Ignite(二): 架构及工具
1、集群和部署

Ignite集群基于无共享架构,所有的集群节点都是平等的,独立的,整个集群不存在单点故障。
通过灵活的Discovery SPI组件,Ignite节点可以自动地发现对方,因此只要需要,可以轻易地对集群进行缩放。(与哪套集群类似呢? ES)
Ignite可以独立运行,可以组成集群,可以运行于Kubernetes和Docker容器中,也可以运行在Apache Mesos以及Hadoop Yarn上,可以运行于虚拟机和云环境,也可以运行于物理机,从技术上来说,集群部署在哪里,是没有限制的。
- Apache Ignite具有一个可选的服务概念,并提供了两种类型的节点:客户端和服务器节点:
- Server 包含数据、缓存、计算和流,并且可以是内存中的Map-Reduce任务的一部分。
- Client 提供远程连接服务器以将元素放入/获取到缓存的能力。它还可以存储部分数据(近缓存),这是一个较小的本地缓存,存储最近和最频繁访问的数据。
- 除了客户端节点,还可以通过Ignite的二进制客户端协议、JDBC/ODBC驱动、REST API接入集群。
容器:
Ignite完全支持容器环境,Ignite与Docker的集成可以在服务启动之前,自动地将业务代码构建并且部署进Ignite。
Ignite也可以部署在Kubernetes中,可以自动地部署和管理容器化的应用。
资源管理器:
- Ignite提供了对Hadoop Yarn,Kubernetes和Apache Mesos的原生支持,可以很容易地部署到这些环境。
2、基于内存的存储
Ignite基于分布式的内存架构,它将内存计算的性能和扩展性,与磁盘持久化和强一致性整合到一个系统中。
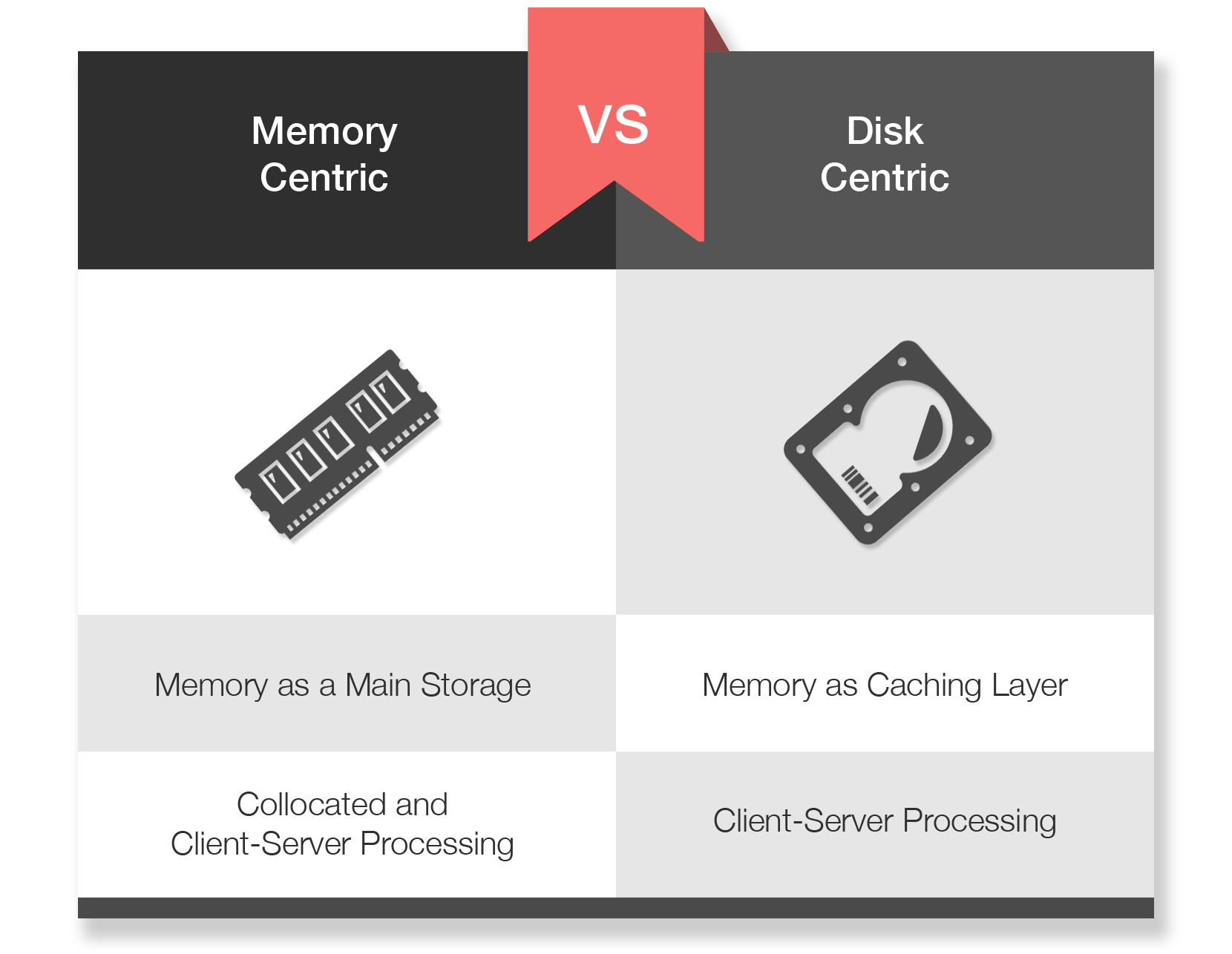
- 基于内存的方式和传统的基于磁盘的方式的主要不同是,Ignite将内存视为全功能的存储,而不是像传统大多数数据库那样仅仅是一个缓存层。比如,Ignite可以运行于纯内存模式,这时它就是一个内存数据库(IMDB)和内存数据网格(IMDG)。
