字符串匹配(一)----Rabin-Karp算法
题目:假如要判断字符串A"ABA"是不是字符串B"ABABABA"的子串。
解法一:暴力破解法, 直接枚举所有的长度为3的子串,然后依次与A比较,这样就能得出匹配的位置。 这样的时间复杂度是O(M*N),M为B的长度,N为A的长度。
解法二:Rabin-Karp算法
思想:假设待匹配字符串的长度为N,目标字符串的长度为M(M>N);首先计算待匹配字符串的hash值,计算目标字符串前N个字符的hash值;比较前面计算的两个hash值,比较次数M-N+1:若hash值不相等,则继续计算目标字符串的下一个长度为N的字符子串的hash值,若hash值相同,则需要使用比较字符是否相等再次判断是否为相同的子串(这里若hash值相同,则直接可以判断待匹配字符串是目标字符串的子串,之所以需要再次判断字符是否相等,是因为不同的字符计算出来的hash值有可能相等,称之为hash冲突或hash碰撞,不过这是极小的概率,可以忽略不计);
哈希函数定义如下:
其中Cm表示字符串中第m项所代表的特地数字,有很多种定义方法,我习惯于用java自带的char值,也就是ASCII码值。java中的char是16位的,用的Unicode编码,8位的ASCII码包含在Unicode中。b是哈希函数的基数,相当于把字符串看作是b进制数。h是防止哈希值溢出。
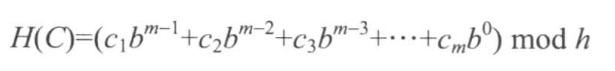
代码:
public class RabinKarp {
public static void main(String[] args) {
String s = "ABABABA";
String p = "ABA";
match(p, s);
}
/**
* @param p 模式
* @param s 源串
*/
static void match(String p,String s){
long hash_p = hash(p);//p的hash值
int p_len = p.length();
for (int i = 0; i+p_len<= s.length(); i++) {
long hash_i = hash(s.substring(i, i+p_len));// i 为起点,长度为p_len的子串的hash值
if (hash_p==hash_i) {
System.out.println("match:"+i);
}
}
}
final static long seed = 31; // 进制数
/**
* 不同的字符计算出来的hash值相同 称为hash冲突
* 使用100000个不同字符串产生的冲突数,大概在0~3波动,使用100百万不同的字符串,冲突数大概110+范围波动。
* @param str
* @return
*/
private static long hash(String str) {
long h = 0;
for (int i = 0; i !=str.length(); i++) {
// 这个计算方式就是 An²+Bn+c 的循环表达式,而这个计算方式就是二进制转十进制的计算方式
// 这里n=31,可以理解为转为31进制
h = seed * h + str.charAt(i);
}
return h%Long.MAX_VALUE; // 防止hash值过大
}
}
结果:
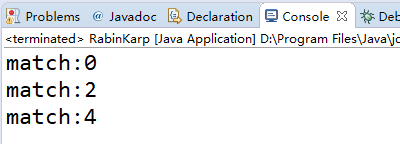
在这里计算一下时间复杂度,计算hash值的时间为O(N),目标字符串长度为M,所以时间复杂度为O(M*N)。好像和暴力破解差不多。下面会通过一种类似于预处理的方式来进行优化,叫做滚动哈希。就是提前计算好源串的hash值,构建成一个hash数组,再通过比较hash值,这样就成功匹配出来了。通过这种优化,时间复杂度下降到O(M+N),O(N)为计算待匹配的字符串计算hash值的时间,O(M)为计算hash数组的时间。
滚动哈希的技巧就是:如果已经算出从k到k+m的子串的哈希值H(S[k,k+1...k+m]),那么从k+1到k+m+1的子串的哈希值就可以基于前一个的哈希值计算得出。
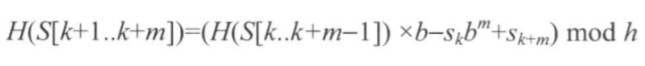
代码:
/**
* 滚动哈希法
* 对目标字符串按d进制求值,mod h 取余作为其hash
* 对源串,一次求出m个字符的hash,保存在数组中(滚动计算)
* 匹配时,只需对比目标串的hash值和预存的源串的hash值表
*/
public class RabinKarp_1 { public static void main(String[] args) {
String s = "ABABABA";
String p = "ABA";
match(p, s);
} static void match(String p,String s){
long hash_p = hash(p);//p的hash值
long[] hashOfS = hash(s, p.length());
for (int i = 0; i < hashOfS.length; i++) {
if (hashOfS[i] == hash_p) {
System.out.println("match:" + i);
}
}
} final static long seed = 31; /**
* 滚动哈希
* @param s 源串
* @param n 子串的长度
* @return
*/
private static long[] hash(String s, int n) {
long[] res = new long[s.length() - n + 1];
//前n个字符的hash
res[0] = hash(s.substring(0, n));
for (int i = n; i < s.length(); i++) {
char newChar = s.charAt(i); // 新增的字符
char oldchar = s.charAt(i - n); // 前n字符的第一字符
//前n个字符的hash*seed-前n字符的第一字符*seed的n次方
long v = (long) ((res[i - n] * seed + newChar - Math.pow(seed, n) * oldchar) % Long.MAX_VALUE);
res[i - n + 1] = v;
}
return res;
} static long hash(String str) {
long h = 0;
for (int i = 0; i != str.length(); ++i) {
h = seed * h + str.charAt(i);
}
return h % Long.MAX_VALUE;
}
}
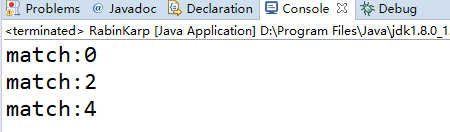
结果:
字符串匹配(一)----Rabin-Karp算法的更多相关文章
- 模式字符串匹配问题(KMP算法)
这两天又看了一遍<算法导论>上面的字符串匹配那一节,下面是实现的几个程序,可能有错误,仅供参考和交流. 关于详细的讲解,网上有很多,大多数算法及数据结构书中都应该有涉及,由于时间限制,在这 ...
