Neural Network模型复杂度之Residual Block - Python实现
背景介绍
Neural Network之模型复杂度主要取决于优化参数个数与参数变化范围. 优化参数个数可手动调节, 参数变化范围可通过正则化技术加以限制. 本文从优化参数个数出发, 以Residual Block技术为例, 简要演示Residual Block残差块对Neural Network模型复杂度的影响.算法特征
①. 对输入进行等维度变换; ②. 以加法连接前后变换扩大函数空间算法推导
典型残差块结构如下,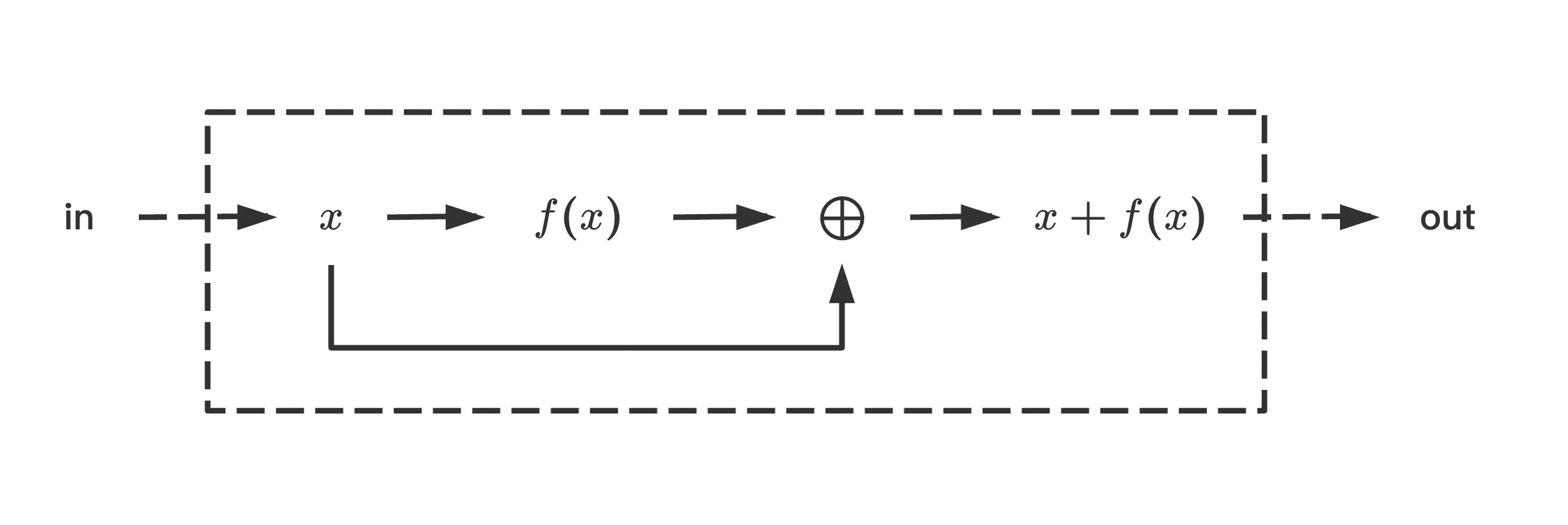
即, 输入\(x\)之函数空间通过加法\(x + f(x)\)扩大. 可以看到, 在前向计算过程中, 函数\(f(x)\)之作用类似于残差, 补充输入\(x\)对标准输出描述之不足; 同时, 在反向传播过程中, 对输入\(x\)之梯度计算分裂在不同影响链路上, 降低了函数\(f(x)\)对梯度的直接影响.
数据、模型与损失函数
数据生成策略如下,\[\left\{
\begin{align*}
x &= r + 2g + 3b \\
y &= r^2 + 2g^2 + 3b^2 \\
lv &= -3r - 4g - 5b
\end{align*}
\right.
