Ambari Log Search
文章作者:luxianghao
文章来源:http://www.cnblogs.com/luxianghao/p/8630195.html 转载请注明,谢谢合作。
免责声明:文章内容仅代表个人观点,如有不当,欢迎指正。
---
一 简介
Ambari Log Search是Ambari社区从2.4版本推出的一个新组件,主要功能包括日志监控、收集、分析,并为收集的日志建立索引从而进行故障排查,日志搜索、日志审计等,官方介绍参考这里
二 架构
Log Search拥有两个组件:Log Search Portal(server + web UI)和Log Feeder。
Log Feeder分布在所监控服务的多个主机上,负责监控特定的日志文件并把解析过的日志发送到Solr,用户使用Log Search Portal的web UI来查询日志,web UI发送请求给Log Search Portal的后端server,后端server再发送query请求给Solr服务,最终实现日志查询。
Log Search Portal后端server集成了spring-data-solr,并利用spring-data-solr作为Solr的client和Solr交互。
其中,Solr是Apache的一个开源搜索平台, Log Search依赖Ambari Infra服务,Ambari Infra服务中含有Solr组件。
具体架构图如下

三 功能预览
1 历史操作日志存储
Ambari所管理的组件在Ambari Server上的历史操作日志将被保存,这对故障排查,历史回故,场景再现会比较有帮助。
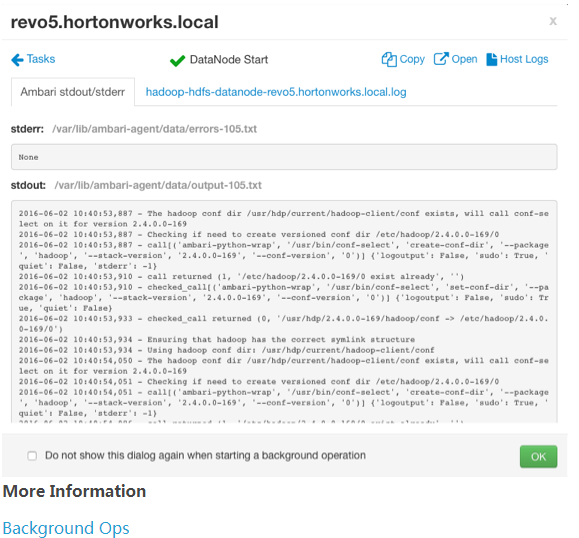
2 主机相关组件日志快速查看
Ambari Server所管理的主机的的日志在的web端也将很容易查看,并且可以通过超链接直接跳转到Log Search UI。
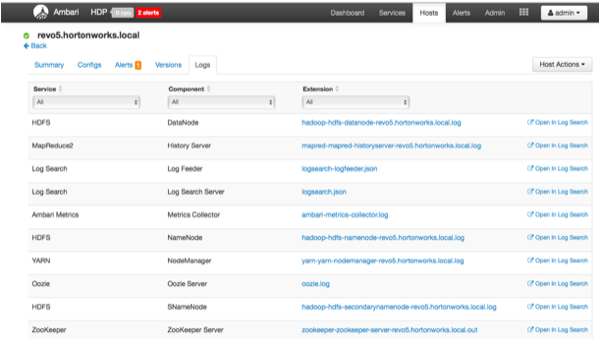
3 Log Search UI
1)故障排查
选择Log Search UI的Troubleshoting标签,如果HDFS有故障,正常情况下ERROR,FATAL日志的数量将会显著增加,那么你可以选择HDFS服务和相应的时间段,并点击GO to Logs,Log Search会自动查询所有HDFS相关的组件的日志,然后你就可以方便的查看日志,并高效的debug了。
Tips:有故障排查经验的同学肯定知道,一般情况下服务出现问题时,你都要先搜寻目标主机,然后到对应的机器上的对应目录打开对应的日志文件,查找ERROR或者FATAL日志,分析日志进行故障排查,有了Log Search我们会省去很多中间环节,为我们的故障排查赢得宝贵的时间,从而快人一步,保证我们服务的稳定性。

2)查询服务日志
选择Log Search UI的Service Logs标签,用户能够在一个页面快速的查看和搜索相关服务日志,用户可以通过时间、主机、日志级别、组件类型、日志存放路径、关键词等做快速查询,同时页面上也会统计不同时间、不同级别的日志情况
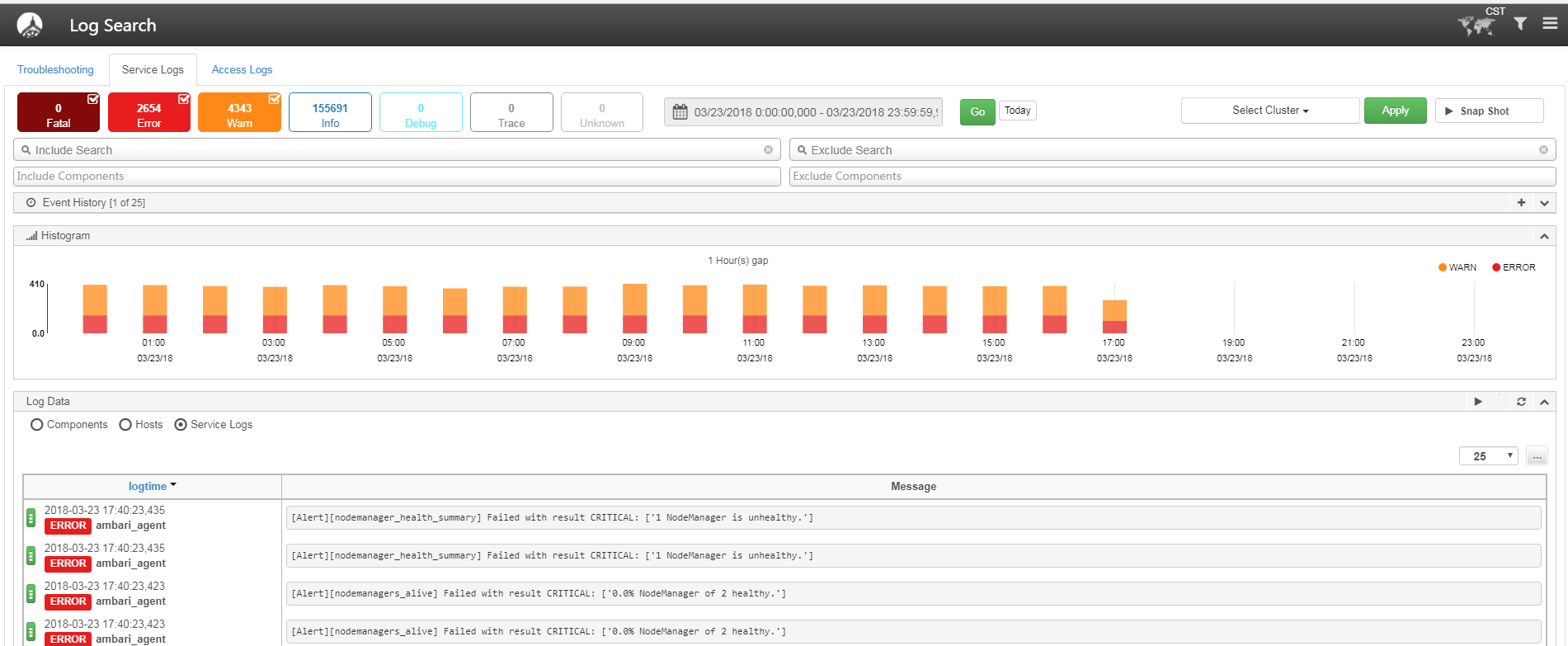
3)查询审计日志
选择Log Search UI的Access Logs标签,用户能方便的查看审计日志,例如HDFS,你可以方便的看到是哪个用户、哪个目录、哪段时间的访问频率比较高,然后可以做相关的资源控制,冷热数据分离,这些都是和成本等息息相关的,相信这个功能也是很有必要的。
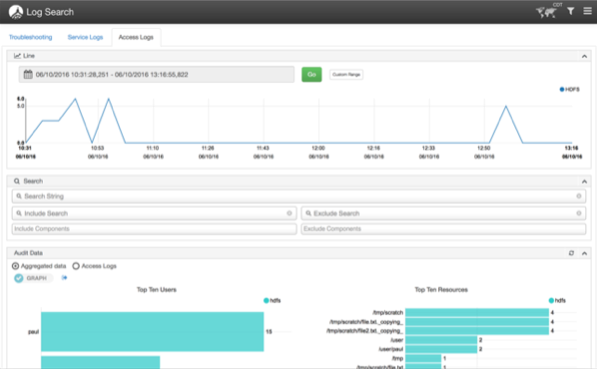
四 添加自定义组件
本节主要介绍下怎样在Log Search中添加一个自定义组件,并监控新的日志文件。
为了定义应该监控哪一个文件,怎样解析这些文件,你需要定义一些相关的输入日志数据的配置,服务部署好后,这些配置可以在/etc/ambari-logsearch-logfeeder/conf/logfeeder.properties中的logfeeder.config.files属性中找到。
