hadoop 文件参数配置
准备环境(省略)
- 上传实验所需的压缩包
- 配置网络信息
- 修改主机名
- 配置域名解析
- 关闭防火墙与SELinux(在所有节点上执行)代码如下:
systemctl disable --now firewalld
setenforce 0
vim /etc/selinux/config
修改:SELINUX=disabled
保存退出
(1)在 Master 节点上安装 Hadoop
步骤一:解压缩 hadoop-2.7.1.tar.gz安装包和jdk-8u152-linux-x86.tar.gz到/usr目录下

步骤二:将 hadoop-2.7.1文件夹和jdk-8u152文件夹重命名为 hadoop和jdk

步骤三:配置 Hadoop环境变量
注意:在第二章安装单机 Hadoop 系统已经配置过环境变量,先删除之前配置后添加

- 在文件末尾添加以下配置信息
分别将JAVA_HOME和HADOOP_HOME指向 JAVA安装目录;JAVA安装目录和HADOPOP安装目录加入 PATH路径

步骤四:使配置的 Hadoop的环境变量生效
- 切换进hadoop用户
- 使环境变量生效

步骤五:执行以下命令修改 hadoop-env.sh配置文件

- 在文件中间添加以下配置信息

(2)配置 hdfs-site.xml 文件参数
- 执行以下命令修改 hdfs-site.xml配置文件

- 在文件中和一对标签之间追加以下配置信息
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
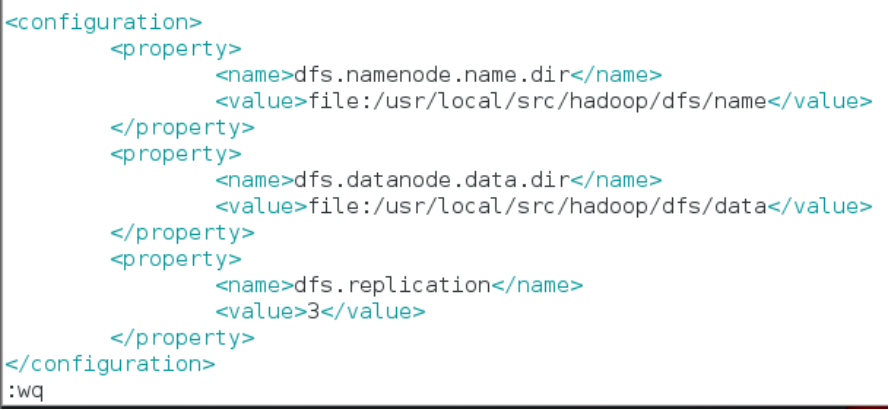
对于 Hadoop 的分布式文件系统 HDFS 而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。所以,修改 dfs.replication的配置,使 HDFS文件的备份副本数量设定为 3个
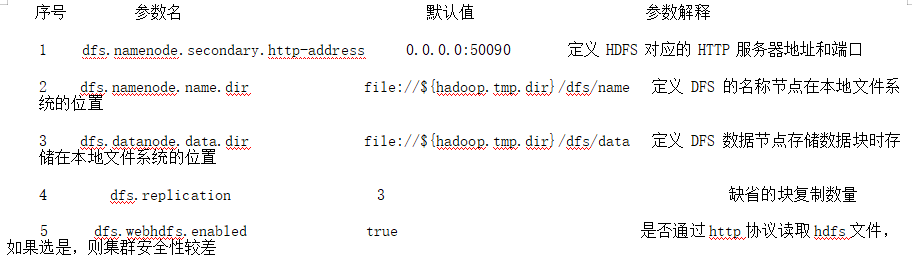
该配置文件中主要的参数、默认值、参数解释如下表所示:
hdfs-site.xml配置文件主要参数:
(3)配置 core-site.xml 文件参数
- 执行以下命令修改 core-site.xml配置文件
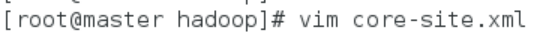
- 在文件中和一对标签之间追加以下配置信息
**此处master 为虚拟机IP,也可为自己域名解析内配置的hostname **
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
如没有配置 hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoop-hadoop。该目录在每次 Linux系统重启后会被删除,必须重新执行 Hadoop文件系统格式化命令,否则 Hadoop运行会出错
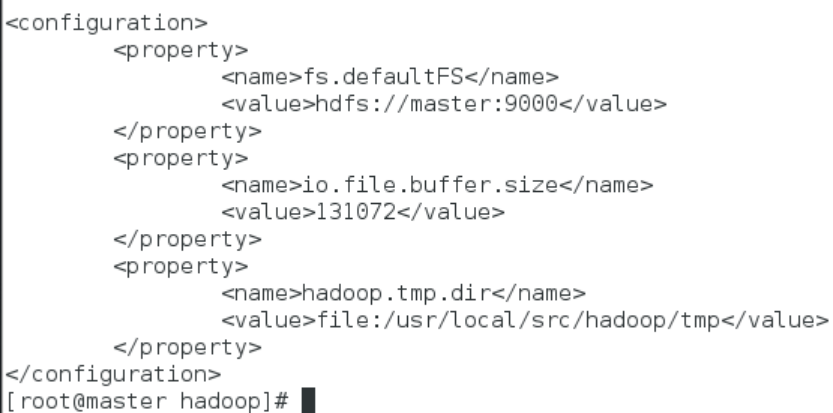
- 该配置文件中主要的参数、默认值、参数解释如下表所示:
core-site.xml配置文件主要参数:
(4)配置 mapred-site.xml
在“/usr/local/src/hadoop/etc/hadoop”目录下有一个 mapred-site.xml.template,需要修改文件名称,把它重命名为 mapred-site.xml,然后把 mapred-site.xml文件配置成如下内容
- 执行以下命令修改 mapred-site.xml配置文件
确保在该路径下执行此命令

