spark2.4 分布式安装
一.Spark2.0的新特性
Spark让我们引以为豪的一点就是所创建的API简单、直观、便于使用,Spark 2.0延续了这一传统,并在两个方面凸显了优势:
1、标准的SQL支持;
2、数据框(DataFrame)/Dataset (数据集)API的统一。
在SQL方面,我们已经对Spark的SQL功能做了重大拓展,引入了新的ANSI SQL解析器,并支持子查询功能。Spark 2.0可以运行所有99个TPC-DS查询(需求SQL:2003中的很多功能支持)。由于SQL是Spark应用所使用的主要接口之一,对SQL功能的拓展大幅削减了将遗留应用移植到Spark时所需的工作。
在编程API方面,我们合理化了API:
1、在Scala/Java中统一了DataFrames与Dataset:从Spark 2.0开始,DataFrames只是行(row)数据集的typealias了。无论是映射、筛选、groupByKey之类的类型方法,还是select、groupBy之类的无类型方法都可用于Dataset的类。此外,这个新加入的Dataset接口是用作Structured Streaming的抽象,由于Python和R语言中编译时类型安全(compile-time type-safety)不属于语言特性,数据集的概念无法应用于这些语言API中。而DataFrame仍是主要的编程抽象,在这些语言中类似于单节点DataFrames的概念,想要了解这些API的相关信息,请参见相关笔记和文章。
2、SparkSession:这是一个新入口,取代了原本的SQLContext与HiveContext。对于DataFrame API的用户来说,Spark常见的混乱源头来自于使用哪个“context”。现在你可以使用SparkSession了,它作为单个入口可以兼容两者,点击这里来查看演示。注意原本的SQLContext与HiveContext仍然保留,以支持向下兼容。
更简单、性能更佳的Accumulator API:我们设计了一个新的Accumulator API,不但在类型层次上更简洁,同时还专门支持基本类型。原本的Accumulator API已不再使用,但为了向下兼容仍然保留。
3、基于DataFrame的机器学习API将作为主ML API出现:在Spark 2.0中,spark.ml包及其“管道”API会作为机器学习的主要API出现,尽管原本的spark.mllib包仍然保留,但以后的开发重点会集中在基于DataFrame的API上。
4、机器学习管道持久化:现在用户可以保留与载入机器学习的管道与模型了,Spark对所有语言提供支持。查看这篇博文以了解更多细节,这篇笔记中也有相关样例。
R语言的分布式算法:增加对广义线性模型(GLM)、朴素贝叶斯算法(NB算法)、存活回归分析(Survival Regression)与聚类算法(K-Means)的支持。
二.Spark2.4 安装
环境要求jdk 1.8以上版本,scala-2.12以上
基于的Hadoop版本,我的现有hadoop为2.6
官网下载时注意:http://spark.apache.org/downloads.html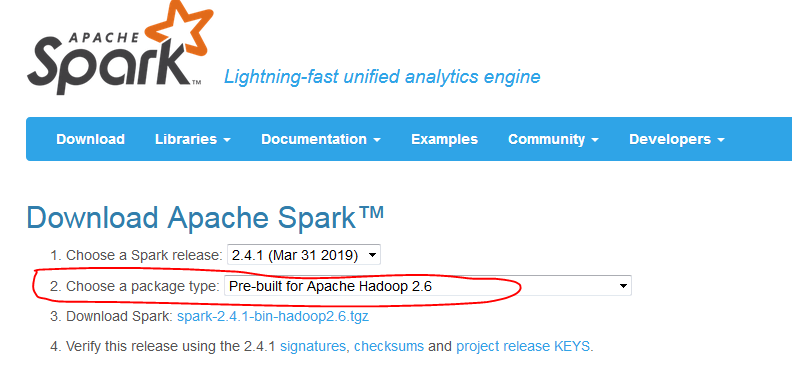
安装架构
h220 为主节点
H221,h222 为从节点
1.解压缩spark
[hadoop@h220 spark]$ cp spark-2.4.1-bin-hadoop2.6.tgz /home/hadoop/
[hadoop@h220 ~]$ tar -zxvf spark-2.4.1-bin-hadoop2.6.tgz
2.安装jdk,scala
[hadoop@h220 usr]$ tar -zxvf jdk-8u151-linux-x64.tar.gz
[hadoop@h220 ~]$ tar -zxvf scala-2.12.4.tgz
3.设置环境变量
[hadoop@h220 ~]$ vi .bash_profile
export JAVA_HOME=/usr/jdk1.8.0_151
export JAVA_BIN=/usr/jdk1.8.0_151/bin
export SCALA_HOME=/home/hadoop/scala-2.12.4
export SPARK_HOME=/home/hadoop/spark-2.4.1-bin-hadoop2.6
[hadoop@h220 ~]$ source .bash_profile
4.配置spark
[hadoop@h220 ~]$ cd spark-2.4.1-bin-hadoop2.6/conf/
[hadoop@h220 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@h220 conf]$ vi spark-env.sh
添加:
export JAVA_HOME=/usr/jdk1.8.0_151
export SCALA_HOME=/home/hadoop/scala-2.12.4
export SPARK_MASTER_IP=h220
export SPARK_WORDER_INSTANCES=1
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.5.2
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.6.0-cdh5.5.2/etc/hadoop
[hadoop@h220 conf]$ cp slaves.template slaves
[hadoop@h220 conf]$ vi slaves
删除localhost
添加:
h221
h222
5.copy到从节点
配置ssh证书
[hadoop@h220 ~]$ scp -r spark-2.4.1-bin-hadoop2.6 h221:/home/hadoop/
[hadoop@h220 ~]$ scp -r spark-2.4.1-bin-hadoop2.6 h222:/home/hadoop/
6.启动,验证
主节点:
[hadoop@h220 spark-2.4.1-bin-hadoop2.6]$ sbin/start-all.sh
[hadoop@h220 spark-2.4.1-bin-hadoop2.6]$ jps
6970 Master
从节点:
[hadoop@h221 spark-2.4.1-bin-hadoop2.6]$ jps
3626 Worker
主节点:
[hadoop@h220 spark-2.4.1-bin-hadoop2.6]$ bin/spark-shell
没有报错
spark2.4 分布式安装的更多相关文章
- HBase基础和伪分布式安装配置
一.HBase(NoSQL)的数据模型 1.1 表(table),是存储管理数据的. 1.2 行键(row key),类似于MySQL中的主键,行键是HBase表天然自带的,创建表时不需要指定 1.3 ...
