VDO虚拟数据优化
VDO
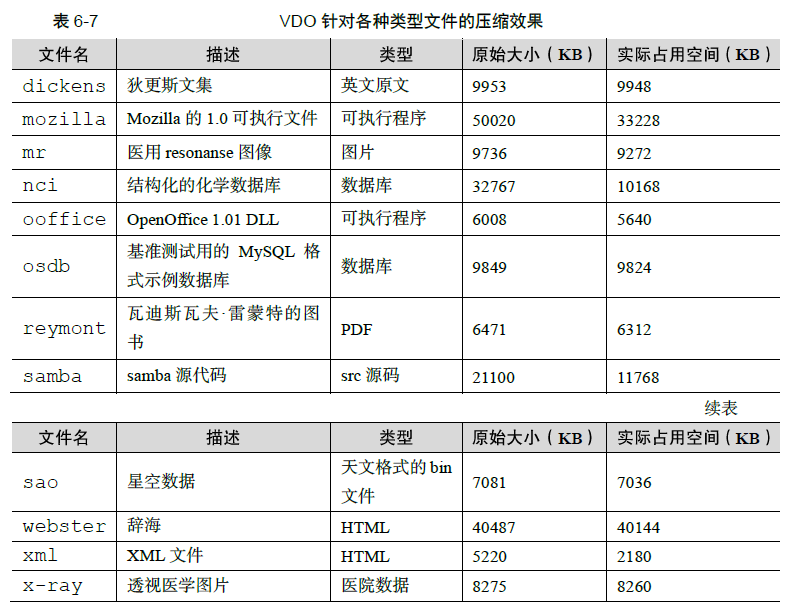
Virtual Data Optimize 虚拟数据优化 是一种通过压缩或删除存储设备上的数据来优化存储空间的技术。 VDO 是红帽公司收购了 Permabit 公司后获取的新技术,并与2019 2020 年前后,多次 在 RHEL 7.5/7.6/7.7 上进行测试,最终随 RHEL 8 系统正式公布。VDO技术的关键就是对硬盘内原有的数据进行删重操作,它有点类似于我们平时使用的网盘服务,在第一次正常上传文件时速度特别慢,在第二次上传 相同的文件 时 仅作为一个数据指针 几乎可以达到 秒传 的 效果,无须再多占用一份空间 也不用再漫长等待。除了删重操作,VDO 技术还可以对日志和数据库进行自动压缩,进一步减少存储浪费的情况 。 VDO 针对各种类型文件的压缩效果如表
VDO技术支持本地存储和远程存储,可以作为本地文件系统、iSCSI或Ceph存储下的附加存储层使用。红帽公司在VDO介绍页面中提到,在部署虚拟机或容器时,建议采用逻辑存储与物理存储为10∶1的比例进行配置,即1TB物理存储对应10TB逻辑存储;而部署对象存储时 (例如使用Ceph)则采用逻辑存储与物理存储为3∶1的比例进行配置,即使用1TB物理存储对应3TB逻辑存储。
简而言之,VDO技术能省空间!
有两种特殊情况需要提前讲一下。其一,公司服务器上已有的dm-crypt之类的技术是可以与VDO技术兼容的,但记得要先对卷进行加密再使用VDO。因为加密会使重复的数据变得有所不同,因此删重操作无法实现。要始终记得把加密层放到VDO之下,

其二,VDO技术不可叠加使用,1TB的物理存储提升成10TB的逻辑存储没问题,但是再用10TB翻成100TB就不行了。左脚踩右脚,真的没法飞起来。
一、我们把虚拟机关闭,添加一块容量为20GB的新SATA硬盘进来,开机后就能看到这块名称为/dev/sdb的新硬盘了
二、创建一个全新的VDO卷
新添加进来的物理设备就是使用vdo 命令来管理的,其中 name 参数代表新的设备卷的名称 device 参数代表由哪块磁盘进行制作; vdoLogicalSize 参数代表制作后的 设备 大小 。 依据红帽公司推荐的原则, 20GB 硬盘将翻成 200GB 的 逻辑存储。备注:如果记不住创建vdo的命令,可以通过man vdo | grep Logical 查询命令
vdo create --name=storge --device=/dev/sda --vdoLogicalSize=100G

