python构造一个freebuf新闻发送脚本
前言:
放假学习完web漏洞后。想写一个脚本
然而自己菜无法像大佬们一样写出牛逼的东西
尝试写了,都以失败告终。
还有一个原因:上学时间不能及时看到,自己也比较懒。邮件能提醒自己。
需要安装的模块:
requests模块
smtplib模块
email模块
正文:
这个脚本的原理其实很简单把freebuf上的a标签抓取
然后获去href里面的链接与title的标题写入到txt,读取txt。发送邮箱
架空txt。间隔12个小时发一次,加上循环。

代码:
import requests
from bs4 import BeautifulSoup
import smtplib
import re
from email.mime.text import MIMEText
from email.header import Header
import time
while True:
def freebuf():
url="http://www.freebuf.com"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
res=requests.get(url,headers)
bw=res.content.decode('utf-8')
allsectool=re.findall('<a href="http://www.freebuf.com/sectool/.*?.html" target="_blank" title=".*?">',bw)
allsectoolurl=BeautifulSoup(str(allsectool),'html.parser')
osw=allsectoolurl.find_all('a')
for u1 in osw:
u3=u1.get('href')
u4=u1.get('title')
print(u3,"标题:",u4,file=open('freebuf.txt','a',encoding='utf-8')) networkall=re.findall('<a href="http://www.freebuf.com/articles/network/.*?.html" target="_blank" title=".*?">',bw)
neturl=BeautifulSoup(str(networkall),'html.parser')
netus=neturl.find_all('a')
for y in netus:
neturls=y.get('href')
netiles=y.get('title')
print(neturls,"标题:",netiles,file=open('freebuf.txt','a',encoding='utf-8')) jobsall=re.findall('<a href="http://www.freebuf.com/jobs/.*?.html" target="_blank" title=".*?">',bw)
jobsurl=BeautifulSoup(str(jobsall),'html.parser')
jobsurly=jobsurl.find_all('a')
for m in jobsurly:
m2=m.get('href')
m3=m.get('title')
print(m2,"标题:",m3,file=open('freebuf.txt','a',encoding='utf-8')) newsall=re.findall('<a href="http://www.freebuf.com/news/.*?.html" target="_blank" title=".*?">',bw)
newsurl=BeautifulSoup(str(newsall),'html.parser')
usd=newsurl.find_all('a')
for g2 in usd:
psw=g2.get('href')
pswt=g2.get('title')
print(psw,"标题:",pswt,file=open('freebuf.txt','a',encoding='utf-8')) vulsall=re.findall('<a href="http://www.freebuf.com/vuls/.*?.html" target="_blank" title=".*?">',bw)
vulsallurl=BeautifulSoup(str(vulsall),'html.parser')
gew=vulsallurl.find_all('a')
for hp in gew:
hpw=hp.get('href')
gpw2=hp.get('title')
print(hpw,"标题:",gpw2,file=open('freebuf.txt','a',encoding='utf-8')) system=re.findall('<a href="http://www.freebuf.com/articles/system/166121.html" target="_blank" title=".*?">',bw)
systemurl=BeautifulSoup(str(system),'html.parser')
sys=systemurl.find_all('a')
for v in sys:
v1=v.get('href')
v2=v.get('title')
print(v1,"标题:",v2,file=open('freebuf.txt','a',encoding='utf-8')) freebuf() def Email():
try:
lk = open('freebuf.txt', 'r',encoding='utf-8')
pg = lk.read()
lk.close()
except Exception as g:
print('[-]报错', g)
sender="发送人"
recivs="接收人"
message=MIMEText('''
freebuf新闻快报\n
{}\n
'''.format(str(pg)),'plain','utf-8')
message['From']=Header('发送人')
sub="freebuf安全快报"
message['subject']=Header(sub,'utf-8')
try:
smtp=smtplib.SMTP()
smtp.connect("smtp服务",25)
smtp.login("你自己的邮箱","你自己的邮箱密码")
smtp.sendmail(sender,recivs,message.as_string())
print('[+]发送成功')
except Exception as l:
print('[-]发送失败',l) ws=open('freebuf.txt','w')
Email()
time.sleep(43200)
运行截图

qq邮箱接收到的:
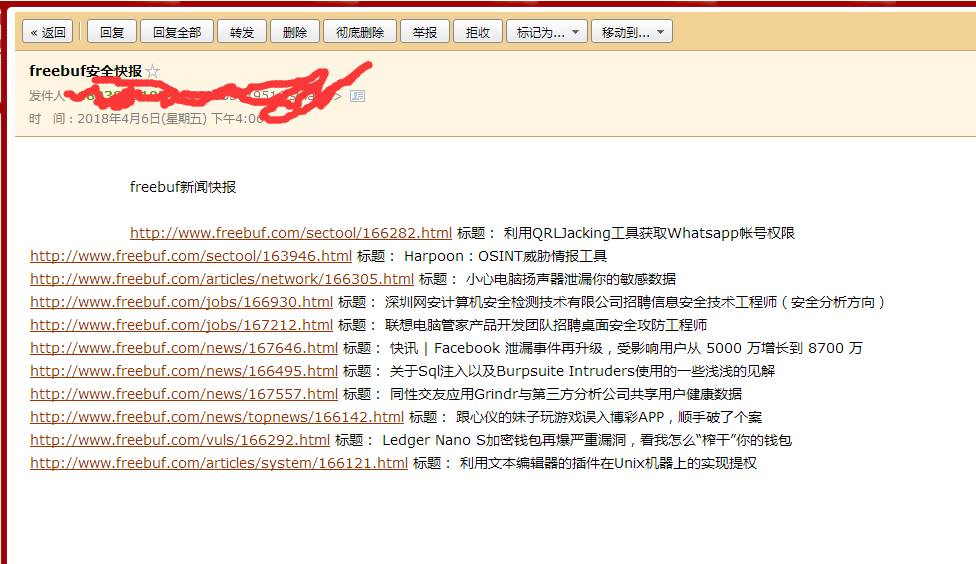
可以根据自己的喜好去抓取。
python构造一个freebuf新闻发送脚本的更多相关文章
- 用python写一个自动化盲注脚本
前言 当我们进行SQL注入攻击时,当发现无法进行union注入或者报错等注入,那么,就需要考虑盲注了,当我们进行盲注时,需要通过页面的反馈(布尔盲注)或者相应时间(时间盲注),来一个字符一个字符的进行 ...
