Scrapy爬虫框架第五讲(linux环境)【download middleware用法】
DOWNLOAD MIDDLEWRE用法详解
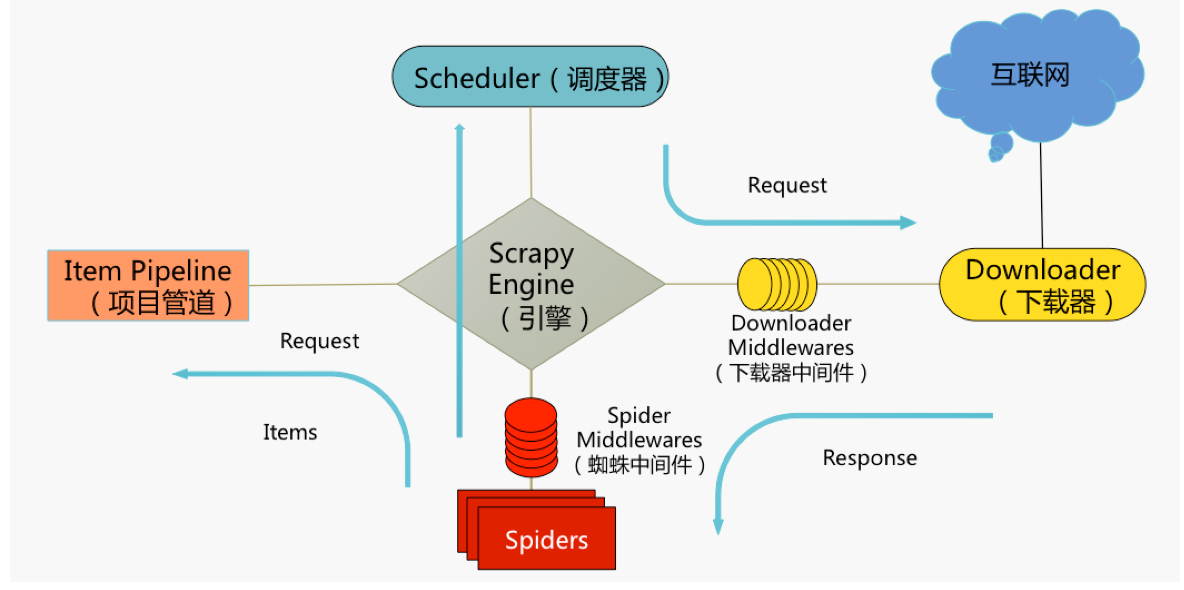
通过上面的Scrapy工作架构我们对其功能进行下总结:
(1)、在Scheduler调度出队列时的Request送给downloader下载前对其进行修改
(2)、在下载生成后的Response发送给Spider并在Spider对其解析之前对其修改
【这里我们将scheduler spiders downloader middlewares downloader看作四个小伙伴做游戏进一步进行理解 】
(1)scheduler对spider说:请把request给我,spiders收到信息后,就说这是我的request,拿去吧
(2)scheduler收到request后要去找名叫downloader的小伙伴才能去服务器上下载数据,
(3)这时,名叫downloader middlewares的小伙伴跳出来说,得怎么没我什么事了,于是它站在了scheduler和downloader中间,愤恨地说出了自己的价值(我可以对scheduler你的request进行如增加http header信息,增加proxy信息,重定向,失败重试等操作!)