通过fdisk -l 可以看到我们创建的这个ODV卷成功了,
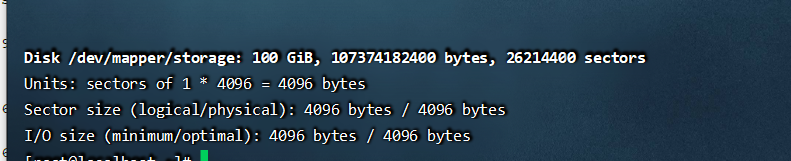
三、在创建成功后,使用status参数查看新建卷的概述信息,也可以使用(vdo status name=storage)查看具体的信息
vdostats --human-readable (查看摘要信息)

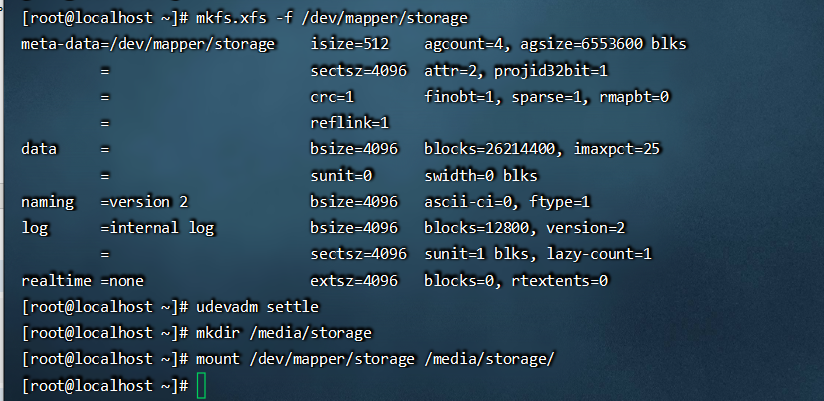
四、对新建卷进行格式化操作并挂载使用
新建的VDO卷设备会被乖乖地存放在/dev/mapper目录下,并以设备名称命名,对它操作就行。另外,挂载前可以用udevadm settle命令对设备进行一次刷新操作,避免刚才的配置没有生效:
mkfs.xfs /dev/mapper/storage 进行格式化 udevadm settle 对设备刷新 mkdir /media/storage 创建于storage挂载目录 mount /dev/mapper/storage /media/storage/ 挂载,如果要永久挂载必须修改/etc/fstab配置文件。
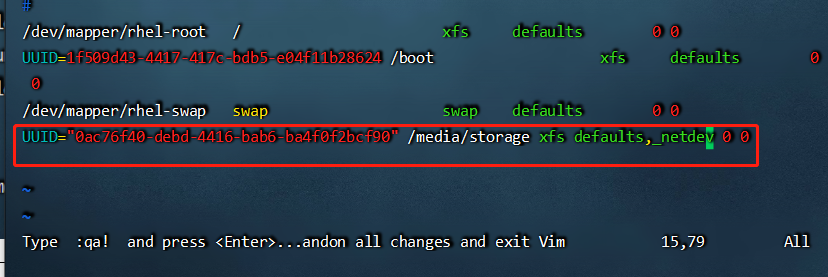
永久挂载设置,通过blkid查看UUID,然后再编辑/etc/fstab配置文件,一定加上_netdev,否则重启电脑会重启不了。
UUID="0ac76f40-debd-4416-bab6-ba4f0f2bcf90" /media/storage xfs defaults,_netdev 0 0
五、测试他的压缩性和去重性,
复制多一个文件到storage目录下,
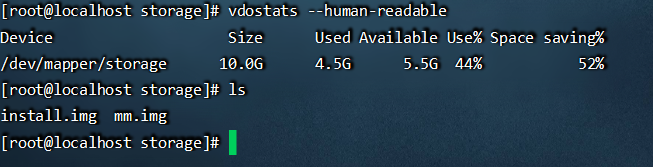
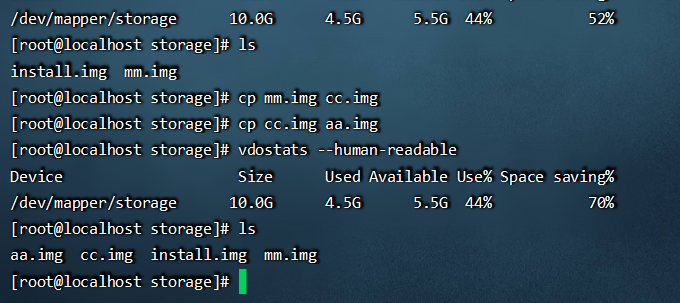
目前有四个文件,可以看到还5.5G,说明去重性非常的好。
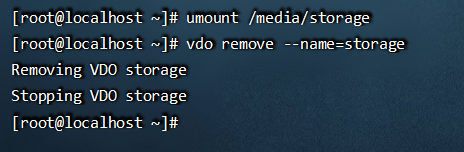
六、删除ODV卷
umount /media/storage 取消挂 vdo remove --name=storage 移除vdo卷
VDO虚拟数据优化的更多相关文章
- jmeter执行case结果插入DB数据优化
访问初始实现路径:jmeter执行case结果插入DB生成报表和备份记录 借前面实现导入DB数据先说明之前数据的缺点: 第一,若需要依赖接口的数据,会把依赖接口的case统计进去造成数据统计错误.第二 ...
