KMeans算法与GMM混合高斯聚类
一、K-Means

- 初始K个类(簇心)
- E步:对每个样本,计算到K个类的欧式距离,并分配类标签 O(kNd)
- M步:基于类内的样本,以样本均值更新类(均值最小化,类到类内样本的误差) O(Nd)
- 重复2-3步,直到聚类结果不变化或收敛
# 基于Cursor生成的代码
import numpy as np def k_means(X, k, max_iters=100):
# randomly initialize centroids
centroids = X[np.random.choice(range(len(X)), k, replace=False)] for i in range(max_iters):
# calculate distances between each point and each centroid
distances = np.sqrt(((X - centroids[:, np.newaxis])**2).sum(axis=2)) # assign each point to the closest centroid
labels = np.argmin(distances, axis=0) # update centroids to be the mean of the points assigned to them
for j in range(k):
centroids[j] = X[labels == j].mean(axis=0) return centroids, labels d = 3
k = 3
X = np.random.rand(100, 3)
centroids, labels = k_means(X, k, max_iters=100) import matplotlib.pyplot as plt fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=labels, cmap='viridis')
ax.scatter(centroids[:, 0], centroids[:, 1], centroids[:, 2], marker='*', s=300, c='r') ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label') plt.show()
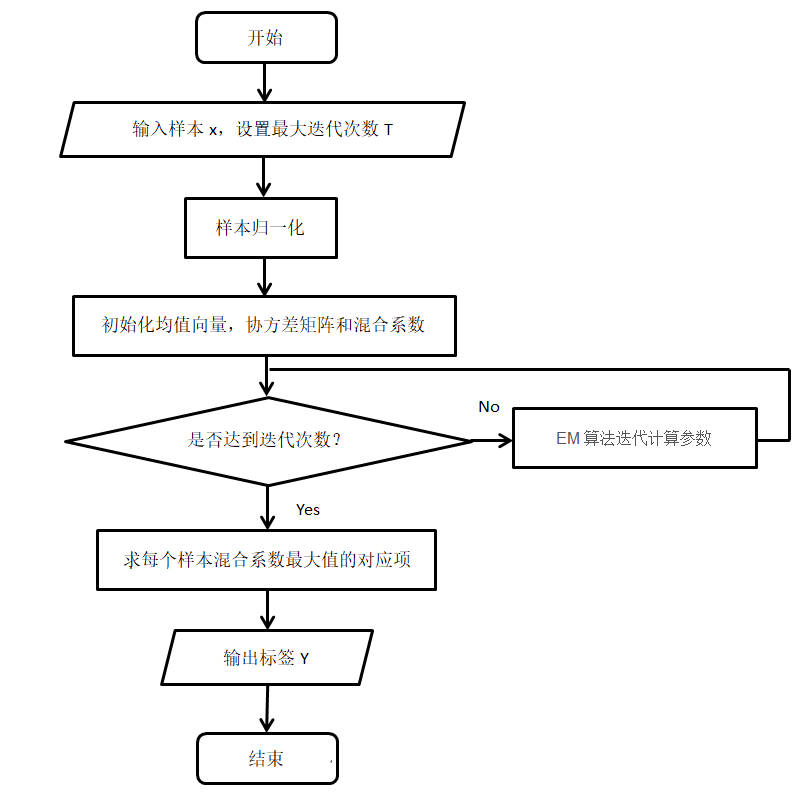
二、GMM
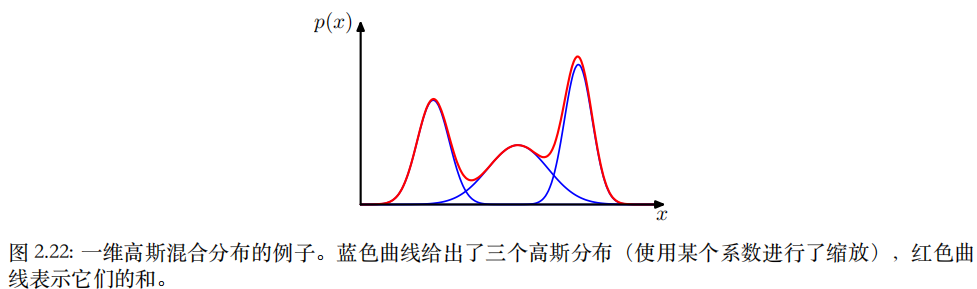

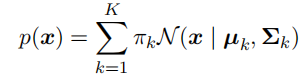
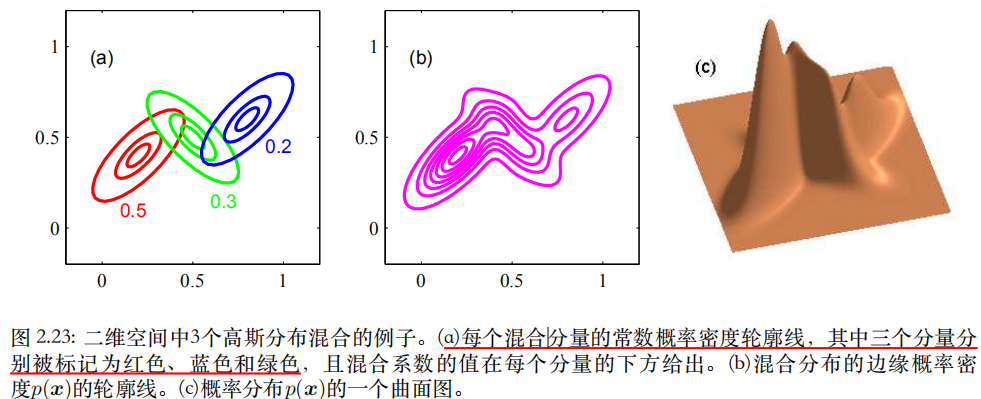
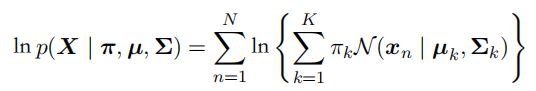