- python构造一个http请求
我们经常会用python来进行抓包,模拟登陆等等, 势必要构造http请求包. http的request通常有4个方法get,post,put,delete,分别对应于查询,更新,添加,删除.我们经常 ...
- Python 网络爬虫(新闻采集脚本)
=====================爬虫原理===================== 通过Python访问新闻首页,获取首页所有新闻链接,并存放至URL集合中. 逐一取出集合中的URL,并访问 ...
- python写一个防御DDos的脚本(请安好环境否则无法实验)
起因: 居然有ddos脚本,怎么可以没防御ddos的脚本! 开始: 1.请执行 install.py安装好DDos-defalte,会在root目录下多出这个文件夹 代码: 2.然后执行fyddos. ...
- python写一个翻译的小脚本
起因: 想着上学看不懂English的PDF感慨万分........ 然后就有了翻译的脚本. 截图: 代码: #-*- coding:'utf-8' -*- import requests impor ...
- Python写一个京东抢券脚本
最近看到京东图书每天有优惠券发放,满200减100,诱惑还是蛮大的.反正自己抢不到,想着写个脚本试试. 几个关键步骤 获取优惠券的url 直接审查元素 获取cookie 通过本地代理,比如BurpSu ...
- python 构造一个可以返回多个值的函数
为了能返回多个值,函数直接return 一个元组就行了 看上去返回了多个值,实际上是先创建了一个元组然后返回的.这个语法看上去比较奇怪,实际上我们使用的是逗号来生成一个元组,而不是用括号 >&g ...
- Python 构造一个可接受任意数量参数的函数
为了能让一个函数接受任意数量的位置参数,可以使用一个* 参数 在这个例子中,rest 是由所有其他位置参数组成的元组.然后我们在代码中把它当成了一个序列来进行后续的计算
- 【Python】使用cmd模块构造一个带有后台线程的交互命令行界面
最近写一些测试工具,实在懒得搞GUI,然后意识到python有一个自带模块叫cmd,用了用发现简直是救星. 1. 基本用法 cmd模块很容易学到,基本的用法比较简单,继承模块下的Cmd类,添加需要的功 ...
随机推荐
- javascript三角函数的使用
其实很多编程语言里面都有数学函数,而且很多数学函数包括三角函数,只不过有些时候可能我们用的并不多,我最近在做一个h5的游戏,其中有一个需求就是射击的枪支需要更随鼠标变换位置,鼠标移动到什么地方,炮口就 ...
- 应用canvas绘制动态时钟--每秒自动动态更新时间
使用canvas绘制时钟 下文是部分代码,完整代码参照:https://github.com/lemoncool/canvas-clock,可直接下载. 首先看一下效果图:每隔一秒会动态更新时间 一. ...
- c#抽取pdf文档标题(2)
public class IETitle { public static List<WordInfo> WordsInfo = new List<WordInfo>(); pr ...
- TypeScript入门知识五(面向对象特性二)
1.泛型(generic) 参数化的类型,一般用来限制集合的内容 class Person { constructor(private name: string) { } work() { }}var ...
- RocketMQ与kafka对比(官方)
淘宝内部的交易系统使用了淘宝自主研发的Notify消息中间件,使用Mysql作为消息存储媒介,可完全水平扩容,为了进一步降低成本,我们认为存储部分可以进一步优化,2011年初,Linkin开源了Kaf ...
- 洛谷 P1564 膜拜
题目出处 s[i]表示前i个人对神牛的膜拜情况,如果膜拜神牛甲则s[i]=s[i-1]+1否则s[i]=s[i-1]-1.那么如果|s[i]-s[j]|<=m或者=i-j+1(也就是人数差不超过 ...
- doT.js——前端javascript模板引擎问题备忘录
我手里维护的一个项目,遇到一个问题:原项目的开发人员在Javascript中,大量的拼接HTML,导致代码极丑,极难维护.他们怎么能够忍受的了这么丑陋.拙劣的代码呢,也许是他们的忍受力极强,压根就没想 ...
- java中四种操作xml方式的比较
1)DOM(JAXP Crimson解析器) DOM是用与平台和语言无关的方式表示XML文档的官方W3C标准.DOM是以层次结构组织的节点或信息片断的集合.这个层次结构允许开发人员在树中寻找特定信息. ...
- python 全栈开发,Day4(正式)
一.列表 列表是python中的基础数据类型之一,它是以[]括起来,每个元素以逗号隔开,而且他里面可以存放各种数据类型比如: li = ['alex',123,Ture,(1,2,3,'wusir') ...
- 一步步教你开发、部署第一个去中心化应用(Dapp) - 宠物商店
今天我们来编写一个完整的去中心化(区块链)应用(Dapps), 本文可以和编写智能合约结合起来看. 写在前面 阅读本文前,你应该对以太坊.智能合约有所了解,如果你还不了解,建议你先看以太坊是什么除此之 ...