- [小专题]另一种字符串匹配的思路——Shift-And算法
吐槽:前两天打组队赛遇到一个字符串的题考了这个(见:http://acm.hdu.edu.cn/showproblem.php?pid=5972 ) 当时写了个KMP瞎搞然后TLE了(害),赛后去查了 ...
- 字符串匹配的Boyer-Moore(BM)算法
各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法. Boyer-Moore算法不仅效率高,而且构思巧妙,容易理解.1977年,德克萨斯大学的Robe ...
- 神奇的字符串匹配:扩展KMP算法
引言 一个算是冷门的算法(在竞赛上),不过其算法思想值得深究. 前置知识 kmp的算法思想,具体可以参考 → Click here trie树(字典树). 正文 问题定义:给定两个字符串 S 和 T( ...
- 字符串匹配--Karp-Rabin算法
主要特征 1.使用hash函数 2.预处理阶段时间复杂度O(m),常量空间 3.查找阶段时间复杂度O(mn) 4.期望运行时间:O(n+m) 本文地址:http://www.cnblogs.com/a ...
- 字符串匹配&Rabin-Karp算法讲解
问题描述: Rabin-Karp的预处理时间是O(m),匹配时间O( ( n - m + 1 ) m )既然与朴素算法的匹配时间一样,而且还多了一些预处理时间,那为什么我们还要学习这个算法呢?虽然Ra ...
- 算法——字符串匹配Rabin-Karp算法
前言 Rabin-Karp字符串匹配算法和前面介绍的<朴素字符串匹配算法>类似,也是相应每一个字符进行比較.不同的是Rabin-Karp採用了把字符进行预处理,也就是对每一个字符进行相应进 ...
- 字符串匹配的KMP算法
~~~摘录 来源:阮一峰~~~ 字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串”BBC ABCDAB ABCDABCDABDE”,我想知道,里面是否包含另一个字符串”ABCDABD”? 许 ...
- sdut 2125串结构练习--字符串匹配【两种KMP算法】
串结构练习——字符串匹配 Time Limit: 1000ms Memory limit: 65536K 有疑问?点这里^_^ 题目链接:http://acm.sdut.edu.cn/sduto ...
- 字符串匹配的KMP算法详解及C#实现
字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD" ...
随机推荐
- SignalR在Asp.NetCore中的使用
SignalR简介 ASP.NET SignalR是为ASP.NET 开发人员提供的一个库,旨在为你的Web应用迅速简便的添加实时通信功能.这个Web通信功能是指:客户端可以实时从服务端代码拉取数据, ...
- 七 Git版本控制
把环境准备 主机名 node1 ip地址10.0.0.11 node2 10.0.0.12 node3 ...
- C# 高级编程05----常用修饰符
常用修饰符: 1.访问可见性修饰符 修饰符 应用于 说明 public 类型或成员 任何代码都可访问 protected 类型或内嵌类型的成员 只有子类能访问 internal 类型或成员 只能在包含 ...
- VMware虚拟机安装WIN7
VMware在IT工作人员的学习之中,使用的较多,故聊一聊VMware中WIN7的安装: 第一步:安装VMware,这个软件百度就可以下载,但是是收费软件,注册码可以百度到. 第二步:VMware安装 ...
- 《ServerSuperIO Designer IDE使用教程》-4.增加台达PLC驱动及使用教程,从0到1的改变。发布:v4.2.3版本
v4.2.3 更新内容:1.优化数据存储部分,提高效率.2.修复数据库服务停止造成程序异常退出的现象.3.修复本机没有串口造成无法增加设备驱动的情况.4.增加编辑设备和监测点配置信息功能.5.增加台达 ...
- web页面和小程序页面实现瀑布流效果
小程序实现瀑布流效果,和web页面差不多,都要经过以下步骤: 1).加载图片,获取图片的宽高度: 2).根据页面需要显示几列计算每列的宽度: 3).根据图片真实宽度和每列的宽度比,计算出图片需要显示的 ...
- Centos7安装jdk-12的详细过程
Centos7安装jdk-12的详细过程 2019-04-12 21:23:24 一.下载JDK-12版本 链接地址:官方地址 下载:jdk-12_liunx-x64_bin.tar.gz 二.检 ...
- Codeforces 1144F Graph Without Long Directed Paths (DFS染色+构造)
<题目链接> 题目大意:给定一个无向图,该无向图不含自环,且无重边.现在要你将这个无向图定向,使得不存在任何一条路径长度大于等于2.然后根输入边的顺序,输出构造的有向图.如果构造的边与输入 ...
- TortoiseSVN--clearup清理失败解决办法
工作中经常遇到update.commit 失败导致冲突问题,需要用clear up来清除问题,个别异常情况导致clear up失败,进入死循环!可以使用sqlite3.exe清理一下wc.db文件的队 ...
- C#中委托和事件的区别
大致来说,委托是一个类,该类内部维护着一个字段,指向一个方法.事件可以被看作一个委托类型的变量,通过事件注册.取消多个委托或方法.本篇分别通过委托和事件执行多个方法,从中体会两者的区别. □ 通过委托 ...