- ⼀种最⼤化这个似然函数的⽅法是使⽤迭代数值优化⽅法。
- 另⼀种是使⽤EM期望最⼤化算法(对包含隐变量的似然进行迭代优化)。
- 期望:根据参数,更新样本关于类的响应度(隶属度,相当于分别和K个类计算距离并归一化)。确定响应度,就可以确定EM算法的Q函数(完全数据的对数似然关于 分布的期望),原始似然的下界。
- 最大化:根据响应度,计算均值、方差。
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture
from sklearn.cluster import KMeans # 创建数据,并可视化
X, y = datasets.make_blobs(n_samples=1500,
cluster_std=[1.0, 2.5, 0.5],
random_state=170)
plt.figure(figsize=(12,4))
plt.rcParams['font.family'] = 'STKaiti'
plt.rcParams['font.size'] = 20
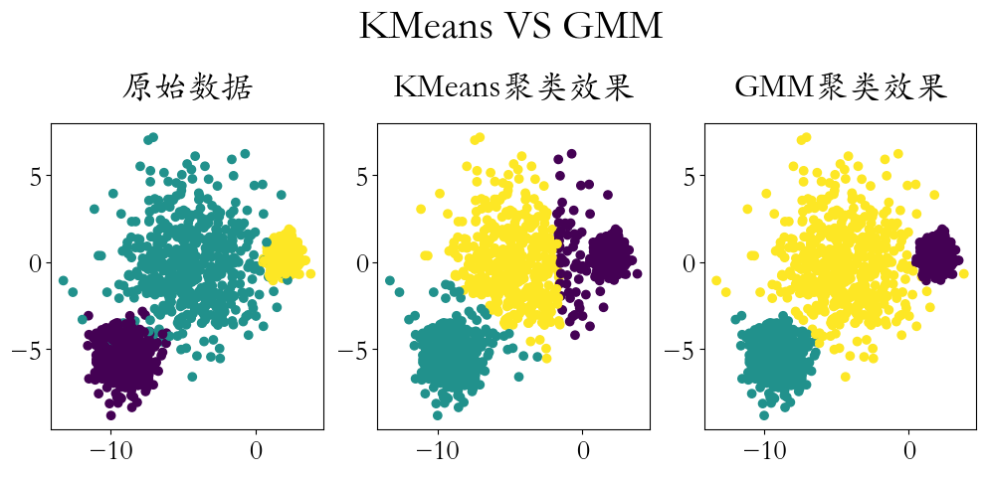
plt.subplot(1,3,1)
plt.scatter(X[:,0],X[:,1],c = y)
plt.title('原始数据',pad = 20)
kmeans = KMeans(3)
kmeans.fit(X)
y_ = kmeans.predict(X)
plt.subplot(1,3,2)
plt.scatter(X[:,0],X[:,1],c = y_)
plt.title('KMeans聚类效果',pad = 20)
gmm = GaussianMixture(n_components=3)
y_ = gmm.fit_predict(X)
plt.subplot(1,3,3)
plt.scatter(X[:,0],X[:,1],c = y_)
plt.title('GMM聚类效果',pad = 20) plt.figtext(x = 0.51,y = 1.1,s = 'KMeans VS GMM',ha = 'center',fontsize = 30)
plt.savefig('./GMM高斯混合模型.png',dpi = 200)
- 可以完成大部分形状的聚类
- 大数据集时,对噪声数据不敏感
- 对于距离或密度聚类,更适合高维特征
- 计算复杂高,速度较慢
- 难以对圆形数据聚类
- 需要在测试前知道类别的个数(成分个数,超参数)
- 初始化参数会对聚类结果产生影响
KMeans算法与GMM混合高斯聚类的更多相关文章
- 吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np import matplotlib.pyplot as plt from sklearn import mixture from sklearn.metrics ...