Scrapy框架提供了多种内置的downloader middleware(摘自http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/downloader-middleware.html#topics-downloader-middleware-ref,小伙伴们了解即可)
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware':100,【该中间件过滤所有robots.txt eclusion standard中禁止的request。】
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware':200,【该中间件完成某些使用 Basic access authentication (或者叫HTTP认证)的spider生成的请求的认证过程。】
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware':300,【该中间件设置 DOWNLOAD_TIMEOUT 指定的request下载超时时间.】
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware':400,【该中间件设置 DEFAULT_REQUEST_HEADERS 指定的默认request header】
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':500,【用于覆盖spider的默认user agent的中间件,要使得spider能覆盖默认的user agent,其 user_agent 属性必须被设置。】
'scrapy.downloadermiddlewares.retry.RetryMiddleware':600,【该中间件将重试可能由于临时的问题,例如连接超时或者HTTP 500错误导致失败的页面。】
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware':650,【该中间件根据meta-refresh html标签处理request重定向。】
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware':700,【该中间件提供了对压缩(gzip, deflate)数据的支持】
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware':750,【该中间件根据response的状态处理重定向的request。】
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware':800,【该中间件使得爬取需要cookie(例如使用session)的网站成为了可能。 其追踪了web server发送的cookie,并在之后的request中发送回去, 就如浏览器所做的那样】
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':850,【该中间件提供了对request设置HTTP代理的支持。您可以通过在 Request 对象中设置 proxy 元数据来开启代理。】
这里给小伙伴们普及一个概念:我们发现在每个内置中间件后面都跟了数字:这些数字是什么意思呢?
答:我们以食堂吃饭为例,就以我们学校二食堂,你去打饭正值中午11.50,这时你会发现人多到你想骂娘,所有你需要排队等候,我们以此类比,你打的饭菜就相当于request请求,当你需要将request请求送给download组件(你成功打到饭菜)前你需要排队,在这数字越小说明你在队伍中的位置越靠前,即你的优先级越高,而数字越大的人排的越靠后就可能吃不到饭了,小伙伴们明白了没?
Scrapy框架不仅定义了自己的中间件,我们还可以根据需要进行自我定义:
class scrapy.downloadermiddlewares.DownloaderMiddleware
这里我们定义自己的downloader middleware ,而每个类都定义了一个或多个方法,我们介绍以下三个核心的方法:
(1)、process_request(request,spider) 【参数一:request (Request 对象) –即待处理的request对象 /参数二:spider (Spider 对象) – 该request对应的spider】
方法分析:
该方法在request被引擎调度给downloader之前被调用
该方法有4种返回结果:我们依次来分析:
(1)、返回None:
此时scrapy会继续处理该Request,即不同的Downloader middleware 按优先级的顺序修改该Request,并送给Downloader执行
(2)、返回Response:
此时scrapy不会再执行其他的process_request和process_exception方法,并调用Downloader middleware的每个process_response方法,将Request送给spider组件
(3)、返回Request对象
此时scrapy会返回process_request方法并重新执行(即重试),直到新的Request被执行,才返回Response
(4)、返回IgnoreRequest异常
