【第4次作业】CNN实战
使用VGG模型进行猫狗大战
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
1、下载数据
2、数据处理
datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成 224×224×3 的大小,同时还将进行归一化处理。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) vgg_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]) #这里进行了修改,包括训练数据、验证数据、以及测试数据,分别在三个目录train/val/test
import shutil
data_dir = './cat_dog'
os.mkdir("./cat_dog/train/cat")
os.mkdir("./cat_dog/train/dog")
os.mkdir("./cat_dog/val/cat")
os.mkdir("./cat_dog/val/dog")
for i in range(10000):
cat_name = './cat_dog/train/cat_'+str(i)+'.jpg';
dog_name = './cat_dog/train/dog_'+str(i)+'.jpg';
shutil.move(cat_name,"./cat_dog/train/cat")
shutil.move(dog_name,"./cat_dog/train/dog") for i in range(1000):
cat_name = './cat_dog/val/cat_'+str(i)+'.jpg';
dog_name = './cat_dog/val/dog_'+str(i)+'.jpg';
shutil.move(cat_name,"./cat_dog/val/cat")
shutil.move(dog_name,"./cat_dog/val/dog")
#读取测试问题的数据集 test_path = "./cat_dog/test/dogs_cats"
os.mkdir(test_path)
#移动到test_path
for i in range(2000):
name = './cat_dog/test/'+str(i)+'.jpg'
shutil.move(name,"./cat_dog/test/dogs_cats") file_list=os.listdir("./cat_dog/test/dogs_cats")
#将图片名补全,防止读取顺序不对
for file in file_list:
#填充0后名字总共10位,包括扩展名
filename = file.zfill(10)
new_name =''.join(filename)
os.rename(test_path+'/'+file,test_path+'/'+new_name)
#将所有图片数据放到dsets内
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train','val','test']}
dset_sizes = {x: len(dsets[x]) for x in ['train','val','test']}
dset_classes = dsets['train'].classes
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['val'], batch_size=5, shuffle=False, num_workers=6)
#加入测试集
loader_test = torch.utils.data.DataLoader(dsets['test'], batch_size=5,shuffle=False, num_workers=6) '''
valid 数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出到 400
同时,把第一个 batch 保存到 inputs_try, labels_try,分别查看
'''
count = 1
for data in loader_test:
print(count, end=',')
if count%50==0:
print()
if count == 1:
inputs_try,labels_try = data
count +=1 print(labels_try)
print(inputs_try.shape)
# 显示图片的小程序 def imshow(inp, title=None):
# Imshow for Tensor.
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = np.clip(std * inp + mean, 0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# 显示 labels_try 的5张图片,即valid里第一个batch的5张图片
out = torchvision.utils.make_grid(inputs_try)
imshow(out, title=[dset_classes[x] for x in labels_try])

3. 创建 VGG Model
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
model_vgg = models.vgg16(pretrained=True)
with open('./imagenet_class_index.json') as f:
class_dict = json.load(f)
dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
inputs_try , labels_try = inputs_try.to(device), labels_try.to(device)
model_vgg = model_vgg.to(device)
outputs_try = model_vgg(inputs_try)
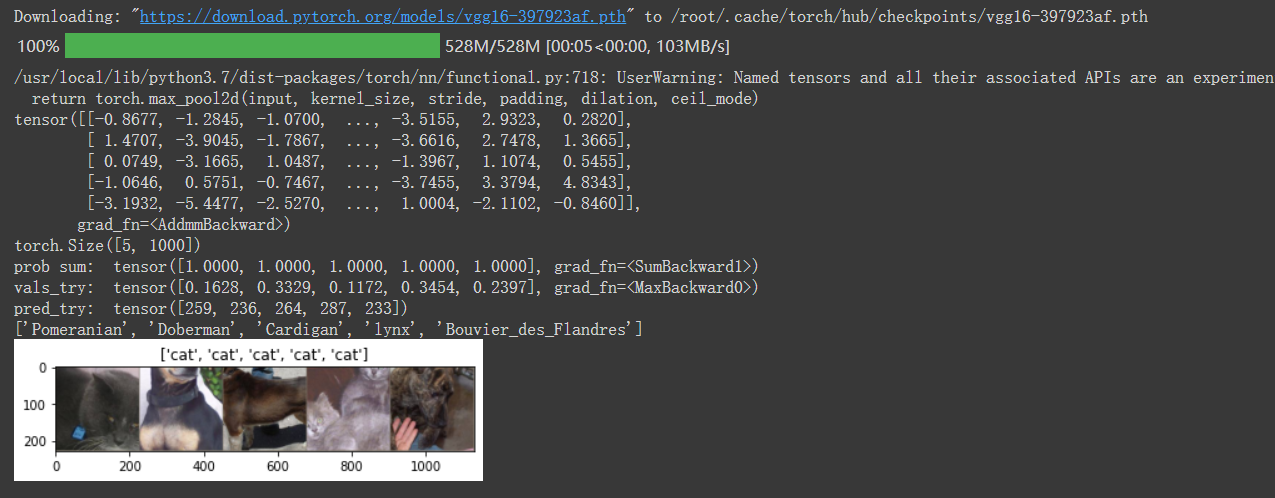
print(outputs_try)
print(outputs_try.shape)
'''
可以看到结果为5行,1000列的数据,每一列代表对每一种目标识别的结果。
但是我也可以观察到,结果非常奇葩,有负数,有正数,
为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数