\]Neural Network网络模型如下,
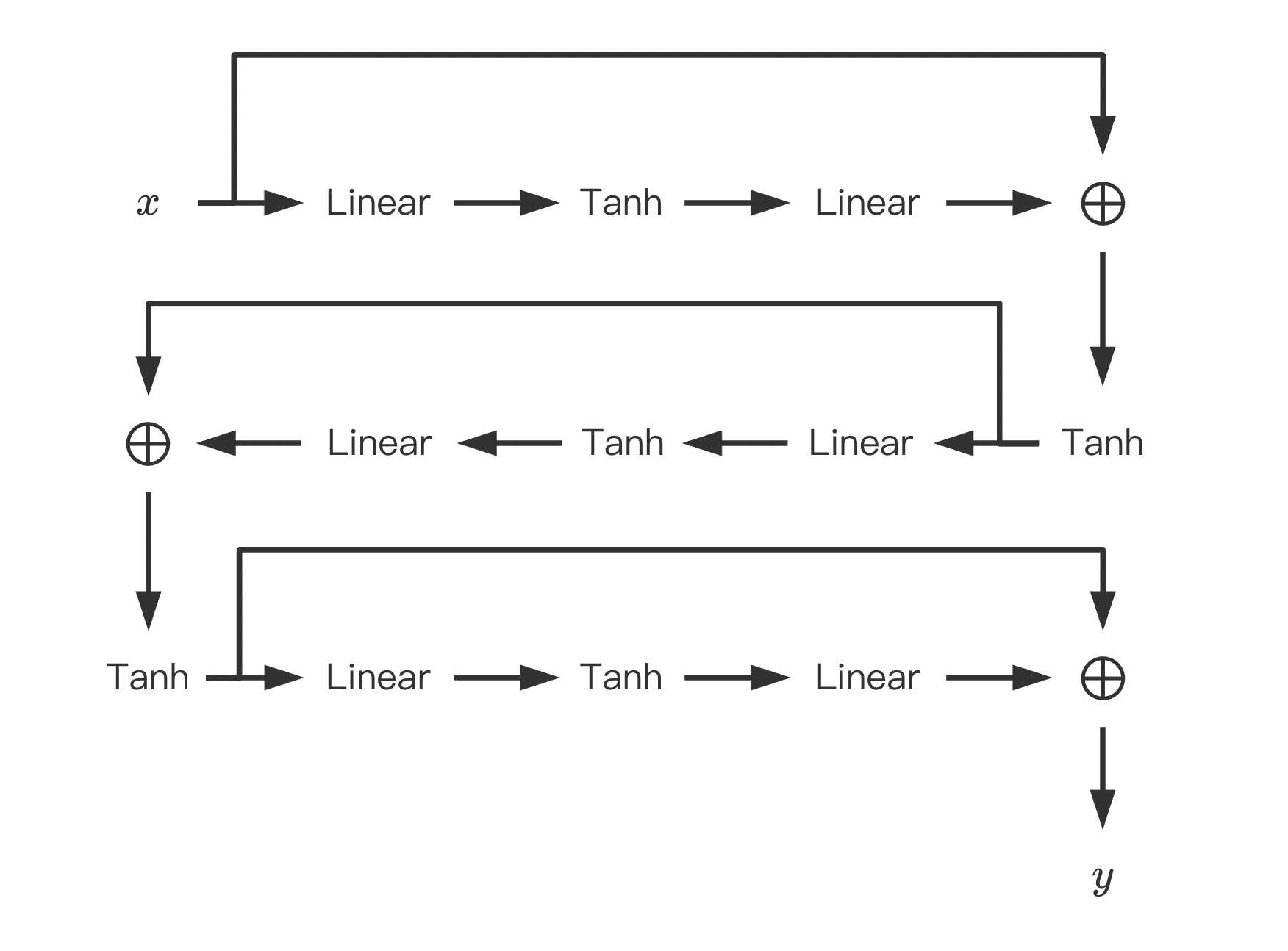
其中, 输入层\(x:=(r, g, b)\), 输出层\(y:=(x, y, lv)\), 中间所有隐藏层与输入之dimension保持一致.