- Flask实战-留言板-使用Faker生成虚拟数据
使用Faker生成虚拟数据 创建虚拟数据是编写Web程序时的常见需求.在简单的场景下,我们可以手动创建一些虚拟数据,但更方便的选择是使用第三方库实现.流行的python虚拟数据生成工具有Mimesis ...
- JDBC批量插入数据优化,使用addBatch和executeBatch
JDBC批量插入数据优化,使用addBatch和executeBatch SQL的批量插入的问题,如果来个for循环,执行上万次,肯定会很慢,那么,如何去优化呢? 解决方案:用 preparedSta ...
- oracle12c中新能优化新特性之热度图和自动数据优化
1. Oracle12c热度图和自动数据优化 信息生命周期管理(ILM)是指在数据生命周期内管理它们的策略.依赖于数据的年龄和对应用的业务相关性,数据能被压缩,能被归档或移到低成本的存储上.简言之,I ...
- faker之python构造虚拟数据
python中可以使用faker来制造一些虚拟数据 首选安装faker pip install Faker 老版的叫法是faker-factory,但是已不适用 使用faker.Factory.cre ...
- 利用ForgeryPy生成虚拟数据
在程序研发过程中,我们往往需要大量的虚拟实验数据.Python中有多个包可以用于生成虚拟数据,其中功能较为完善的是ForgeryPy. 1 安装 采用pip进行安装: pip install Forg ...
- 基于虚拟数据的行人检测研究(Expecting the Unexpected: Training Detectors for Unusual Pedestrians with Adversarial Imposters)
Paper Link : https://arxiv.org/pdf/1703.06283 Github: https://github.com/huangshiyu13/RPNplus 摘要: 这篇 ...
- 项目 07 Model与数据优化
项目班 07 Model与数据优化 html默认可以用直接用的方法和变量 {{ static_url(p.image_url) }} #static_url表示直接获取静态文件url {{ handl ...
- DB-SQL-MySQL-杂项-调优:Mysql千万以上数据优化、SQL优化方法
ylbtech-DB-SQL-MySQL-杂项-调优:Mysql千万以上数据优化.SQL优化方法 1.返回顶部 1. 1,单库表别太多,一般保持在200以下为宜 2,尽量避免SQL中出现运算,例如se ...
随机推荐
- 机械学习笔记1 -> Solidworks三维产品设计与建模1 | 建模基础入门
学习之余,课余了解一点点,作为爱好,妄想以后能够设计机甲出来. 学习来源是Solidworks三维产品设计与建模 00 工作界面介绍 00-1 概览 有时菜单栏和工具栏会重叠在一起,只有点击左侧三角才 ...
- 测试odbc连接sqlsever数据库是否成功的代码
1 #include<stdio.h> 2 #include<stdlib.h> 3 #include<windows.h> 4 #include<sql.h ...
- Servlet的response乱码问题
一.response有两种输出流(编码:UTF-8): 1.字节流:response.getOutputStream().write(date.getBytes("UTF-8")) ...
- Dubbo 使用过程中都遇到了些什么问题?
在注册中心找不到对应的服务,检查 service 实现类是否添加了@service 注解 无法连接到注册中心,检查配置文件中的对应的测试 ip 是否正确
- 什么是 Spring Cloud Bus?我们需要它吗?
考虑以下情况:我们有多个应用程序使用 Spr ng Cloud Config 读取属性,而S ring Cloud Config 从GIT 读取这些属性. 下面的例子中多个员工生产者模块从 Employe ...
- 你对 Spring Boot 有什么了解?
事实上,随着新功能的增加,弹簧变得越来越复杂.如果必须启动新的 spring 项 目,则必须添加构建路径或添加 maven 依赖项,配置应用程序服务器,添加 spring 配置.所以一切都必须从头开始 ...
- 学习openstack(八)
一.OpenStack初探 1.1 OpenStack简介 OpenStack是一整套开源软件项目的综合,它允许企业或服务提供者建立.运行自己的云计算和存储设施.Rackspace与NASA是最初 ...
- Python - 分支循环、可迭代对象与迭代器
- 【leetcode 29】 两数相除(中等)
题目描述 给定两个整数,被除数 dividend 和除数 divisor.将两数相除,要求不使用乘法.除法和 mod 运算符. 返回被除数 dividend 除以除数 divisor 得到的商. 整数 ...
- LQR (线性二次型调节器)的直观推导及简单应用
转自:https://blog.csdn.net/heyijia0327/article/details/39270597 本文主要介绍LQR的直观推导,说明LQR目标函数J选择的直观含义以及简单介绍 ...