'''
m_softm = nn.Softmax(dim=1)
probs = m_softm(outputs_try)
vals_try,pred_try = torch.max(probs,dim=1)
print( 'prob sum: ', torch.sum(probs,1))
print( 'vals_try: ', vals_try)
print( 'pred_try: ', pred_try)
print([dic_imagenet[i] for i in pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()),
title=[dset_classes[x] for x in labels_try.data.cpu()])
4. 修改最后一层,冻结前面层的参数
print(model_vgg) model_vgg_new = model_vgg; for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1) model_vgg_new = model_vgg_new.to(device) print(model_vgg_new.classifier)
5. 训练并测试全连接层
包括三个步骤:第1步,创建损失函数和优化器;第2步,训练模型;第3步,测试模型。
'''
第一步:创建损失函数和优化器 损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss() # 学习率
lr = 0.001 # 随机梯度下降
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr) '''
第二步:训练模型
''' def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train() for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc)) # 模型训练
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)
#验证模型正确率的代码
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('validing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes #predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['val'])
#如果使用的是已有的模型,应该跑下面这行代码
predictions, all_proba, all_classes = test_model(model_new,loader_valid,size=dset_sizes['val'])
#这个是对测试集进行预测的代码
def result_model(model,dataloader,size):
model.eval()
predictions=np.zeros((size,2),dtype='int')
i = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
outputs = model(inputs)
#_表示的就是具体的value,preds表示下标,1表示在行上操作取最大值,返回类别
_,preds = torch.max(outputs.data,1)
predictions[i:i+len(classes),1] = preds.to('cpu').numpy();
predictions[i:i+len(classes),0] = np.linspace(i,i+len(classes)-1,len(classes))
#可在过程中看到部分结果
print(predictions[i:i+len(classes),:])
i += len(classes)
print('creating: No. ', i, ' process ... total: ', size)
return predictions result = result_model(model_vgg_new,loader_test,size=dset_sizes['test'])
#如果使用的是已有的模型,应该跑下面这行代码
result = result_model(model_new,loader_test,size=dset_sizes['test']) #这里是生成结果的文件,上传到AI研习社可以看到正确率
np.savetxt("./cat_dog/result.csv",result,fmt="%d",delimiter=",")

6. 可视化模型预测结果(主观分析)
主观分析就是把预测的结果和相对应的测试图像输出出来看看,一般有四种方式:
随机查看一些预测正确的图片
随机查看一些预测错误的图片
预测正确,同时具有较大的probability的图片
预测错误,同时具有较大的probability的图片
最不确定的图片,比如说预测概率接近0.5的图片
# 单次可视化显示的图片个数
n_view = 8
correct = np.where(predictions==all_classes)[0]
from numpy.random import random, permutation
idx = permutation(correct)[:n_view]
print('random correct idx: ', idx)
loader_correct = torch.utils.data.DataLoader([dsets['valid'][x] for x in idx],
batch_size = n_view,shuffle=True)
for data in loader_correct:
inputs_cor,labels_cor = data
# Make a grid from batch
out = torchvision.utils.make_grid(inputs_cor)
imshow(out, title=[l.item() for l in labels_cor]) print(all_classes)
# 类似的思路,可以显示错误分类的图片,这里不再重复代码
【第4次作业】CNN实战的更多相关文章
- CNN实战篇-手把手教你利用开源数据进行图像识别(基于keras搭建)
我一直强调做深度学习,最好是结合实际的数据上手,参照理论,对知识的掌握才会更加全面.先了解原理,然后找一匹数据来验证,这样会不断加深对理论的理解. 欢迎留言与交流! 数据来源: cifar10 (其 ...