损失函数如下,\[L = \sum_{i}\frac{1}{2}(\bar{x}^{(i)} - x^{(i)})^2 + \frac{1}{2}(\bar{y}^{(i)} - y^{(i)})^2 + \frac{1}{2}(\bar{lv}^{(i)} - lv^{(i)})^2
\]其中, \(i\)为data序号, \((\bar{x}, \bar{y}, \bar{lv})\)为相应观测值.
代码实现
本文以是否采用Residual Block为例(即在上述模型中是否去除\(\oplus\)), 观察Residual Block对模型复杂度的影响.code
import numpy
import torch
from torch import nn
from torch import optim
from torch.utils import data
from matplotlib import pyplot as plt numpy.random.seed(0) # 获取数据与封装数据
def xFunc(r, g, b):
x = r + 2 * g + 3 * b
return x def yFunc(r, g, b):
y = r ** 2 + 2 * g ** 2 + 3 * b ** 2
return y def lvFunc(r, g, b):
lv = -3 * r - 4 * g - 5 * b
return lv class GeneDataset(data.Dataset): def __init__(self, rRange=[-1, 1], gRange=[-1, 1], bRange=[-1, 1], \
num=100, transform=None, target_transform=None):
self.__rRange = rRange
self.__gRange = gRange
self.__bRange = bRange
self.__num = num
self.__transform = transform
self.__target_transform = target_transform self.__X = self.__build_X()
self.__Y_ = self.__build_Y_() def __build_Y_(self):
rArr = self.__X[:, 0:1]
gArr = self.__X[:, 1:2]
bArr = self.__X[:, 2:3]
xArr = xFunc(rArr, gArr, bArr)
yArr = yFunc(rArr, gArr, bArr)
lvArr = lvFunc(rArr, gArr, bArr)
Y_ = numpy.hstack((xArr, yArr, lvArr))
return Y_ def __build_X(self):
rArr = numpy.random.uniform(*self.__rRange, (self.__num, 1))
gArr = numpy.random.uniform(*self.__gRange, (self.__num, 1))
bArr = numpy.random.uniform(*self.__bRange, (self.__num, 1))
X = numpy.hstack((rArr, gArr, bArr))
return X def __len__(self):
return self.__num def __getitem__(self, idx):
x = self.__X[idx]
y_ = self.__Y_[idx]
if self.__transform:
x = self.__transform(x)
if self.__target_transform:
y_ = self.__target_transform(y_)
return x, y_ # 构建模型
class Model(nn.Module): def __init__(self, is_residual_block=True):
super(Model, self).__init__()
torch.random.manual_seed(0) self.__is_residual_block = is_residual_block
