapper的处理逻辑,对数据进行映射操作。
map输出时,会首先将输出中间结果写入到map自带的buffer中(buffer默认大小为100M,可以通过io.sort.mb配置)。
map自带的buffer使用容量达到一定门限(默认0.80或80%,可以通过io.sort.spill.percent配置),一个后台线程会准备将buffer中的数据写入到磁盘。
这个后台线程在将buffer中数据写入磁盘之前,会首先将buffer中的数据进行partition(分区,partition数为Reducer的个数),对于每个的数据会基于Key进行一个in-memory排序。
排序后,会检查是否配置了Combiner,如果配置了则直接作用到已排序的每个partition的数据上,对map输出进行化简压缩(这样写入磁盘的数据量就会减少,降低I/O操作开销)。
现在可以将经过处理的buffer中的数据写入磁盘,生成一个文件(每次buffer容量达到设置的门限,都会对应着一个写入到磁盘的文件)。
map任务结束之前,会对输出的多个文件进行合并操作,合并成一个文件(若map输出至少3个文件,在多个文件合并后写入之前,如果配置了Combiner,则会运行来化简压缩输出的数据,文件个数可以通过min.num.splits.for.combine配置;如果指定了压缩map输出,这里会根据配置对数据进行压缩写入磁盘),这个文件仍然保持partition和排序的状态。
reduce阶段,每个reduce任务开始从多个map上拷贝属于自己partition(map阶段已经做好partition,而且每个reduce任务知道应该拷贝哪个partition;拷贝过程是在不同节点之间,Reducer上拷贝线程基于HTTP来通过网络传输数据)。
每个reduce任务拷贝的map任务结果的指定partition,也是先将数据放入到自带的一个buffer中(buffer默认大小为Heap内存的70%,可以通过mapred.job.shuffle.input.buffer.percent配置),如果配置了map结果进行压缩,则这时要先将数据解压缩后放入buffer中。
reduce自带的buffer使用容量达到一定门限(默认0.66或66%,可以通过mapred.job.shuffle.merge.percent配置),或者buffer中存放的map的输出的数量达到一定门限(默认1000,可以通过mapred.inmem.merge.threshold配置),buffer中的数据将会被写入到磁盘中。
在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件,这时开始执行合并操作,并保持每个map输出数据中Key的有序性,将多个文件合并成一个文件(在reduce端可能存在buffer和磁盘上都有数据的情况,这样在buffer中的数据可以减少一定量的I/O写入操作开销)。
最后,执行reduce阶段,运行我们实现的Reducer中化简逻辑,最终将结果直接输出到HDFS中(因为Reducer运行在DataNode上,输出结果的第一个replica直接在存储在本地节点上)。
通过上面的描述我们看到,在MR执行过程中,存在Shuffle过程的MR需要在网络中的节点之间(Mapper节点和Reducer节点)拷贝数据,如果传输的数据量很大会造成一定的网络开销。而且,Map端和Reduce端都会通过一个特定的buffer来在内存中临时缓存数据,如果无法根据实际应用场景中数据的规模来使用Hive,尤其是执行表的JOIN操作,有可能很浪费资源,降低了系统处理任务的效率,还可能因为内存不足造成OOME问题,导致计算任务失败。
下面,我们说明Hive中的JOIN操作,针对不同的JOIN方式,应该如何来实现和优化:
生成一个MR Job
多表连接,如果多个表中每个表都使用同一个列进行连接(出现在JOIN子句中),则只会生成一个MR Job,例如:
1 |
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) |
三个表a、b、c都分别使用了同一个字段进行连接,亦即同一个字段同时出现在两个JOIN子句中,从而只生成一个MR Job。
生成多个MR Job
多表连接,如果多表中,其中存在一个表使用了至少2个字段进行连接(同一个表的至少2个列出现在JOIN子句中),则会至少生成2个MR Job,例如:
1 |
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) |
三个表基于2个字段进行连接,这两个字段b.key1和b.key2同时出现在b表中。连接的过程是这样的:首先a和b表基于a.key和b.key1进行连接,对应着第一个MR Job;表a和b连接的结果,再和c进行连接,对应着第二个MR Job。
hive:框架理解的更多相关文章
- ssm框架理解
SSM框架理解 最近两星期一直在学JavaEE的MVC框架,因为之前学校开的JavaEE课程就一直学的吊儿郎当的,所以现在真正需要掌握就非常手忙脚乱,在此记录下这段时间学习的感悟,如有错误,希望大牛毫 ...
- SSM框架理解(转)
SSM框架理解 最近两星期一直在学JavaEE的MVC框架,因为之前学校开的JavaEE课程就一直学的吊儿郎当的,所以现在真正需要掌握就非常手忙脚乱,在此记录下这段时间学习的感悟,如有错误,希望大牛毫 ...