如果你添加了一个自定义的服务(添加自定义服务参考这里),为了在Log Search中也支持这个服务,你需要在定义这个服务的configuration目录中添加*-logsearch-conf.xml的配置文件,*可以是自定义的名字,Ambari会根据*在 /etc/ambari-logsearch-logfeeder/conf/产生一个input.config-*.json的文件,*-logsearch-conf.xml中应该包含如下3个属性,
- service_name
- component_mappings
- content
第一个属性是service_name,这是自定义服务在Log Search中的标签,它也将在Log Search UI的troubleshooting的web页面上显示。
第二个是component_mapings, 这很重要,原因如下:
1 )你在Log Search portal上点击自定义服务标签的时候,它会选择合适的组件去过滤;
2) 需要把Ambari组件和制定的logIds做个映射,你也会看到Ambari的组件名和Log Search的名字是不一样的
例如ZOOKEEPER_SERVER <-> zookeeper_server
对一个Ambari组件来说,它可能有多个Logids,因为一个组件可能有多个日志文件需要监控。
第三个属性是content,他是一个在logfeeder启动的时候会生成的一个配置文件模板,如果你在集群中新添加了一个带有*-logsearch-conf 配置的服务,你需要重启下Log Feeder。其中,
input描述了被Log Feeder监控的日志文件;
"rowtype"为service;
"type"为logid;
"path"为日志位置的表达式,支持正则,在例子中你可以看到path对应的是python代码,这个可以用来从Ambari配置里获取zookeeper的日志目录,如果日志目录会被更改这个功能就比较重要了;
filter模块里你应该选择"grok", 也支持"json",不过这个只有在你的classpath里有logsearch-log4j-appender才能正常工作,在Grok里你可以定义每行日志应该怎么去解析,每一个field需要映射成为solr的field;
multiline_pattern 如果这个模式匹配上,意味着在日志中的行会被追加到上一行;
message_pattern定义了怎样解析指定的field并映射成为Solr field, 这里边"logtime"和"log_message"是必须的,"level"是可选的,但是推荐使用。
解析完成后,你可以在"post_map_values"里修改映射,例子里你可以看到,我们用指定的形式对日期重新做了映射,以便在solr里以指定的格式存储
更多关于input配置的可以参考这里,
为了找出针对你自己的日志文件的更合适的表达式,你可以使用这个,
在Log Search里也有一些内建的grok表达式,你可以在这里找到。
配置例子
<configuration supports_final="false" supports_adding_forbidden="true">
<property>
<name>service_name</name>
<display-name>Service name</display-name>
<description>Service name for Logsearch Portal (label)</description>
<value>Zookeeper</value>
<on-ambari-upgrade add="true"/>
</property>
<property>
<name>component_mappings</name>
<display-name>Component mapping</display-name>
<description>Logsearch component logid mapping list (e.g.: COMPONENT1:logid1,logid2;COMPONENT2:logid3)</description>