- 另一方面,如果打开了持久化,Ignite就变成了一个处理是在内存中进行的基于内存的系统,但是数据和索引又持久化到磁盘上。这里与传统的基于磁盘的RDBMS或NoSQL系统的主要区别是,Ignite支持强一致、水平扩展、并且同时支持SQL和键-值处理API。
并置和C/S处理
- 基于磁盘的系统,比如RDBMS或者NoSQL,通常采用传统的C/S模式,数据需要从服务端传输到要处理的客户端,通常最终又被废弃,这种方法不可扩展,因为在分布式系统中,通过网络移动大量数据是非常昂贵的开销。
- 一个更有扩展性的方式是,通过将计算放在数据实际存储的服务端上,反过来实现并置处理,这个方法可以直接在数据实际存放的地方直接执行业务逻辑或者分布式SQL关联,避免了昂贵的序列化和网络开销。
分区和复制
- 根据配置,Ignite在内存存储中,可以是分区模式,也可以是复制模式,
- 复制模式中,数据在集群中的每个节点都有一份副本,
- 而分区模式,Ignite会在多个集群节点上对数据进行平均拆分,因此可以在内存及磁盘上存储TB级的数据。
冗余
- Ignite可以配置多个副本,来保证故障时的数据弹性。
一致性
- 不管使用哪种复制方案,Ignite都会保证整个集群的数据一致性。
Ignite作为内存存储
- 持久化对Ignite来说是可选的,这时整个集群就会工作于纯内存模式,所有的数据和索引都会只存储于内存中,这样会得到最高的性能,因为数据不需要写入磁盘。为了避免可能的节点故障导致数据丢失,建议适当地配置一些备份(或者叫复制因子)。
Ignite持久化
- 可以有两种方式开启持久化,第一个方式是,使用它自己的分布式、ACID以及兼容SQL的持久化,这可以透明地与所有的内存架构透明且高效地集成。
- 如果开启了原生持久化,Ignite会在磁盘上存储数据的超集,然后在内存中存储尽可能多的数据。比如,一共有100条数据,内存有能力存储20条,那么磁盘会存储所有的100条,而为了高性能,内存可以只缓存20条。
Ignite与第三方数据库
- 第二个开启持久化的方式,是将Ignite部署在已有的第三方数据库之上,比如RDBMS、Apache Cassandra或者MongoDB。这种方式通过将部分数据的副本放在内存中,用于对底层数据库进行加速。Ignite支持通读和通写模式,确保数据一致性以及两者之间的同步。