self.__in_features = 3
self.__out_features = 3 self.lin11 = nn.Linear(3, 3, dtype=torch.float64)
self.lin12 = nn.Linear(3, 3, dtype=torch.float64)
self.lin21 = nn.Linear(3, 3, dtype=torch.float64)
self.lin22 = nn.Linear(3, 3, dtype=torch.float64)
self.lin31 = nn.Linear(3, 3, dtype=torch.float64)
self.lin32 = nn.Linear(3, 3, dtype=torch.float64) def forward(self, X):
X1 = self.lin12(torch.tanh(self.lin11(X)))
if self.__is_residual_block:
X1 += X
X1 = torch.tanh(X1) X2 = self.lin22(torch.tanh(self.lin21(X1)))
if self.__is_residual_block:
X2 += X1
X2 = torch.tanh(X2) X3 = self.lin32(torch.tanh(self.lin31(X2)))
if self.__is_residual_block:
X3 += X2
return X3 # 构建损失函数
class MSE(nn.Module): def forward(self, Y, Y_):
loss = torch.sum((Y - Y_) ** 2)
return loss # 训练单元与测试单元
def train_epoch(trainLoader, model, loss_fn, optimizer):
model.train(True) loss = 0
with torch.enable_grad():
for X, Y_ in trainLoader:
optimizer.zero_grad() Y = model(X)
lossVal = loss_fn(Y, Y_)
lossVal.backward()
optimizer.step() loss += lossVal.item() loss /= len(trainLoader.dataset)
return loss def test_epoch(testLoader, model, loss_fn, optimzier):
model.train(False) loss = 0
with torch.no_grad():
for X, Y_ in testLoader:
Y = model(X)
lossVal = loss_fn(Y, Y_)
loss += lossVal.item()
loss /= len(testLoader.dataset)
return loss def train_model(trainLoader, testLoader, epochs=100):
model_RB = Model(True)
loss_RB = MSE()
optimizer_RB = optim.Adam(model_RB.parameters(), 0.001) model_No = Model(False)
loss_No = MSE()
optimizer_No = optim.Adam(model_No.parameters(), 0.001) trainLoss_RBList = list()
testLoss_RBList = list()
trainLoss_NoList = list()
testLoss_NoList = list()
for epoch in range(epochs):
trainLoss_RB = train_epoch(trainLoader, model_RB, loss_RB, optimizer_RB)
testLoss_RB = test_epoch(testLoader, model_RB, loss_RB, optimizer_RB)
trainLoss_No = train_epoch(trainLoader, model_No, loss_No, optimizer_No)