- python作业/练习/实战:生成双色球小程序
作业要求: 每注投注号码由6个红色球号码和1个蓝色球号码组成.红色球号码从1--33中选择:蓝色球号码从1--16中选择 代码范例 import random all_red_ball = [str( ...
- python作业/练习/实战:生成随机密码
作业要求1.写一个函数,函数的功能是生成一批密码,存到文件里面 def gen_password(num): #num代表生成多少条密码2.密码复杂度要求 1)长度在,8-16位之间 2)密码必须包括 ...
- python作业/练习/实战:3、实现商品管理的一个程序
作业要求 实现一个商品管理的一个程序,运行程序有三个选项,输入1添加商品:输入2删除商品:输入3 查看商品信息1.添加商品: 商品名称:xx 商品如果已经存在,提示商品已存在 商品价格:xx数量只能为 ...
- python作业/练习/实战:2、注册、登录(文件读写操作)
作业要求 1.实现注册功能输入:username.passowrd,cpassowrd最多可以输错3次3个都不能为空用户名长度最少6位, 最长20位,用户名不能重复密码长度最少8位,最长15位两次输入 ...
- python作业/练习/实战:1、简单登录脚本
作业要求 写一个登陆的小程序 username = xiaoming passwd = 123456 1.输入账号密码,输入正确就登陆成功, 提示:欢迎xxxx登陆,今天的日期是xxx. 2.输入错误 ...
- python作业/练习/实战:下载QQ群所有人的头像
步骤与提示:1.在腾讯群网页中进入任意一个群,获取相关信息,可以用postman是试一下,可以看到我们要的是mems里面的数据,需要获取到QQ号和群名片,如果没有群名片的话取昵称2.根据QQ号下载头像 ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- 深度学习之tensorflow2实战:多输出模型
欢迎来到CNN实战,尽管我们刚刚开始,但还是要往前看!让我们开始吧! 数据集 链接:https://pan.baidu.com/s/1zztS32iuNynepLq7jiF6RA 提取码:ilxh,请 ...
- Selenium自动化测试,接口自动化测试开发,性能测试从入门到精通
Selenium自动化测试,接口自动化测试开发,性能测试从入门到精通Selenium接口性能自动化测试基础部分:分层自动化思想Slenium介绍Selenium1.0/2.0/3.0Slenium R ...
随机推荐
- SpringCloud-Study
SpringCloud-Study 一.微服务简介 1.单体架构和分布式架构 单体架构 分布式架构 分布式架构的问题 解决方案 小结 2.微服务 微服务技术 微服技术对比 3.SpringCloud ...
- 学习C语言哟
之前一直用的vs,感觉还不错,现在新发现了 一个Lightly工具,非常好用,各种环境自动配置好 看着新奇,比codeblocks好多了,各种玩意儿一大堆,不过也都行,只是这个安装轻松点 开始我的第二 ...
- JSON中put、accumulate、elemate的区别
JSONObject.put():将value映射到key下,加入在JSONObject对象之前存在一个value存在key下,当前的value会替换之前的value. JSONObject.accu ...
- GFS预报数据下载
#更新#2019年6月12日之后,gfs预报场存放的目录变了,需要修改.get_gfs.pl第51行改为 $URL='https://nomads.ncep.noaa.gov/pub/data/ncc ...
- EXCEL函数总结
------------------截取"号"之前的字符 =MID(A45,1,FIND("号",A45,1)-1)
- simlink物体仿真中连接scope
该模块用于连接scope和multibody仿真中物理模型的输出值.
- Markdown 基础语法 备忘录
在vscode中使用Markdown先要安装一些插件: Markdown Preview Enhanced Paste Image LimfxCodeEX Code Spell Checker 一级标 ...
- 如何把百度地图左边的搜索列表导出成excel里?
有很多人问我,怎么样能够快速的把BAIDU地图左边的搜索列表里的商家地图,电话,导出到EXCEL里. 我就开发了一个小软件,专门为快速的实现导出数据到EXCEL. 为了使用方便,已经将全国的所又省份, ...
- k8s各个服务和执行流程介绍
Master节点部署的都是kubernetes的核心模块 APIServer 提供资源操作的唯一入口,并且提供认证/授权/kubernets的访问控制可以通过kubectl和自己开发的客户端,通过ht ...
- JavaScript Math(算数) 对象
JavaScript Math(算数) 对象 Math(算数)对象的作用是:执行常见的算数任务. 在线实例 round()如何使用 round(). random()如何使用 random() 来返回 ...