- 在文件中和一对标签之间追加以下配置信息
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>

- 该配置文件中主要的参数、默认值、参数解释如下表 所示:
mapred-site.xml配置文件主要参数:

- Hadoop 提供了一种机制,管理员可以通过该机制配置 NodeManager 定期运行管理员提供的脚本,以确定节点是否健康。管理员可以通过在脚本中执行他们选择的任何检查来确定节点是否处于健康状态。如果脚本检测到节点处于不健康状态,则必须打印以字符串 ERROR开始的一行信息到标准输出。NodeManager 定期生成脚本并检查该脚本的输出。如果脚本的输出包含如上所述的字符串ERROR,就报告该节点的状态为不健康的,且由NodeManager将该节点列入黑名单,没有进一步的任务分配给这个节点。但是,NodeManager继续运行脚本,如果该节点再次变得正常,该节点就会从ResourceManager黑名单节点中自动删除。节点的健康状况随着脚本输出,如果节点有故障,管理员可用 ResourceManager Web界面报告,节点健康的时间也在 Web界面上显示
(5)配置 yarn-site.xml
- 执行以下命令修改 yarn-site.xml配置文件

- 在文件中和一对标签之间追加以下配置信息
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>

该配置文件中主要的参数、默认值、参数解释如下表 所示:

很显然,很多参数没有专门配置,多数情况下使用默认值。例如,可以追加以下两个参数 配 置 项yarn.resourcemanager.hostname( 即 资 源 管 理 器 主 机 ) 和“yarn.nodemanager.aux-services”(即 YARN节点管理器辅助服务),若要将主节点也作为资源管理主机配置,则配置值分别为“Master_hadoop”、“mapreduce_shuffle”。
在 yarn-site.xml 中可以配置相关参数来控制节点的健康监测脚本。如果只有一些本地磁盘出现故障,健康检查脚本不应该产生错误。NodeManager有能力定期检查本地磁盘的健康状况(特别是检查 NodeManager本地目录和NodeManager日志目录),并且在达到基于“yarn.nodemanager.disk-health-checker.min-healthy-disks”属性的值设置的坏目录数量阈值之后,整个节点标记为不健康,并且这个信息也发送到资源管理器。无论是引导磁盘受到攻击,还是引导磁盘故障,都会在健康检查脚本中标识
(6)Hadoop 其它相关配置
配置 masters文件
- 加入以下配置信息

