Learning with Mini-Batch
在机器学习中,学习的目标是选择期望风险\(R_{exp}\)(expected loss)最小的模型,但在实际情况下,我们不知道数据的真实分布(包含已知样本和训练样本),仅知道训练集上的数据分布。因此,我们的目标转化为最小化训练集上的平均损失,这也被称为经验风险\(R_{emp}\)(empirical loss)。
严格地说,我们应该计算所有训练数据的损失函数的总和,以此来更新模型参数(Batch Gradient Descent)。但随着数据集的不断增大,以ImagNet数据集为例,该数据集的数据量有百万之多,计算所有数据的损失函数之和显然是不现实的。若采用计算单个样本的损失函数更新参数的方法(Stochastic Gradient Descent),会导致\(R_{emp}\)难以达到最小值,而且在数值处理上不能使用向量化的方法提高运算速度。
于是,我们采取一种折衷的想法,即取一部分数据,作为全部数据的代表,让神经网络从这每一批数据中学习,这里的“一部分数据”称为mini-batch,这种方法称为mini-batch学习。
以下图为例,蓝色的线表示Batch Gradient Descent,紫色的线表示Stochastic Gradient Descent,绿色的线表示Mini-Batch Gradient Descent。
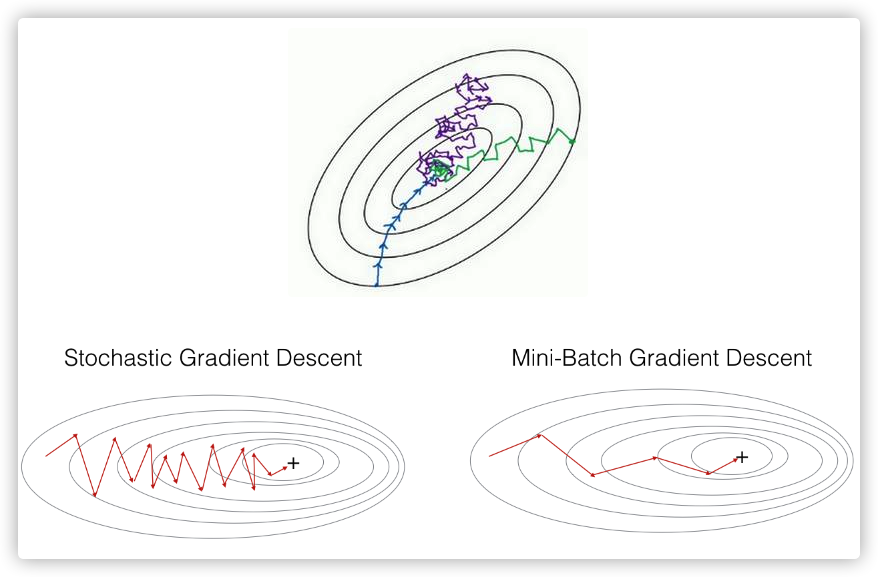
从上图可以看出,Mini-Batch相当于结合了Batch Gradient Descent和Stochastic Gradient Descent各自的优点,既能利用向量化方法提高运算速度,又能基本接近全局最小值。
对于mini-batch学习的介绍到此为止。下面我们将MINIST数据集上的分类问题作为背景,以交叉熵cross-entropy损失函数为例,来实现一下mini-bacth版的cross-entropy error。
给出cross-entropy error的定义如下:
\]
其中\(y_k\)表示神经网络输出,\(t_k\)表示正确解标签。
等式1表示的是针对单个数据的损失函数,现在我们给出在mini-batch下的损失函数,如下
\]
其中N表示这一部分数据的数量,\(t_{nk}\)表示第n个数据在第k个元素的值(\(y_{nk}\)表示神经网络输出,\(t_{nk}\)表示监督数据)
我们来看一下用Python如何实现mini-batch版的cross-entropy error。针对监督数据\(t_{nk}\)的标签形式是否为one-hot,我们分类讨论处理。
此外,需要明确的一点是,对于一个分类神经网络,最后一层经过softmax函数处理后,输出\(y_{nk}\)是一个\(n\)x\(k\)的矩阵,\(y_{ij}\)表示第i个数据被预测为\(j(0 \leq j\leq10)\)的概率,特别地,当\(N=1\)时,\(y\)是一个包含10个元素的向量,类似于[0.1,0.2...0.3],其中0.1表示输入数据预测为0的概率为0.1,0.2表示将输入数据预测为1的概率为0.2,其他情况以此类推。
首先,对于\(t_{nk}\)为one-hot表示的情况,代码块1如下
def cross_entropy_error(y,t):
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
在上面的代码中,我们在y上加了一个微小值,防止出现np.log(0)的情况,因为np.log(0)会变成负无穷大-inf,从而导致后续的计算无法继续进行。在等式2中\(y_{nk}\)与\(t_{nk}\)下标相同,所以我们直接使用*做element-wise运算,即对应元素相乘。
但当我们希望同时能够处理单个数据和批量数据时,代码块1还不能满足我们的要求。因为当\(N=1\)时,\(y\)是一个包含10个元素的一维向量,输入到函数中,batch_size将等于10而不是1,于是我们将代码块1进行进一步完善,如下:
def cross_entropy_error(y,t):
if y.ndim == 1:
y = y.reshape(1,y.size)
t = t.reshape(1,t.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
最后,来讨论一下\(t_{nk}\)为非one-hot表示的情况。在one-hot情况的计算中,t为0的元素cross-entropy error也为0,所以对于这些元素的计算可以忽略。换言之,在非one-hot表示的情况下,我们只需要计算正确解标签的交叉熵误差即可。代码如下:
def cross_entropy_error(y,t):
if y.ndim == 1:
y = y.reshape(1,y.size)
t = t.reshape(1,t.size)
batch_size = y.shape[0]
return -np.sum(1 * np.log(y[np.arange(batch_size),t]+1e-7))/batch_size
在上面的代码中,y[np.arange(batch_size),t]表示将从神经网络的输出中抽出与正确解标签相对应的元素。
参考文献
[1] 深度学习入门
[2] DeepLearning.ai深度学习课程笔记
[3] 统计学习方法
Learning with Mini-Batch的更多相关文章
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 聚类K-Means和大数据集的Mini Batch K-Means算法
import numpy as np from sklearn.datasets import make_blobs from sklearn.cluster import KMeans from s ...