此时会依次执行Downloader middleware的process_exception方法,如果process_exception方法无法解决,那么就会回调Request的errback方法,如果还无法解决,那么该异常就会被忽略
下面我们来打个比方帮助小伙伴们理解下上面四种放回情况:
我们以去食堂吃饭为例:(1)、就是你拿着饭卡成功打到了饭菜(2)、你拿着饭卡去打饭,食堂阿姨给了你一袋子东西(但遗憾的是这不是饭菜,即你打了假饭菜(3)、你拿着饭卡去打饭,食堂阿姨说你可能拿了假饭卡,重新去排队打饭吧(4)、你拿着饭卡去打饭,食堂阿姨直接把你忽略了
小伙伴们明白了吗?如果有问题,不要着急,我们接着往下看:
该方法使用实例分析:
下面小伙伴们让我们使用process_request方法实现代理的设置(下面实验是基于win10 pycharm中运行的 )
首先:启动终端新建项目:scrapy startproject httpbintest
cd httpbinbest ----scrapy genspider httpbin httpbin.org
接着:利用pycharm启动项目
改写httpbin.py

利用alt+f12启动pycharm的terminal:执行命令:scrapy crawl httpbin
得到如下输出:(这里我只贴出了部分)

这里我们可以看到成功爬取啦,小伙伴们我们注意到origin字段(这就是你本机电脑的ip,你可以把它复制进百度,一查,定位看看,这里我的是镇江联通)
下面我们要实现更换该ip来实现对网站的爬取(即伪装自我)
打开:middleware.py并修改
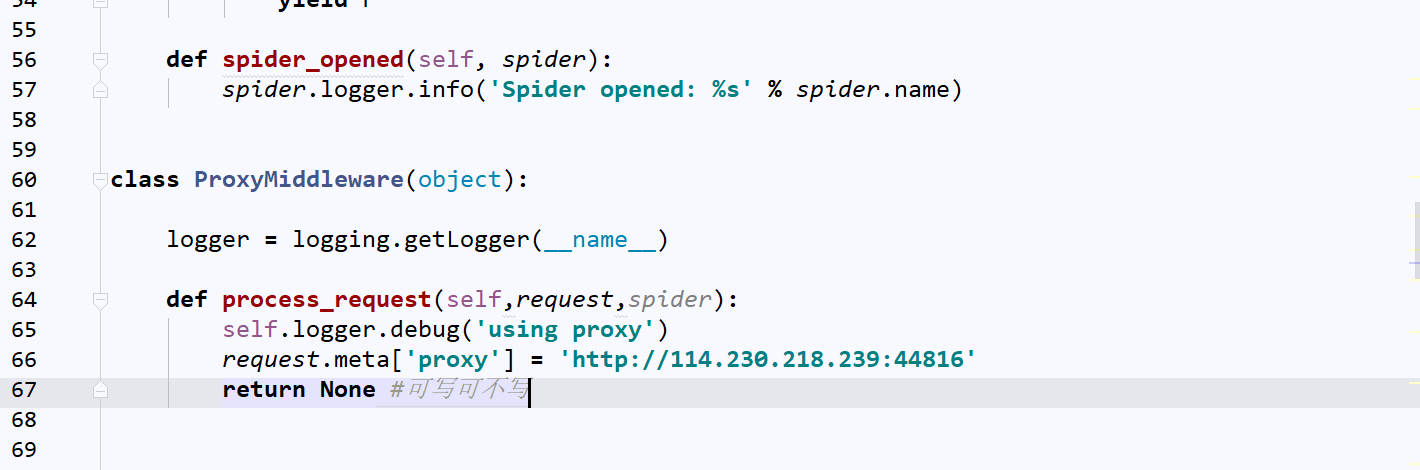
这里小伙伴们可以上讯代理购买几个i(本人发现系统代理需要输密码,所以出了9块大洋买了几个代理ip)【注释:小伙伴们别忘了导入logging模块】
这里我们返回值为None,具体什么意思参见上文
最后打开:settings.py(项目配置文件)启动中间件

得到如下输出:(这里我也只贴了部分)
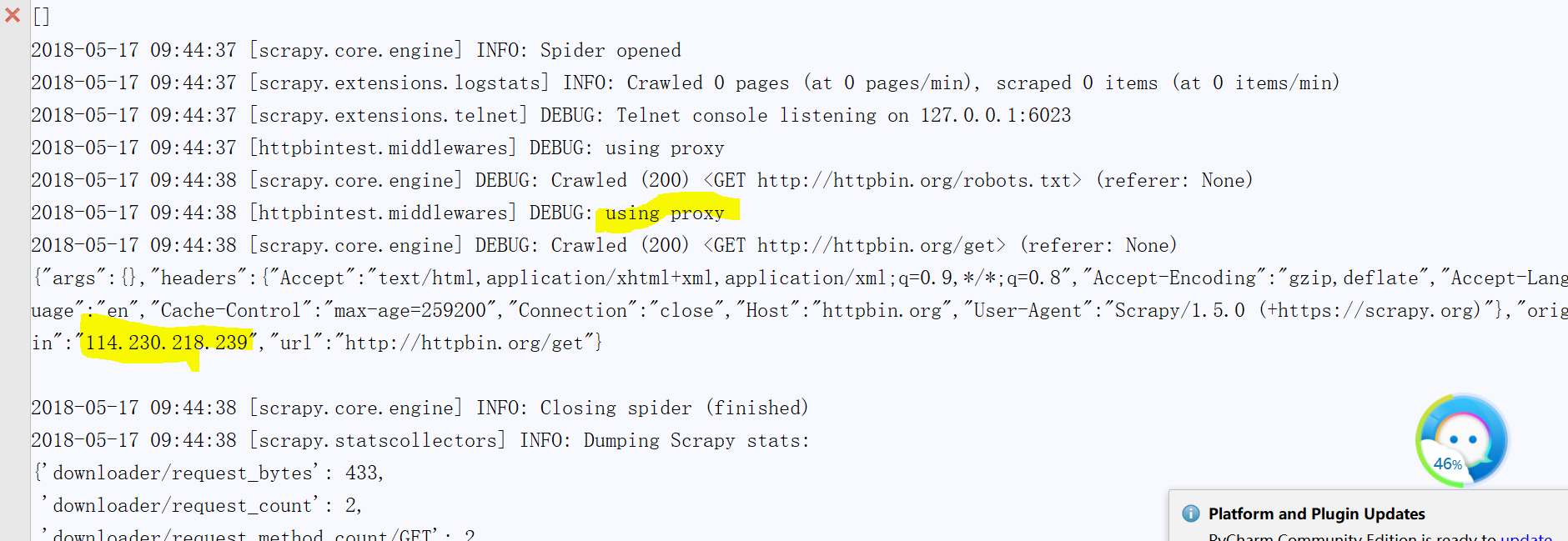
小伙伴们我们可以将成功运行的ip百度一下,你会发现地址已换,我们成功实现了伪装我们的ip进行爬取,是不是很有意思!
(2)、process_response(request,response,spider) 【参数一:Request对象 参数二:Response对象,即被处理的Response 参数三:Spider对象,即Response对应的Spider】
该方法返回四种结果,我们依次来分析:
(1)、返回Request对象
此时,优先级更低的Downloader Middleware 的process_response方法将不会被调用,该Request会重回队列被process_request处理,即返回了上一个Request的(1)