<value>ZOOKEEPER_SERVER:zookeeper</value>
<on-ambari-upgrade add="true"/>
</property>
<property>
<name>content</name>
<display-name>Logfeeder Config</display-name>
<description>Metadata jinja template for Logfeeder which contains grok patterns for reading service specific logs.</description>
<value>{ "input":[
{ "type":"zookeeper",
"rowtype":"service",
"path":"{{default('/configurations/zookeeper-env/zk_log_dir', '/var/log/zookeeper')}}/zookeeper*.log"} ],
"filter":[ {
"filter":"grok",
"conditions":{
"fields":{"type":["zookeeper"]}
},
"log4j_format":"%d{ISO8601} - %-5p [%t:%C{1}@%L] - %m%n", "multiline_pattern":"^(%{TIMESTAMP_ISO8601:logtime})",
"message_pattern":"(?m)^%{TIMESTAMP_ISO8601:logtime}%{SPACE}-%{SPACE}%{LOGLEVEL:level}%{SPACE}\\[%{DATA:thread_name}\\@%{INT:line_number}\\]%{SPACE}-%{SPACE}%{GREEDYDATA:log_message}",
"post_map_values": {
"logtime": {
"map_date":{
"target_date_pattern":"yyyy-MM-dd HH:mm:ss,SSS"
}
}
}
}
]}
</value>
<value-attributes>
<type>content</type>
<show-property-name>false</show-property-name>
</value-attributes>
<on-ambari-upgrade add="true"/>
</property>
</configuration>
五 程序调试
在ambari-logserarch-portal组件部署的主机上的/etc/ambari-logsearch-portal/conf/logsearch-env.sh文件中会有相关的配置文件
#export LOGSEARCH_DEBUG=false
export LOGSEARCH_DEBUG=true export LOGSEARCH_DEBUG_PORT=
默认DEBUG模式是关闭的,打开后ambari-logserarch-portal就会监听5005端口了,然后你就可以用idea或者其他工具愉快的进行远程调试了。
六 相关问题
实际使用过程中发现,查询的时候会有正则匹配相关的问题,refer to AMBARI-23333
七 后记
由于Ambari Log Search是为大数据相关服务定制,大数据集群一般集群规模会比较大,组件也很多,对应的相关日志也很多,可能考虑到负载、健壮性等问题,官方目前也只是在小规模(例如在只有100多个节点的非生产环境的小集群上使用)的在使用。不过Ambari Log Search本身还是很有意义的,相信后面也会有不错的发展。
Ambari Log Search的更多相关文章
- Fluentd: Open Source Log Management
Fluentd: Open Source Log Management "Fluentd" is an open-source tool to collect events and ...