- Deep Learning 27:Batch normalization理解——读论文“Batch normalization: Accelerating deep network training by reducing internal covariate shift ”——ICML 2015
这篇经典论文,甚至可以说是2015年最牛的一篇论文,早就有很多人解读,不需要自己着摸,但是看了论文原文Batch normalization: Accelerating deep network tr ...
- knn/kmeans/kmeans++/Mini Batch K-means/Affinity Propagation/Mean Shift/层次聚类/DBSCAN 区别
可以看出来除了KNN以外其他算法都是聚类算法 1.knn/kmeans/kmeans++区别 先给大家贴个简洁明了的图,好几个地方都看到过,我也不知道到底谁是原作者啦,如果侵权麻烦联系我咯~~~~ k ...
- Deep Learning中的Large Batch Training相关理论与实践
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 在分布式训练时,提高计算通信占比是提高计算加速比的有效手段,当网络通信优化到一 ...
- Deep learning:四十八(Contractive AutoEncoder简单理解)
Contractive autoencoder是autoencoder的一个变种,其实就是在autoencoder上加入了一个规则项,它简称CAE(对应中文翻译为?).通常情况下,对权值进行惩罚后的a ...
- Deep learning:四十二(Denoise Autoencoder简单理解)
前言: 当采用无监督的方法分层预训练深度网络的权值时,为了学习到较鲁棒的特征,可以在网络的可视层(即数据的输入层)引入随机噪声,这种方法称为Denoise Autoencoder(简称dAE),由Be ...
- Machine Learning Algorithms Study Notes(2)--Supervised Learning
Machine Learning Algorithms Study Notes 高雪松 @雪松Cedro Microsoft MVP 本系列文章是Andrew Ng 在斯坦福的机器学习课程 CS 22 ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week2, Assignment(Optimization Methods)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. 请不要ctrl+c/ctrl+v作业. Optimization Methods Until now, you've always u ...
- 图像分类(二)GoogLenet Inception_v2:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Inception V2网络中的代表是加入了BN(Batch Normalization)层,并且使用 2个 3*3卷积替代 1个5*5卷积的改进版,如下图所示: 其特点如下: 学习VGG用2个 3* ...
随机推荐
- java mybatisplus+springboot服务器跨域问题
项目本地增删改测试正常,上传到 阿里服 页面出现了 跨域报错问题! 解决方案:添加一个过滤器 package com.rl;import org.springframework.stereotyp ...
- Write down for Segments, Extents, and Blocks
Segments, Extents, and Blocks(段.区.块) • Segments exist in a tablespace. • Segments are collections of ...
- js中的call()、apply()、bind()方法
var a= { name:"李四", age: "五岁", text: function() { return this.name+ " " ...
- HTML完整语法学习
https://www.cnblogs.com/douluo/archive/2021/11/20/15582217.html
- HDFS、Ceph、GFS、GPFS、Swift、Lustre……容器云选择哪种分布式存储更好?
HDFS.Ceph.GFS.GPFS.Swift.Lustre--容器云选择哪种分布式存储更好?-51CTO.COM 容器云在使用分布式存储时,HDFS.CEPH.GFS.GPFS.Swift等分布式 ...
- 第12章 使用 Entity Framework Core 保存数据(ASP.NET Core in Action, 2nd Edition)
本章包括(请点击这里阅读其他章节) 什么是实体框架核心以及为什么应该使用它 向 ASP.NET Core 应用程序添加实体框架核心 构建数据模型并使用它创建数据库 使用实体框架核心查询.创建和更新数据 ...
- aos.js 与 swiper 组合,翻页后无法触发aos的效果
手动给除第一页之外的需要特效的元素添加 class="aos-animate" 转自:https://cloud.tencent.com/developer/ask/sof/302 ...
- vim实用用法
1 dd 删除1行 1 gg 跳到第一行 G 文本最后 C 删除当前光标到行尾,并进入插入模式 D 删除当前光标到行尾 dw 删除一个单词 yw 复制一个单词 r /PATH/FROM/SOMEFIL ...
- 对volatile修饰的变量使用memset函数
背景 今天面试了一家公司,面试官问了我一个开放性的问题.大致意思是,为什么对volatile修饰的变量调用memset函数,编译的时候会报错.当然,我是不知道为什么啦.之前没有遇到过嘛.不过我还是做了 ...
- docker安装nginx挂载启动
docker pull nginx 命令安装 查找 Docker Hub 上的 nginx 镜像: docker search nginx 这里我们拉取官方的镜像 docker pull nginx ...