(2)、返回Response对象
此时,将会执行更低优先级的process_response方法,继续处理Response
(3)、返回IgnoreRequest异常
此时同Request的(4)
该方法使用实例分析
改写middleware.py(这里我只贴出了部分)

改下httpbin.py
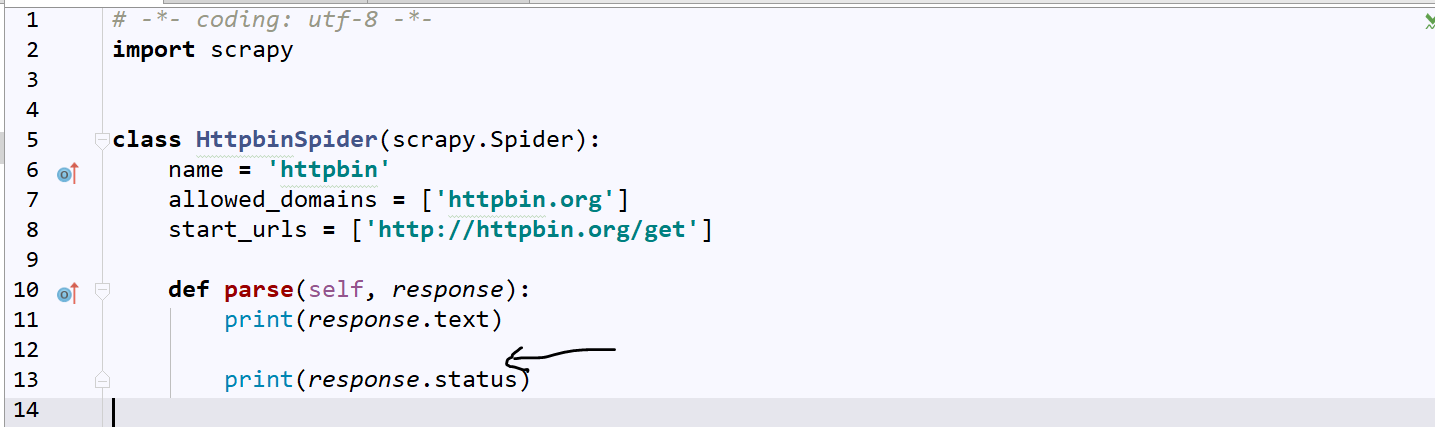
得到的输出结果如下: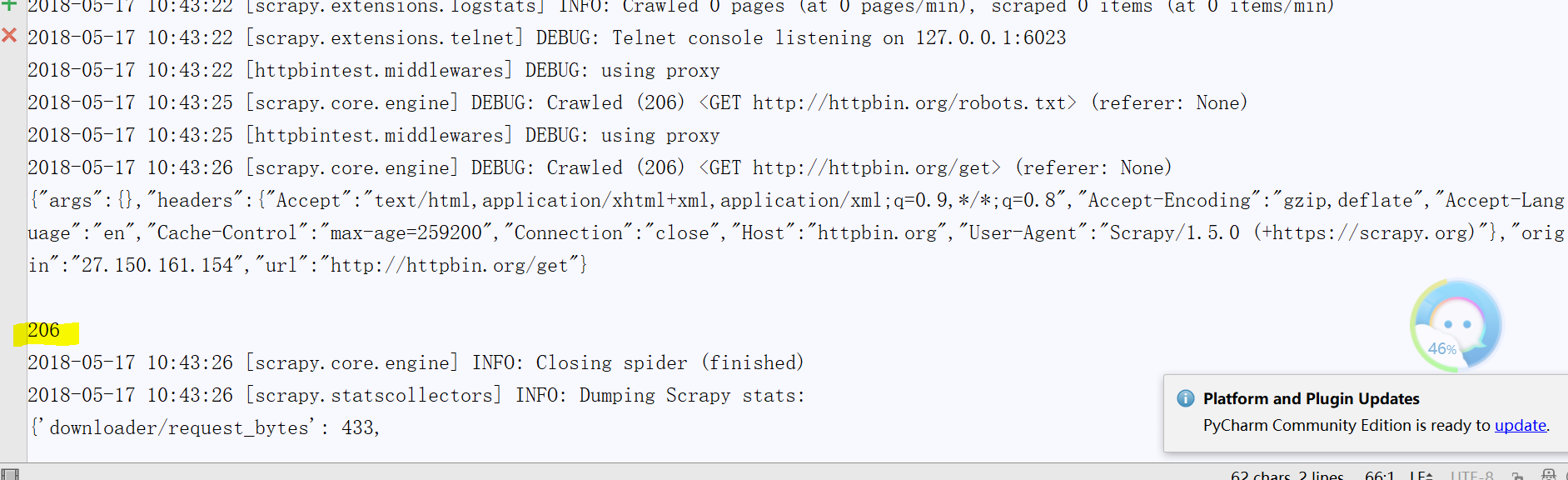
我们来分析下过程:downloader获取Response之后经过middleware改写,将原本的状态吗变成了206再传给Response,所以我们得到的Response的状态吗成立206了
总结:process_response主要用来改写你downloader返回的Response
(3)、process_exception(request,exception,spider)【参数一:产生异常的Request对象 参数二:即抛出的异常exception对象 参数三:Request对应的spider】----主要用来处理由process_request产生的异常
该方法返回三种结果,我们依次来分析下:
(1)、返回None
此时,更低优先级的Downloader Middleware的process_exception方法将会被调用,直到所有的方法都被调度完毕【错误没有被纠正】
(2)、返回Response
此时,更低优先级的Downloader Middleware的process_exception方法将不会被调用,而依次去执行所有中间件的process_response方法【错误被纠正了】
(3)、返回Request
此时,更低优先级的Downloader Middleware的process_exception方法将不会被调用,而依次去执行process_request方法【回炉重造了】
总结:
(1)Downloader Middlewares 由scrapy内置的middleware和你自己定义的middlewares组成
(2)如小伙伴不想使用scrapy内置的middlewares可以'scrapy.downloadermiddlewares.retry.RetryMiddleware':None,这样就不启用了
(3)各个middlewares后面的数字表示优先级,数字越小表明你的优先级越高(越远离downloader即先进去后出来),数字越大表明优先级越低(越靠近downloader即后进去先出来)
(4)我们主要使用downloader middlewares 来改变User-Agent、设置代理、cookies等反反爬虫机制(具体后面我们以实例详谈)
小伙伴们理解了吗?