3、固化内存
Ignite基于固化内存架构,如果开启了原生持久化,可以同时处理存储于内存和磁盘上的数据和索引。
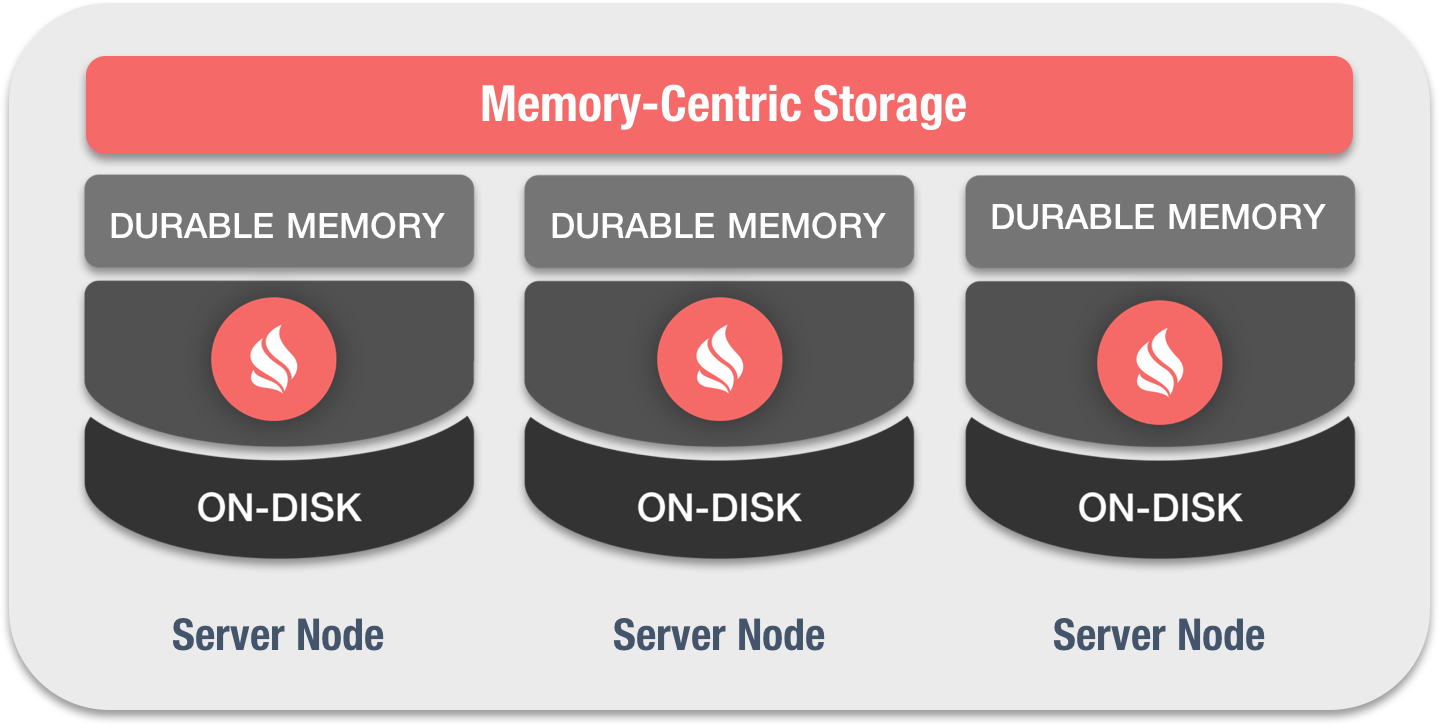
- 固化内存架构,它将内存计算的性能和扩展性,与磁盘持久化和强一致性整合到一个系统中。
- Ignite固化内存的操作方式,类似于比如Linux这样的操作系统的虚拟内存。但是两者的显著区别是,如果开启了持久化存储,除了将整个或者部分数据保存在内存中,还会将整个数据集加上索引放在磁盘上,而虚拟内存只是在内存用尽时才使用磁盘,磁盘只是用于交换用途。
Ignite原生持久化
Ignite原生持久化是数据持久化的一个非常灵活、可扩展以及方便的方式,它广泛应用于应用需要一个分布式内存数据库的场景中。
Ignite的原生持久化是一个分布式的、ACID、兼容SQL的磁盘存储,它可以与Ignite的固化内存无缝地集成,Ignite原生持久化是可选的,可以打开和关闭,如果关闭,Ignite就是一个纯内存存储。
Ignite作为一个平台,如果固化内存和原生持久化同时使用的优势和特点:
固化内存
- 堆外内存
- 避免明显的GC暂停
- 自动碎片整理
- 可预测的内存消耗
- 高SQL性能
磁盘
- 可选的持久化
- 支持闪存、SSD以及Intel的3D Xpoint
- 存储数据的超集
- 全事务化(预写日志WAL)
- 集群瞬时启动
第三方持久化
- Ignite可以用于已有第三方数据库的缓存层,包括RDBMS、NoSQL或者HDFS。
- 该方式用于对保存数据的底层数据库进行加速,Ignite将数据保存在内存中,在多个节点中进行分布,提供了更快的数据访问,它减少了应用和数据库之间因为数据移动导致的网络负载。
- 但是与原生持久化相比,是有很多限制的,比如,SQL查询只能在内存中保存的数据上执行,因此,首先需要将数据预先从磁盘加载到内存中。
交换空间
- 如果不希望使用原生持久化或者第三方持久化,还可以开启交换,这时,如果内存过载,内存中的数据会被移动到磁盘上的交换空间中,