- master主机 IP地址

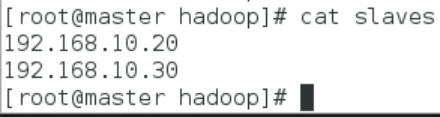
配置 slaves文件
本教材 Master 节点仅作为名称节点使用,因此将 slaves 文件中原来的 localhost 删除,并添加 slave1、slave2节点的 IP地址
- 删除 localhost,加入以下配置信息

- slave1主机 IP地址

- slave2主机 IP地址
新建目录
- 执行以下命令新建/usr/local/src/hadoop/tmp、/usr/local/src/hadoop/dfs/name、/usr/local/src/hadoop/dfs/data三个目录

修改目录权限
- 执行以下命令修改/usr/local/src/hadoop目录的权限


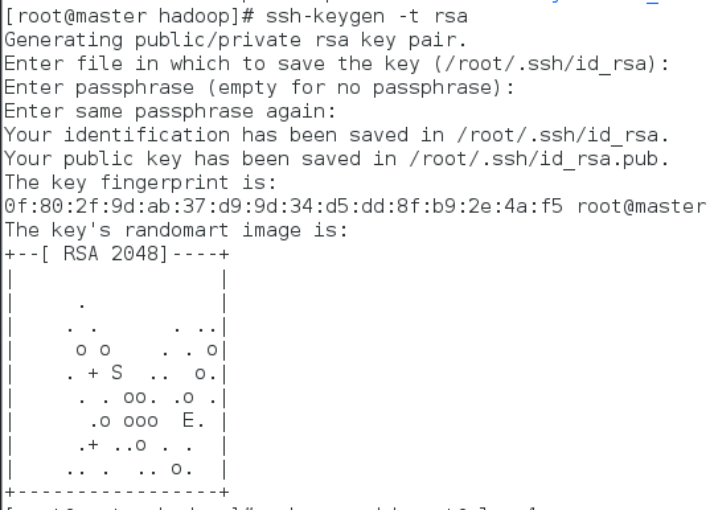
配置master能够免密登录所有slave节点
ssh-keygen -t rsa
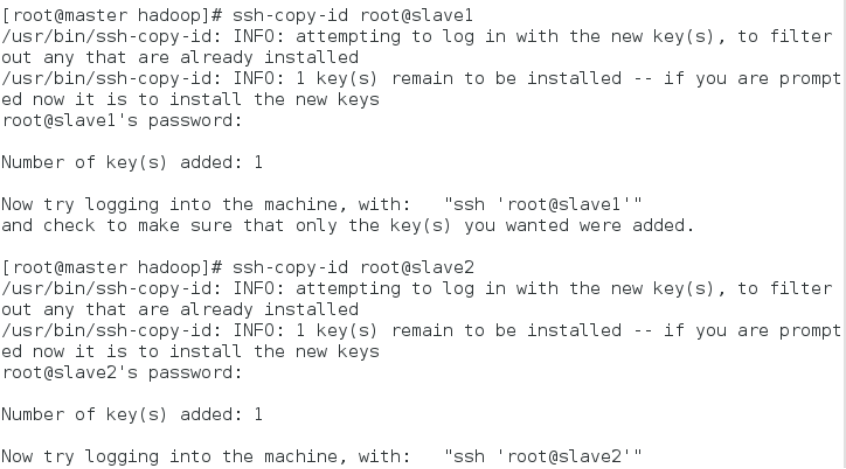
ssh-copy-id root@slave1
ssh-copy-id root@slave2
同步配置文件到 Slave节点
上 述 配 置 文 件 全 部 配 置 完 成 以 后 , 需 要 执 行 以 下 命 令 把 Master 节 点 上 的“/usr/local/src/hadoop”文件夹复制到各个 Slave节点上,并修改文件夹访问权限
将 Master上的 Hadoop安装文件同步到 slave1、slave2