testLoss_No = test_epoch(testLoader, model_No, loss_No, optimizer_No) trainLoss_RBList.append(trainLoss_RB)
testLoss_RBList.append(testLoss_RB)
trainLoss_NoList.append(trainLoss_No)
testLoss_NoList.append(testLoss_No)
if epoch % 50 == 0:
print(epoch, trainLoss_RB, trainLoss_No, testLoss_RB, testLoss_No) fig = plt.figure(figsize=(5, 4))
ax1 = fig.add_subplot(1, 1, 1)
X = numpy.arange(1, epochs+1)
ax1.plot(X, trainLoss_RBList, "r-", lw=1, label="train with RB")
ax1.plot(X, testLoss_RBList, "r--", lw=1, label="test with RB")
ax1.plot(X, trainLoss_NoList, "b-", lw=1, label="train without RB")
ax1.plot(X, testLoss_NoList, "b--", lw=1, label="test without RB")
ax1.set(xlabel="epoch", ylabel="loss", yscale="log")
ax1.legend()
fig.tight_layout()
fig.savefig("loss.png", dpi=300)
plt.show() if __name__ == "__main__":
trainData = GeneDataset([-1, 1], [-1, 1], [-1, 1], num=1000, \
transform=torch.tensor, target_transform=torch.tensor)
testData = GeneDataset([-1, 1], [-1, 1], [-1, 1], num=300, \
transform=torch.tensor, target_transform=torch.tensor)
trainLoader = data.DataLoader(trainData, batch_size=len(trainData), shuffle=False)
testLoader = data.DataLoader(testData, batch_size=len(testData), shuffle=False)
epochs = 10000
train_model(trainLoader, testLoader, epochs)
结果展示
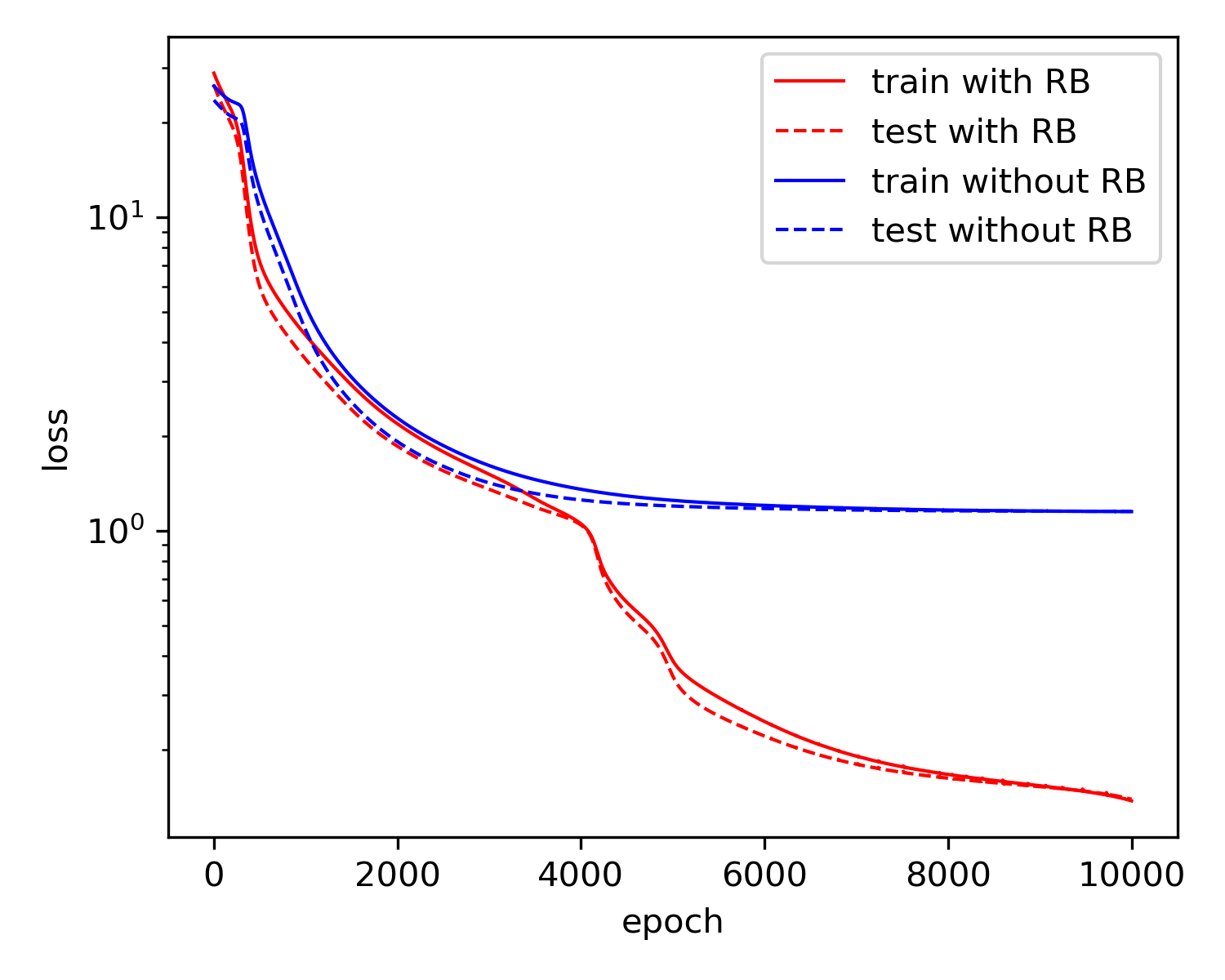
可以看到, 由于Residual Block结构引入额外的优化参数, 模型复杂度得以提升. 同时, 相较于常规Neural Network(对应去除Residual Block之\(\oplus\)), Residual Block之Neural Network在优化参数个数相同的前提下更加稳妥地扩大了函数空间.
使用建议
①. 残差函数之设计应当具备与目标输出匹配之能力;
②. 残差函数之设计可改变dimension, 此时\(\oplus\)侧之输入应当进行线性等维调整;
③. 若训练数据之复杂度高于测试数据, 则在训练起始, 训练数据之loss可能也要高于测试数据.参考文档
①. 动手学深度学习 - 李牧
Neural Network模型复杂度之Residual Block - Python实现的更多相关文章
- 论文翻译:2020_Nonlinear Residual Echo Suppression using a Recurrent Neural Network
论文地址:https://indico2.conference4me.psnc.pl/event/35/contributions/3367/attachments/779/817/Thu-1-10- ...