- 如果开启了交换空间,Ignite将数据存储于内存映射文件(MMF)中,根据当前的内存使用过量,操作系统会将MMF的内容交换到磁盘。交换空间通常用于避免由于内存过载导致的内存溢出错误(OOME),以及需要更多时间来对集群进行缩放,从而对数据集进行更平均的分布的场景。
4、数据可视化
Ignite可以与很多数据可视化工具集成,通过图表或者丰富的图形,协助对存储在分布式缓存中的数据进行分析和解释,甚至提供可操作的建议。
IgniteWeb控制台:Ignite的Web控制台是一个基于Web的交互式管理工具, 功能包括:
- 创建、下载Ignite的各种配置;
从RDBMS中自动加载SQL元数据;
接入Ignite集群然后执行SQL;
管理和监控Ignite节点和缓存;
查看堆、CPU以及其它有用的节点和缓存的指标;
Tableau:Tableau是一个聚焦于商业智能的交互式数据可视化工具,通过Ignite的ODBC驱动,Tableau就可以接入Ignite集群,功能包括:
查询集群中存储的分布式数据;
缓存数据的表格或者图形展示;
使用Tableau支持的各种方式对数据进行分析;
Zeppelin:Apache Zeppelin是一个基于Web的记事本,可以交互式地对数据进行分析,通过Ignite的JDBC驱动,Zeppelin就可以接入集群,功能包括:
- 通过Ignite的SQL解释器获取分布式数据;
- 缓存数据的表格或者图形展示;
- 通过Scala执行分布式的计算。
5、Hadoop & Spark
5.1 Spark共享内存层
Apache Ignite提供了一个Spark RDD抽象的实现,他允许跨越多个Spark作业时方便地在内存内共享状态,在不同的Spark作业、worker或者应用之间,IgniteRDD为内存中的相同数据提供了一个共享、可变的视图,原生的SparkRDD无法在多个Spark作业或者应用之间进行共享。
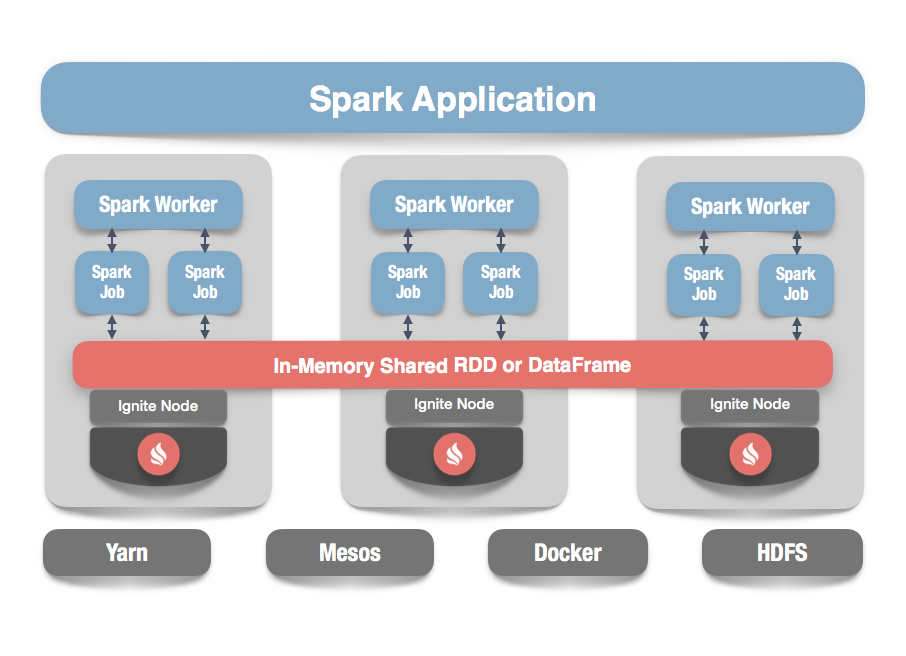
IgniteRDD作为Ignite分布式缓存的视图,既可以在Spark作业执行进程中部署,也可以在Spark worker中部署,也可以在它自己的集群中部署。
根据预配置的部署模型,状态共享既可以只存在于一个Spark应用的生命周期的内部(嵌入式模式),或者也可以存在于Spark应用的外部(独立模式)。
