Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细
Python爬虫教程-31-创建 Scrapy 爬虫框架项目
- 首先说一下,本篇是在 Anaconda 环境下,所以如果没有安装 Anaconda 请先到官网下载安装
- Anaconda 下载地址:https://www.anaconda.com/download/
Scrapy 爬虫框架项目的创建
- 0.打开【cmd】
- 1.进入你要使用的 Anaconda 环境
- 1.环境名可以在【Pycharm】的【Settings】下【Project:】下找到
2.使用命令:activate 环境名,例如:
activate learn
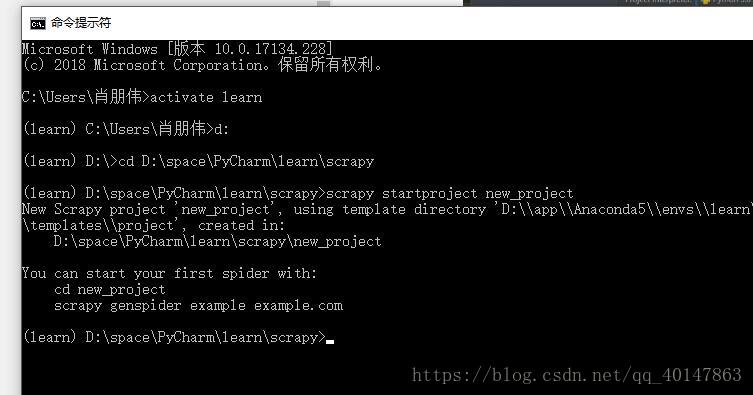
- 3.进入想要存放 scrapy 项目的目录下 【注意】
4.新建项目:scrapy startproject xxx项目名,例如:
scrapy startproject new_project
- 1.环境名可以在【Pycharm】的【Settings】下【Project:】下找到
- 5.操作截图:
- 6.在文件资源管理器打开该目录,就会发现生成了好几个文件
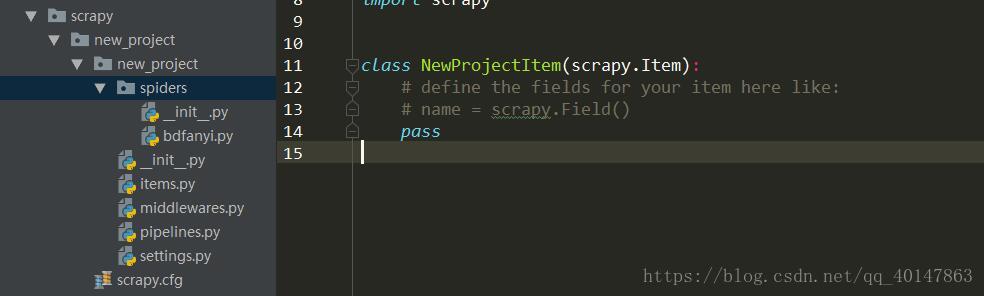
- 7.使用 Pycharm 打开项目所在目录就可以了
这里我们就把项目创建好了,分析一下自动生成的文件的作用
Scrapy 爬虫框架项目的开发
- 0.使用 Pycharm 打开项目,截图:
- 项目的开发的大致流程:
- 1.明确需要爬取的目标/产品:编写 item.py
- 2.在 spider 目录下载创建 python 文件制作爬虫:
- 地址 spider/xxspider.py 负责分解,提取下载的数据
- 3.存储内容:pipelines.py
- Pipeline.py 文件
- 对应 pipelines 文件
- 爬虫提取出数据存入 item 后,item 中保存的数据需要进一步处理,比如清洗,去虫,存储等
- Pipeline 需要处理 process_item 函数
- process_item
- spider 提取出来的 item 作为参数传入,同时传入的还有 spider
- 此方法必须实现
- 必须返回一个 Item 对象,被丢弃的 item 不会被之后的 pipeline
- _ init _:构造函数
- 进行一些必要的参数初始化
- open_spider(spider):
- spider 对象对开启的时候调用
- close_spider(spider):
- 当 spider 对象被关闭的时候调用
- Spider 目录
- 对应的是文件夹 spider 下的文件
- _ init _:初始化爬虫名称,start _urls 列表
- start_requests:生成 Requests 对象交给 Scrapy 下载并返回 response
- parse:根据返回的 response 解析出相应的 item,item 自动进入 pipeline:如果需要,解析 url,url自动交给 requests 模块,一直循环下去
- start_requests:此方法尽能被调用一次,读取 start _urls 内容并启动循环过程
- name:设置爬虫名称
- start_urls:设置开始第一批爬取的 url
- allow_domains:spider 允许去爬的域名列表
- start_request(self):只被调用一次
- parse:检测编码
- log:日志记录
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-31-创建 Scrapy 爬虫框架项目的更多相关文章
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- 学好Python不加班系列之SCRAPY爬虫框架的使用
scrapy是一个爬虫中封装好的一个明星框架.具有高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式. 对于初学者来说还是需要有一定的基础作为铺垫的学习.我将从下方的思维导图中进行逐步的解析 ...