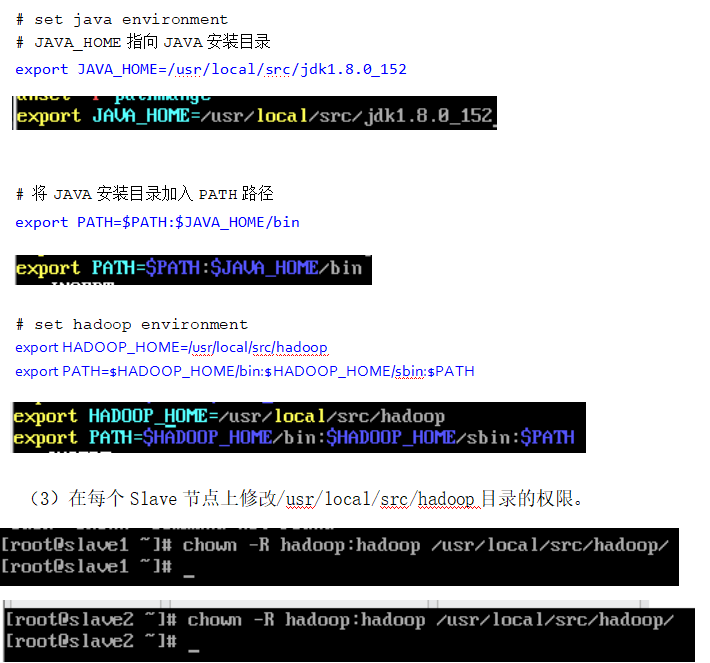
在每个 Slave节点上配置 Hadoop的环境变量
注意:若 slave1,slave2 在/usr/local/src/目录下jdk1.8.0_152 文件,需返回第二章安装好 Java环境分别进入slave节点