虽然SparkSQL支持丰富的SQL语法,但是它没有实现索引。这样即使在一个不太大的数据集上执行查询,也可能花费比较长的时间,因为需要对数据进行全部扫描。如果使用Ignite,开发者可以配置一级和二级索引,带来上千倍的性能提升。
Ignite DataFrames:
Spark的DataFrame API引入了模式的概念来描述数据,这样Spark就可以以表格的形式管理模式和组织数据。简而言之,DataFrame就是组织成命名列的分布式数据集合。它从概念上来说,等价于关系数据库的表,会促使Spark执行查询优化器,产生比RDD更高效的执行计划,而RDD仅仅是集群中的一个分区化的元素集合。Ignite扩展了DataFrame,如果将Ignite作为Spark的内存层,会简化开发以及提高性能,好处包括:
- 通过向Ignite读写DataFrames,可以在Spark作业之间共享数据和状态;
通过高级的索引以及避免数据在网络中的移动,优化Spark的查询执行计划,使Spark查询速度更快;
5.2 内存文件系统
Ignite一个独有的技术就是叫做Ignite文件系统(IGFS)的分布式内存文件系统,IGFS提供了和Hadoop HDFS类似的功能,但是仅仅在内存内部。事实上,除了他自己的API,IGFS实现了Hadoop的文件系统API,并且可以透明地加入Hadoop或者Spark应用。
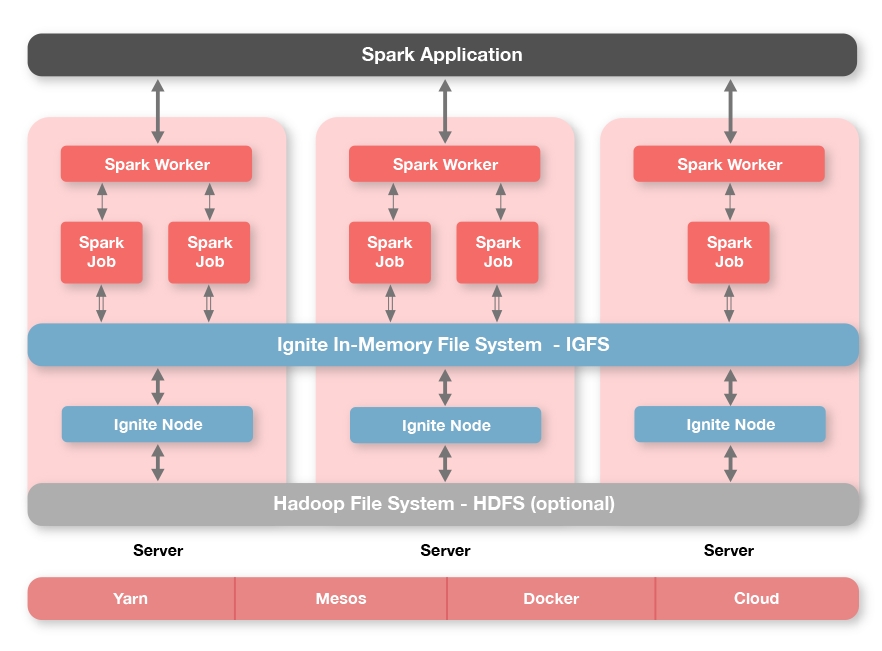
IGFS将每个文件中的数据拆分为独立的数据块然后将他们存储在分布式内存缓存中。然而和Hadoop HDFS不同,IGFS不需要一个name节点,并且用一个哈希函数自动地确定文件数据位置。
IGFS可以独立部署,也可以部署在HDFS之上,不管是哪种情况,他对于HDFS中存储的文件都是一个透明的缓存层。
IGFS可以与原生的Apache Hadoop发行版集成,也可以与Cloudera CDH、Hortonworks HDP集成。
Tachyon替代
在Spark环境中IGFS可以透明地替代Spark环境中的Tachyon文件系统,鉴于IGFS是基于久经考验的Ignite数据网格技术,他会比Tachyon有更好的读和写性能,并且更稳定。