- Python 爬虫-股票数据的Scrapy爬虫
2017-08-06 19:52:21 目标:获取上交所和深交所所有股票的名称和交易信息输出:保存到文件中 技术路线:scrapy 获取股票列表:东方财富网:http://quote.eastmone ...
- 分布式爬虫搭建系列 之四---scrapy分布式框架
带录入SAFCDS
- 大爽Python入门教程 3-1 布尔值: True, False
大爽Python入门公开课教案 点击查看教程总目录 1 布尔值介绍 从判断说起 回顾第一章介绍的简单的判断 >>> x = 10 >>> if x > 5: ...
- python学习教程(九)sqlalchemy框架的modern映射
首先写一个modern.py文件, from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Col ...
- Java开发工具IntelliJ IDEA使用教程:创建新的Andriod项目
IntelliJ IDEA社区版作为一个轻量级的Java开发IDE,本身是一个开箱即用的Android开发工具. 注意:在本次的教程中我们将以Android平台2.2为例进行IntelliJ IDEA ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
随机推荐
- django Form数据读取问题
1.在我学习django的过程中,我学习到了一个关于表单验证的问题 2.我们从前端post一个表单,通过urls配置,传给对应的view方法 3.然后再传给Form验证 4.一开始我是很好奇,在vie ...
- 《The One 团队》第二次作业:团队项目选题
项目 内容 作业所属课程 http://www.cnblogs.com/nwnu-daizh/ 作业要求 https://www.cnblogs.com/nwnu-daizh/p/10726884.h ...
- win 10安装应用程序提示Error 1317的解决方法
打开windows防火墙 关闭文件夹权限访问保护
- mysql 02
CREATE TABLE emp(eid INT,ename VARCHAR(20),egender CHAR(2),ebirthday DATE,eemail CHAR(10),eramark VA ...
- SQL数据库正在恢复 查看进度
在使用SQL的过程中.. 开启一个事务..进行大计算量..在中间出错或者强制杀死SQL服务进程..总之事务没有提交.. 再次开启时sql会进入自动检查的过程.. 数据库小的话问题不大..会比较快.. ...
- How do I use screen on the Linux systems?
Scope The screen utility provides a way to run a command on a Linux system, detach from it, and then ...
- AngularJs学习笔记--Creating Services
原版地址:http://docs.angularjs.org/guide/dev_guide.services.creating_services 虽然angular提供许多有用的service,在一 ...
- 【CSS】 布局之多列等高
这两天看了不少文章,对于css布局多了一些理解,现在来总结下. 我们来写一个最普遍的Top.Left.Content.Right.Foot布局. 第一步:自然是写一个坯子 <!DOCTYPE H ...
- orcale 之数据操作
SQL 语句的数据操作功能是通过数据操作语言实现的,用于改变数据库中的数据.数据更新包括插入.删除和修改三种操作,与之对应的就是 INSERT. UPDATE 和 DELETE. 数据准备 创建两张表 ...
- 1.5 js基础
1.变量.参数.return可以装任何东西. 2.什么时候使用window.onload? 当操作元素时 3.日期对象:在创建日期对象的时候它的日期是不会改变的. ...