- Kmeans算法的K值和聚类中心的确定
0 K-means算法简介 K-means是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一. K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的 ...
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- 聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
一.层次聚类 1.层次聚类的原理及分类 1)层次法(Hierarchicalmethods)先计算样本之间的距离.每次将距离最近的点合并到同一个类.然后,再计算类与类之间的距离,将距离最近的类合并为一 ...
- 【cs229-Lecture12】K-means算法
上课内容: 无监督学习: K-means聚类算法 混合高斯模型 jensen不等式(用于推导出EM算法的一般形式) EM(Expectation Maximization)算法(最大期望算法) K-m ...
- K-means算法简介
K-means 算法是无监督的 聚类算法,算法简单,有效. K-means算法: 输入参数: 指定聚类数目 k,训练集 X 输出 : k 个聚类 算法描述: K-means 算法 是一个 迭代算法,每 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- 机器学习——K-Means算法
1 基础知识 相似度或距离 假设有 $m$ 个样本,每个样本由 $n$ 个属性的特征向量组成,样本合集 可以用矩阵 $X$ 表示 $X=[x_{ij}]_{mn}=\begin{bmatrix}x_{ ...
- sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM
1 sklearn聚类方法详解 2 对比不同聚类算法在不同数据集上的表现 3 用scikit-learn学习K-Means聚类 4 用scikit-learn学习DBSCAN聚类 (基于密度的聚类) ...
随机推荐
- EF调用sql语句
1.连接数据库 2.在Dal进行调用sql语句 public List<UserInfo> PageShow(out int totalcount,out int totalpage, s ...
- Maven-高级
Mvaen 高级 1 导入其他工程 资源文件 先install到仓库里 然后根据组织名项目名版本号写在dependence里正常导入 <dependence> <groupId> ...
- Q:Win10无法访问共享文件夹。提示此用户无法登录,因为该账户当前已被禁用
问题:当我访问同事电脑共享文件夹时,弹出如下提示框: 可以在命令提示符上ping通对方主机,但是不能访问对方文件夹 尝试解决方法(无效): 1.同时按住win+r打开运行命令框,输入gpedit.ms ...
- js 遍历对象属性
function* objectEntries(obj) { let propKeys = Reflect.ownKeys(obj); for (let propKey of propKeys) { ...
- What Are You Weighting For?
A basic strength routine can change your life Strength training isn't just about getting six-pack ab ...
- JS和PHP中能转为布尔false的值的对比
实际开发中经常会使用到JS和PHP中的变量转布尔值进行条件判断,下面对两种语言中转布尔类型结果为false的值进行对比,加深记忆和方便引用. 除了下表列出项,其它的值均转成真值true . 转布尔值后 ...
- 行转列 && 字段拆分
explode称之为Hive爆炸函数,意思就是将一行数据炸开.Usage:explode(array/map) explode函数传递的参数必须是一个array或者是map hivescala> ...
- 中文数据导入到hive,出现乱码
中文数据导入到hive,出现乱码 解决方法: 右键要导入的数据文件,选择用Notepad++打开,然后点击"编辑"-->转为UTF-8,最后保存即可. 然后在上传到指定路径下 ...
- Caused by: java.lang.ClassNotFoundException: Class org.openx.data.jsonserde.JsonSerDe not found
Caused by: java.lang.ClassNotFoundException: Class org.openx.data.jsonserde.JsonSerDe not found 解决方法 ...
- (转)解决ubuntu下拼音输入法出错的问题
一.如果仅在中文输入法下出现按键映射错位而英文输入下正常的情况,则在终端下输入以下命令即可: ibus-daemon -drx 二.如果拼音正常但打出来显示 "[Invalid UTF-8] ...