分别在slave1和slave2主机文件的末尾添加
在每个 Slave节点上切换到 hadoop用户
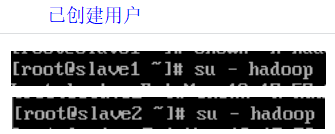
使每个 Slave节点上配置的 Hadoop的环境变量生效
hadoop 文件参数配置的更多相关文章
- 关于ofbiz加载数据模块的文件参数配置
1,在applications文件夹下新建一个数据模块meetingroom 2, 要让ofbiz加载这个数据模块就需要在applications下的配置文件里修改参数 (1)在application ...
- Django之用户上传文件的参数配置
Django之用户上传文件的参数配置 models.py文件 class Xxoo(models.Model): title = models.CharField(max_length=128) # ...
- ifcfg-eth0文件参数PREFIX 和 NETMASK的配置不一致问题
ifcfg-eth0文件参数PREFIX 和 NETMASK的配置不一致问题 摘自:https://blog.csdn.net/aikui0621/article/details/9148997 阅读 ...
- tp5 模板参数配置(模板静态文件路径)
tp5 模板参数配置(模板静态文件路径) // 模板页面使用 <link rel="stylesheet" type="text/css" href=&q ...
- SpringBoot - 实现文件上传1(单文件上传、常用上传参数配置)
Spring Boot 对文件上传做了简化,基本做到了零配置,我们只需要在项目中添加 spring-boot-starter-web 依赖即可. 一.单文件上传 1,代码编写 (1)首先在 stati ...
- Hi3559AV100 NNIE开发(3)RuyiStudio软件 .wk文件生成过程-mobilefacenet.cfg的参数配置
之后随笔将更多笔墨着重于NNIE开发系列,下文是关于Hi3559AV100 NNIE开发(3)RuyiStudio软件 .wk文件生成过程-mobilefacenet.cfg的参数配置,目前项目需要对 ...
- Hadoop集群配置(最全面总结)
Hadoop集群配置(最全面总结) 通常,集群里的一台机器被指定为 NameNode,另一台不同的机器被指定为JobTracker.这些机器是masters.余下的机器即作为DataNode也作为Ta ...
- hive参数配置详细
hive.exec.mode.local.auto 决定 Hive 是否应该自动地根据输入文件大小,在本地运行(在GateWay运行) true hive.exec.mode.local.auto.i ...
- Hadoop集群配置(最全面总结 )(转)
Hadoop集群配置(最全面总结) huangguisu 通常,集群里的一台机器被指定为 NameNode,另一台不同的机器被指定为JobTracker.这些机器是masters.余下的机器即作为Da ...
随机推荐
- 『忘了再学』Shell流程控制 — 38、while循环和until循环介绍
目录 1.while循环 2.until循环 1.while循环 对while循环来讲,只要条件判断式成立,循环就会一直继续,直到条件判断式不成立,循环才会停止.和for循环的第二种格式for((初始 ...
- Django cors跨域问题
Django cors跨域问题 前后端分离项目中的跨域问题 即同源策略 同源策略:同源策略/SOP(Same origin policy)是一种约定,由 Netscape 公司 1995 年引入浏览器 ...
- RPA供应链管制单修改机器人
背景:供应链环节中,研发物料时而因为市场缺货等原因无法采购,资材部需登入系统修改物料管制单. 操作流程:登录PDM系统中读取数据.登录ERP系统中更新数据. 人工操作:每日耗时3.5小时,出现一定比例 ...
- Nginx通过bat文件快速启动停止
新建文本文件NginxRun.bat.(名字无所谓,后缀名得是bat) 将以下代码复制到bat文件中即可. @echo off ::进入D盘 d: ::进入nginx目录 这里是自己的nginx目录 ...
- 内存泄漏定位工具之 valgrind 使用
1 前言 前面介绍了 GCC 自带的 mtrace 内存泄漏检查工具,该篇主要介绍开源的内存泄漏工具 valgrind,valgrind 是一套 Linux 下,开放源代码的动态调试工具集合,能够检测 ...
- 数据结构-二叉树(Binary Tree)
1.二叉树(Binary Tree) 是n(n>=0)个结点的有限集合,该集合或者为空集(空二叉树),或者由一个根节点和两棵互不相交的,分别称为根节点的左子树和右子树的二叉树组成. 2.特数二 ...
- labview从入门到出家7(进阶篇)--队列的使用
本节简单讲解队列在Labview中的使用,队列你可以认为就是一组先进先出的数据列表,在Labview中常用来缓存和传递数据.用了这么久的队列,个人认为有个方便的地方在于数据传递的把控,不管是局部变量还 ...
- java的类
public class demo01 { public static void main(String[] args) { //类名可用中文也可用英文,但是不建议用中文 String 王者荣耀=&q ...
- C++算数运算符和位运算符
C++根据功能和用途将运算符分为算数运算符.位运算符.关系运算符和逻辑运算符等不同类型.四种不同运算符的优先级从大到小依次位算-位-关-逻. 一.算数运算符 1.加减乘除(+ - * /) 加减乘除位 ...
- 常用的函数式接口_Consumer接口和常用的函数式接口_Consumer接口的默认方法andThen
Consumer接口 java,util.function.Consumer接口则正好与Supplier接口相反,它不是生产一个数据,而是消费一个数据,其数据类型由泛型决定 抽象方法:accept C ...