- 离线方式部署Ambari2.6.0.0
Hadoop生态圈-离线方式部署Ambari2.6.0.0 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我现在所在的公司用的是CDH管理Hadoop集群,前端时间去面试时发现很多 ...
- jquery 练习笔记
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 查看MS SQL SERVER 错误日志
查看目的: 错误日志的查看是确保过程已成功完成(例如,备份和恢复操作,批处理命令,或其他脚本和过程).这可以帮助检测任何当前或潜在的问题,包括自动恢复信息(尤其是如果SQL Server实例已停止并重 ...
- Js 对 浏览器 的 URL的操作
下面是一些实例: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://ww ...
- node.js下LDAP查询实践
目标: 从一个LDAP Server获取uid=kxh的用户数据 LDAP地址为:ldap://10.233.21.116:389 在工程根目录中,先npm一个LDAP的访问库ldpajs npm i ...
- jquery.ui.widget详解
案例详解 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <titl ...
- JqueryUI学习笔记-自动完成autocomplete
<!DOCTYPE html><html><head><meta charset="UTF-8"><title>Inse ...
- Backbone笔记(续)
Backbone Bockbone 总览 Backbone 与 MVC 模式:解决某一类问题的通用方案 - 套路 MVC:一种架构模式,解耦代码,分离关注点 M(Model) - 数据模型 V(Vie ...
随机推荐
- 多线程编程学习笔记——异步调用WCF服务
接上文 多线程编程学习笔记——使用异步IO 接上文 多线程编程学习笔记——编写一个异步的HTTP服务器和客户端 接上文 多线程编程学习笔记——异步操作数据库 本示例描述了如何创建一个WCF服务,并宿主 ...
- java 8 Lambda表达式(翻译自Stackoverflow)
(原文链接)Lambda只能作用于一个只有一个抽象方法的函数式接口(Function Interface),不过函数式接口可以有任意数量default或static修饰的方法(因此,它们有时也被当做单 ...
- 利用ffmpeg将H264流 解码为RGB
利用H264解码分为几个步骤: 注意一点在添加头文件的时候要添加extern "C",不然会出现错误 [cpp] view plaincopy extern "C&quo ...
- Procedure execution failed 2013 - Lost connection to MySQL server during query
1 错误描述 Procedure execution failed 2013 - Lost connection to MySQL server during query 2 错误原因 由错误描述可知 ...
- 中断处理程序不能使用printf的本质
vxworks 中断处理程序之所以不用printf,本质在于printf是将信息输出到标准输出设备(STDOUT)中, 整个标准输出设备是一个全局变量,由于有semTake操作,那么就会发生阻塞,vx ...
- Java中的switch语句后面的控制表达式的数据类型
Java中的switch语句后面的控制表达式的数据类型 1.byte 2.char 3.short 4.int 5.枚举类型 6.Java 7允许java.lang.String类型
- HTML5之Canvas画圆形
HTML5之Canvas画圆形 1.设计源码 <!DOCTYPE html> <head> <meta charset="utf-8" /> & ...
- 你需要了解的高可用方案之使用keepalived搭建双机热备一览
在之前一篇使用nginx搭建高可用的解决方案的时候,很多同学会问,如果nginx挂掉怎么办,比如下面这张图: 你可以清楚的看到,如果192.168.2.100这台机器挂掉了,那么整个集群就下线了,这个 ...
- yyb要填的各种总结的坑
已经写好啦的 莫比乌斯反演 杜教筛 动态点分治 斜率优化 Splay 莫队 凸包 旋转卡壳 Manacher算法 Trie树 AC自动机 高斯消元 KMP算法 SA后缀数组 SAM后缀自动机 回文树 ...
- Luogu P3412 仓鼠找$sugar$ $II$
Luogu P3412 仓鼠找\(sugar\) \(II\) 题目大意: 给定一棵\(n\)个点的树, 仓鼠每次移动都会等概率选择一个与当前点相邻的点,并移动到此点. 现在随机生成一个起点.一个终点 ...