Hadoop文件系统
如果打算使用IGFS作为Hadoop文件系统,可以参考Hadoop集成文档,这时IGFS和HDFS并没有什么不同。
5.3 内存MapReduce
Apache Ignite带来了一个Hadoop MapReduce API的内存实现,他比原生的Hadoop MapReduce实现有了显著的性能提升。Ignite MapReduce比Hadoop性能更好,是因为基于推的资源分配以及进程内的计算和数据的并置。

- 因为IGFS不需要一个name节点,当使用IGFS时,Ignite MapReduce作业会在一个链路内直达IGFS数据节点。
6、Ignite的应用场景
在线场景:包括在线的RDBMS数据缓存和在线分布式计算
离线场景:可用于一些在线的实时/准实时数据分析业务,另外可用于数据库存储过程替代
大数据平台:Ignite可用于搭建独立的大数据平台,用于大规模数据的注入、清洗、存储、查询、统计分析、出报表等全流程业务处理
传统大规模业务系统的分布式架构迁移:Ignite可以传统应用紧密整合,在不颠覆已有架构的前提下,帮助用户进行 传统应用的分布式架构转型。为运行多年的复杂、运行缓慢、技术架构落后的业务系统,提供加速能力的同时,引入众多的先进功能,大幅提升原有系统的能力
Ignite(二): 架构及工具的更多相关文章
- .Net架构必备工具列表
★微软MSDN:每个开发人员现在应该下载的十种必备工具 点此进入 ★网友总结.Net架构必备工具列表 Visual Studio 这个似乎是不言而喻的,只是从严谨的角度,也列在这.实际上,现在也有一个 ...
- mysql对比表结构对比同步,sqlyog架构同步工具
mysql对比表结构对比同步,sqlyog架构同步工具 对比后的结果示例: 执行后的结果示例: 点击:"另存为(S)" 按钮可以把更新sql导出来.
- 二维码工具类 - QrcodeUtils.java
二维码工具类,提供多种生成二维码.解析二维码的方法,包括中间logo的二维码等方法. 源码如下:(点击下载 - QrcodeUtils.java.MatrixToImageWriterEx.java. ...