- Convolutional Neural Network-week2编程题2(Residual Networks)
1. Residual Networks(残差网络) 残差网络 就是为了解决深网络的难以训练的问题的. In this assignment, you will: Implement the basi ...
- 论文翻译:2020_WaveCRN: An efficient convolutional recurrent neural network for end-to-end speech enhancement
论文地址:用于端到端语音增强的卷积递归神经网络 论文代码:https://github.com/aleXiehta/WaveCRN 引用格式:Hsieh T A, Wang H M, Lu X, et ...
- 论文翻译:2020_FLGCNN: A novel fully convolutional neural network for end-to-end monaural speech enhancement with utterance-based objective functions
论文地址:FLGCNN:一种新颖的全卷积神经网络,用于基于话语的目标函数的端到端单耳语音增强 论文代码:https://github.com/LXP-Never/FLGCCRN(非官方复现) 引用格式 ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- 论文笔记之:Hybrid computing using a neural network with dynamic external memory
Hybrid computing using a neural network with dynamic external memory Nature 2016 原文链接:http://www.na ...
- machine learning 之 Neural Network 3
整理自Andrew Ng的machine learning课程week6. 目录: Advice for applying machine learning (Decide what to do ne ...
- 通过Visualizing Representations来理解Deep Learning、Neural network、以及输入样本自身的高维空间结构
catalogue . 引言 . Neural Networks Transform Space - 神经网络内部的空间结构 . Understand the data itself by visua ...
- Recurrent Neural Network[survey]
0.引言 我们发现传统的(如前向网络等)非循环的NN都是假设样本之间无依赖关系(至少时间和顺序上是无依赖关系),而许多学习任务却都涉及到处理序列数据,如image captioning,speech ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
随机推荐
- Windows 10 企业版 LSTC 激活秘钥及方法
Windows 10 企业版 LSTC 秘钥:M7XTQ-FN8P6-TTKYV-9D4CC-J462D 同时按下Win键+X,然后选择Windows PowerShell(管理员)按顺序输入下面的字 ...
- UBUNTU切换内核
查询可更换内核的序号 gedit /boot/grub/grub.cfg查询已安装的内核和内核的序号.找到文件中的menuentry (图中在一大堆fi-else底下)menuentry底下还有 ...
- SQL 实现全字段分组,每组取一条记录,记录满足:组内时间最大,组内不同类型数量求和
1 SELECT 2 TT.CLASS_ID AS "classId", 3 TT.TEMPLATE_ID AS "templateId" , 4 TT.MSG ...
- Training Spiking Neural Networks with Local Tandem Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 36th Conference on Neural Information Processing Systems (NeurIPS 202 ...
- Android实现仿微信实时语音对讲功能|与女友游戏开黑
与亲朋好友一起玩在线游戏,如果游戏中有实时语音对讲能力就可以拉进玩家之间的距离,添加更多乐趣.我们以经典的中国象棋为例,开发在线语音对讲象棋.本文主要涉及如下几个点: 在线游戏的规则,本文以中国象棋为 ...
- Iceberg 数据治理及查询加速实践
数据治理 Flink 实时写入 Iceberg 带来的问题 在实时数据源源不断经过 Flink 写入的 Iceberg 的过程中,Flink 通过定时的 Checkpoint 提交 snapshot ...
- Python连接hadoop-hive连接方法
import impala.dbapi as ipdbconn = ipdb.connect(host='IP', port= 端口, database='数据库名', auth_mechanism= ...
- 自定义顺序表ArrayList
1.简介 顺序表是在计算机内存中以数组的形式保存的线性表,线性表的顺序存储是指用一组地址连续的存储单元依次存储线性表中的各个元素.使得线性表中在逻辑结构上相邻的数据元素存储在相邻的物理存储单元中,即通 ...
- 需要登陆,请求数据 session
requests中的session模块思路:# 1. 登录 --> 等到cookie# 2.带着cookie 请求到书架的url-->书架上的内容#注意:# 两个操作要连续起来操作# 我们 ...
- 一文总结Vue
一.创建项目 1.安装Node.js 查看node版本 node-v 查看npm版本 npm-v 2.安装vue-cli脚手架 安装 npm install -g @vue/cli 创建项目 vue ...