Scrapy爬虫框架第五讲(linux环境)【download middleware用法】的更多相关文章
- Scrapy爬虫框架第一讲(Linux环境)
1.What is Scrapy? 答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰.模块之间的耦合程度低,具有较强的扩张性,能满足各种需求.(前 ...
- Scrapy爬虫框架第七讲【ITEM PIPELINE用法】
ITEM PIPELINE用法详解: ITEM PIPELINE作用: 清理HTML数据 验证爬取的数据(检查item包含某些字段) 去重(并丢弃)[预防数据去重,真正去重是在url,即请求阶段做] ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- python3.7.1安装Scrapy爬虫框架
python3.7.1安装Scrapy爬虫框架 环境:win7(64位), Python3.7.1(64位) 一.安装pyhthon 详见Python环境搭建:http://www.runoob.co ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
随机推荐
- Make3D Convert your image into 3d model
Compiling and Running Make3D on your own computer source: http://make3d.cs.cornell.edu/code_linux.ht ...
- C++ 传参时传内置类型时用传值(pass by value)方式效率较高
来源:唐磊的个人博客<C++ 传参时传内置类型时用传值(pass by value)方式效率较高> 在<Effective C++>里提到对内置(C-like)类型在函数传参时 ...
- Gradle 1.12用户指南翻译——第三十五章. Sonar 插件
本文由CSDN博客万一博主翻译,其他章节的翻译请参见: http://blog.csdn.net/column/details/gradle-translation.html 翻译项目请关注Githu ...
- bash下如何使用bind[En]
You can determine the character sequence emitted by a key by pressing Ctrl-v at the command line, th ...
- uc伯克利人工分割图像.seg文件解析
之前看到 http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/segbench/ 提供的人工图像分割的.seg格式 ...
- vs2010 matlab混合编程调用matlab引擎
// matlab_engine.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include "engine.h" ...
- 面试之路(10)-BAT面试之java实现单链表的插入和删除
链表的结构: 链表在空间是不连续的,包括: 数据域(用于存储数据) 指针域(用于存储下一个node的指针) 单项链表的代码实现: 节点类 构造函数 数据域的get,set方法 指针域的get,set方 ...
- Spring 学习笔记 ----依赖注入
依赖注入 有三种方式,本文只学习下属性注入. 属性注入 属性注入即通过 setXxx方法()注入Bean的属性值或依赖对象,由于属性注入方式具有可选择性和灵活性高的优点,因此属性注入方式是 ...
- 和菜鸟一起学linux之linux性能分析工具oprofile移植
一.内核编译选项 make menuconfig General setup---> [*] Profiling support <*> OProfile system profil ...
- rails4 中使用分页的方法
以前老版本的rails中默认自带分页方法,不过从rails2.0开始就将内置的分页pagination对象移除了,改以第三方gem提供支持.要在新的rails里使用分页也是非常简单啦,首先安装will ...