- mybatis中两种取值方式?谈谈Spring框架理解?
1.mybatis中两种取值方式? 回答:Mybatis中取值方式有几种?各自区别是什么? Mybatis取值方式就是说在Mapper文件中获取service传过来的值的方法,总共有两种方式,通过 $ ...
- Flask 框架理解(一)
Flask 框架理解(一) web 服务器 , web 框架 以及 WSGI 这里说的 web 服务器特指纯粹的 python HTTP 服务器(比如 Gunicorn,而不是 Apache,Ngin ...
- Hive框架基础(二)
* Hive框架基础(二) 我们继续讨论hive框架 * Hive的外部表与内部表 内部表:hive默认创建的是内部表 例如: create table table001 (name string , ...
- Hive框架基础(一)
* Hive框架基础(一) 一句话:学习Hive有毛用? 那么解释一下 毛用: * 操作接口采用类SQL语法,提供快速开发的能力(不会Java也可以玩运算) * 避免了去写MapReduce,减少开发 ...
- 遵循统一的机器学习框架理解高斯混合模型(GMM)
遵循统一的机器学习框架理解高斯混合模型(GMM) 一.前言 我的博客仅记录我的观点和思考过程.欢迎大家指出我思考的盲点,更希望大家能有自己的理解. 本文参考了网络上诸多资料,特别是B站UPshuhua ...
- 遵循统一的机器学习框架理解SVM
遵循统一的机器学习框架理解SVM 一.前言 我的博客仅记录我的观点和思考过程.欢迎大家指出我思考的盲点,更希望大家能有自己的理解. 本文参考了李宏毅教授讲解SVM的课程和李航大大的统计学习方法. 二. ...
- Web框架理解
目录 1.web框架理解 2.http工作原理 3.通过函数实现浏览器和服务端通信案例 4.服务器程序和引用程序理解 5.jinja2渲染模板案例 6.Djan ...
- MVVM框架理解
MVC框架 将整个前端页面分成View,Controller,Modal,视图上发生变化,通过Controller(控件)将响应传入到Model(数据源),由数据源改变View上面的数据. 整个过程看 ...
随机推荐
- Linux安装JDK步骤
Linux安装JDK步骤 1.先从官网下载JDK安装包,我下载的是:jdk-8u131-linux-x64.tar.gz版本 2.在usr下创建java文件夹 # mkdir /usr/java 3. ...
- 理解Object.defineProperty的作用
对象是由多个名/值对组成的无序的集合.对象中每个属性对应任意类型的值.定义对象可以使用构造函数或字面量的形式: var obj = new Object; //obj = {} obj.name = ...
- python --- queue模块使用
1. 什么是队列? 学过数据结构的人都知道,如果不知道队列,请Google(或百度). 2. 在python中什么是多生产者,多消费模型? 简单来说,就是一边生产(多个生产者),一边消费(多个消费者) ...
- 面向对象_05【类的继承:extends、重写父类】
类的继承:现有类的基础上构建一个新的类,构建出来的类被称作子类,子类可继承父类的属性和方法. 什么时候定义继承?当类与类之间存在着所属关系的时候,就定义继承.xxx是yyy中的一种==>xxx ...
- selenium模拟浏览器对搜狗微信文章进行爬取
在上一篇博客中使用redis所维护的代理池抓取微信文章,开始运行良好,之后运行时总是会报501错误,我用浏览器打开网页又能正常打开,调试了好多次都还是会出错,既然这种方法出错,那就用selenium模 ...
- CentOS 6.3 SSH连接时很慢的解决方法
SSH的配置文件,默认开启了DNS反向解析,这使得处于同一个局域网下的终端,在SSH到服务器的时候异常缓慢,如果从是外网SSH到服务器的话,速度则是正常的.我们只需要关闭DNS反向解析即可. 修改/e ...
- HDU [P3605] Escape
二分图多重匹配 改进版的匈牙利,加入了一个cnt数组作为找到增广路的标志 本题有一个重要的优化见注释 #include <iostream> #include <cstdio> ...
- 【原创】 c#单文件绿色资源自更新
先引用dnlib.dll 更新程序先fody成一个文件 放置主程序资源文件 更新程序.exe #region using System; using System.Diagnostics; using ...
- linux常用命令(不断更新)
睡眠命令(第一步可省去): 1.查看你的系统支持什么模式:cat /sys/power/state(我的系统为:freeze mem disk) 2.切换到管理员模式下,执行命令:echo " ...
- MySQL 存储过程的简单使用
首先创建一张 students 表 SQL脚本如下: create table students( id int primary key auto_increment, age int, name v ...