- Ubuntu安装ARM架构GCC工具链(ubuntu install ARM toolchain)最简单办法
一.安装ARM-Linux-GCC工具链 只需要一句命令: sudo apt-get install gcc-arm-linux-gnueabi 前提是你的Ubuntu系统版本是官网支持的最新的版本, ...
- 【转】Ubuntu安装ARM架构GCC工具链(ubuntu install ARM toolchain)最简单办法
原文网址:http://www.cnblogs.com/muyun/p/3370996.html 一.安装ARM-Linux-GCC工具链 只需要一句命令: sudo apt-get install ...
- 【HELLO WAKA】WAKA iOS客户端 之二 架构设计与实现篇
上一篇主要做了MAKA APP的需求分析,功能结构分解,架构分析,API分析,API数据结构分析. 这篇主要讲如何从零做iOS应用架构. 全系列 [HELLO WAKA]WAKA iOS客户端 之一 ...
- Elasticsearch笔记二之Curl工具基本操作
Elasticsearch笔记二之Curl工具基本操作 简介: Curl工具是一种可以在命令行访问url的工具,支持get和post请求方式.-X指定http请求的方法,-d指定要传输的数据. 创建索 ...
- MIP开发教程(二) 使用MIP-CLI工具调试MIP网页
初始化 MIP 配置 新建一个 MIP 网页 编写 MIP 网页代码 校验 MIP 网页 调试 MIP 网页 1. 初始化 MIP 配置 首先在html目录下进行初始化 MIP 配置: $ mip i ...
- 单元测试系列之二:Mock工具Jmockit实战
更多原创测试技术文章同步更新到微信公众号 :三国测,敬请扫码关注个人的微信号,感谢! 原文链接:http://www.cnblogs.com/zishi/p/6760272.html Mock工具Jm ...
随机推荐
- commons-lang常用方法
跟java.lang这个包的作用类似,Commons Lang这一组API也是提供一些基础的.通用的操作和处理,如自动生成toString()的结果.自动实现hashCode()和equals()方法 ...
- while循环--登录
user = "fallen577" password = " count = 0 while count < 3: username = input(" ...
- 18-09-13 机器人和服务器之间的ip配置和脚本的重启
问题9 服务器安装完毕后 怎么配置机器人客户端的配置ip
- Linux系统上安装、卸载JAVA、TOMCAT的方法
一. 安装JAVA 安装方法1:手工上传 创建安装目录上传JAVA安装包 Normal 0 7.8 磅 0 2 false false false EN-US ZH-CN X-NONE /* Styl ...
- HTML入门标签学习
1.标题:<h1></h1>.<h2></h2>.<h3></h3>.<h4></h4>.<h5& ...
- iOS和小米手机拍照上传后,在web端显示旋转
( ′◔ ‸◔`)现在的公司啊都流行混合开发,我们公司也不例外,非要把交互非常多的社区模块用内嵌web页展示,好吧好吧,毕竟有的应用也是这么做的,那既然是社区就肯定少不了用户上传图片的操作,在开发阶段 ...
- 2018-软工机试-D-定西
单点时限: 1.0 sec 内存限制: 256 MB 这么多年你一个人一直在走 方向和天气的节奏会让你忧愁 你说你遇见了一大堆奇怪的人 他们看上去好像都比你开心 ——李志<定西> 这首歌的 ...
- [转]大白话讲解Promise(一)
http://www.cnblogs.com/lvdabao/p/es6-promise-1.html 去年6月份, ES2015正式发布(也就是ES6,ES6是它的乳名),其中Promise被列为正 ...
- sublime快捷键使用
sublime常用快捷键 自己觉得比较实用的sublime快捷键有: Ctrl+/..................注释 Ctrl+滚动..................字体变大.缩小 Ctrl+ ...
- nodejs故障cnpm没反应
莫名发生的故障cnpm没反应 重新整理nodejs使用流程 方案1 1.安装64位nodejs 2.设置代理 npm config set proxy http://127.0.0.1:9999 ...