- Zookeeper 初体验之——伪分布式安装(转)
原文地址: http://blog.csdn.net/salonzhou/article/details/47401069 简介 Apache Zookeeper 是由 Apache Hadoop 的 ...
- hadoop2.6完全分布式安装HBase1.1
本文出自:http://wuyudong.com/archives/119 对于全分布式的HBase安装,需要通过hbase-site.xml文档来配置本机的HBase特性,由于各个HBase之间通过 ...
- CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装
摘要 CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装 目录[-] 1.系统环境说明 2.安装前的准备工作 2.1 关闭防火墙 2.2 检查ssh安装情况,如果没有则安装ssh ...
- Hadoop2.6.0完全分布式安装
本文地址:http://www.cnblogs.com/myresearch/p/hadoop-full-distributed-operation.html,转载请注明源地址. 我这边是使用了两台主 ...
- hadoop2.2.0+hive-0.10.0完全分布式安装方法
hadoop+hive-0.10.0完全分布式安装方法 1.jdk版本:jdk-7u60-linux-x64.tar.gz http://www.oracle.com/technetwork/cn/j ...
- hadoop-2.6.0为分布式安装
hadoop-2.6.0为分布式安装 伪分布模式集群规划(单节点)------------------------------------------------------------------- ...
- 整体认识flume:Flume介绍、分布式安装、常见问题及解决方案
问题导读 1.什么是flume? 2.flume包含哪些组件? 3.Flume在读取utf-8格式的文件时会出现解析不了时间戳,该如何解决? Flume是一个分布式.可靠.和高可用的海量日志采集.聚合 ...
- Hadoop单机和伪分布式安装
本教程为单机版+伪分布式的Hadoop,安装过程写的有些简单,只作为笔记方便自己研究Hadoop用. 环境 操作系统 Centos 6.5_64bit 本机名称 hadoop001 本机IP ...
随机推荐
- Docker -v 对挂载的目录没有权限 Permission denied
1.问题 今天在使用docker挂载redis的时候老是报错 docker run -v /home/redis/redis.conf:/usr/local/etc/redis/redis.conf ...
- 对EF的封装
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.D ...
- 设计模式系列1:单例模式(Singleton Pattern)
定义 保证一个类仅有一个实例,并提供一个该实例的全局访问点. --<设计模式GoF> UML类图 使用场景 当类只能有一个实例并且用户可以从一个众所周知的访问点访问它时. 创建一个对象需 ...
- 【译】在C#中实现单例模式
目录 介绍 第一个版本 --不是线程安全的 第二个版本 -- 简单的线程安全 第三个版本 - 使用双重检查锁定尝试线程安全 第四个版本 - 不太懒,不使用锁且线程安全 第五版 - 完全懒惰的实例化 第 ...
- 设计模式之适配者模式——Java语言描述 | Amos H's blog
适配器模式是作为两个不兼容的接口之间的桥梁.这种类型的设计模糊属于结构性模式,它结合了两个独立接口的功能 概念阐述 使用适配器模式可以解决在软件系统中,将一些旧的类放入新环境中,但是新环境要求的接口旧 ...
- UiPath实践经验总结(二)
1. UI操作容易受到各种意外的干扰,因此应该缩短UI操作阶段的总体时间.而为了缩短UI操作阶段的总体时间,应该将UI操作尽量放在一起,将后台的各种操作尽量放在UI操作的前后.例如,现在有 ...
- Windows 下安装RabbitMQ服务器及基本配置
RabbitMQ是一个在AMQP协议标准基础上完整的,可复用的企业消息系统.它遵循Mozilla Public License开源协议,采用 Erlang 实现的工业级的消息队列(MQ)服务器,Rab ...
- 随笔:WPS居然!出了!Mac版!
震惊! WPS! 居然! 出了! Mac版! 刚刚,我打算改一个word文档,打开了我的WIN10虚拟机,然而由于这个win10是前两天重装的,上面并没有word和wps. 当我打开wps官网的时候, ...
- Cesium3DTileset示例
3D Tiles是Cesium中很核心的一部分,尤其是用来实现大范围的模型场景数据的加载应用. 三维倾斜模型.人工建模.BIM模型等等,都可以转换成3D Tiles,进而为我们所用. 从Cesium1 ...
- 容器化时代我们应当选择Kubernetes
前天发的文章<基于Kubernetes 构建.NET Core 的技术体系>,有同学问.NET Core上有Spring Cloud类似的平台吗? .NET Core出现这么久了,这个为云 ...