Java语言在Spark3.2.4集群中使用Spark MLlib库完成朴素贝叶斯分类器
一、贝叶斯定理
贝叶斯定理是关于随机事件A和B的条件概率,生活中,我们可能很容易知道P(A|B),但是我需要求解P(B|A),学习了贝叶斯定理,就可以解决这类问题,计算公式如下:
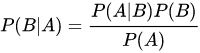
- P(A)是A的先验概率
- P(B)是B的先验概率
- P(A|B)是A的后验概率(已经知道B发生过了)
- P(B|A)是B的后验概率(已经知道A发生过了)
二、朴素贝叶斯分类
朴素贝叶斯的思想是,对于给出的待分类项,求解在此项出现的条件下,各个类别出现的概率,哪个最大,那么就是那个分类。
是一个待分类的数据,有m个特征
是类别,计算每个类别出现的先验概率
- 在各个类别下,每个特征属性的条件概率计算
- 计算每个分类器的概率
- 概率最大的分类器就是样本
的分类
三、java样例代码开发步骤
首先,需要在pom.xml文件中添加以下依赖项:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>3.2.0</version>
</dependency>
然后,在Java代码中,可以执行以下步骤来实现朴素贝叶斯算法:
1、创建一个SparkSession对象,如下所示:
import org.apache.spark.sql.SparkSession; SparkSession spark = SparkSession.builder()
.appName("NaiveBayesExample")
.master("local[*]")
.getOrCreate();
2、加载训练数据和测试数据:
import org.apache.spark.ml.feature.LabeledPoint;
import org.apache.spark.ml.linalg.Vectors;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.types.DataTypes;
import static org.apache.spark.sql.functions.*; //读取训练数据
Dataset<Row> trainingData = spark.read()
.option("header", true)
.option("inferSchema", true)
.csv("path/to/training_data.csv"); //将训练数据转换为LabeledPoint格式
Dataset<LabeledPoint> trainingLP = trainingData
.select(col("label"), col("features"))
.map(row -> new LabeledPoint(
row.getDouble(0),
Vectors.dense((double[])row.get(1))),
Encoders.bean(LabeledPoint.class)); //读取测试数据
Dataset<Row> testData = spark.read()
.option("header", true)
.option("inferSchema", true)
.csv("path/to/test_data.csv"); //将测试数据转换为LabeledPoint格式
Dataset<LabeledPoint> testLP = testData
.select(col("label"), col("features"))
.map(row -> new LabeledPoint(
row.getDouble(0),
Vectors.dense((double[])row.get(1))),
Encoders.bean(LabeledPoint.class));
请确保训练数据和测试数据均包含"label"和"features"两列,其中"label"是标签列,"features"是特征列。
import org.apache.spark.ml.classification.NaiveBayes;
import org.apache.spark.ml.classification.NaiveBayesModel; NaiveBayes nb = new NaiveBayes()
.setSmoothing(1.0) //设置平滑参数
.setModelType("multinomial"); //设置模型类型 NaiveBayesModel model = nb.fit(trainingLP); //拟合模型
在这里,我们创建了一个NaiveBayes对象,并设置了平滑参数和模型类型。然后,我们使用fit()方法将模型拟合到训练数据上。
Dataset<Row> predictions = model.transform(testLP); //查看前10条预测结果
predictions.show(10);
在这里,我们使用transform()方法对测试数据进行预测,并将结果存储在一个DataFrame中。可以通过调用show()方法查看前10条预测结果。
5、关闭SparkSession:
spark.close();
以下是完整代码的示例。请注意,需要替换数据文件的路径以匹配您的实际文件路径:
import org.apache.spark.ml.classification.NaiveBayes;
import org.apache.spark.ml.classification.NaiveBayesModel;
import org.apache.spark.ml.feature.LabeledPoint;
import org.apache.spark.ml.linalg.Vectors;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Encoders;
import static org.apache.spark.sql.functions.*; public class NaiveBayesExample { public static void main(String[] args) {
//创建SparkSession对象
SparkSession spark = SparkSession.builder()
.appName("NaiveBayesExample")
.master("local[*]")
.getOrCreate(); try{
//读取很抱歉,我刚才的回答被意外截断了。以下是完整的Java代码示例: ```java
import org.apache.spark.ml.classification.NaiveBayes;
import org.apache.spark.ml.classification.NaiveBayesModel;
import org.apache.spark.ml.feature.LabeledPoint;
import org.apache.spark.ml.linalg.Vectors;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Encoders;
import static org.apache.spark.sql.functions.*; public class NaiveBayesExample { public static void main(String[] args) {
//创建SparkSession对象
SparkSession spark = SparkSession.builder()
.appName("NaiveBayesExample")
.master("local[*]")
.getOrCreate(); try{
//读取训练数据
Dataset<Row> trainingData = spark.read()
.option("header", true)
.option("inferSchema", true)
.csv("path/to/training_data.csv"); //将训练数据转换为LabeledPoint格式
Dataset<LabeledPoint> trainingLP = trainingData
.select(col("label"), col("features"))
.map(row -> new LabeledPoint(
row.getDouble(0),
Vectors.dense((double[])row.get(1))),
Encoders.bean(LabeledPoint.class)); //读取测试数据
Dataset<Row> testData = spark.read()
.option("header", true)
.option("inferSchema", true)
.csv("path/to/test_data.csv"); //将测试数据转换为LabeledPoint格式
Dataset<LabeledPoint> testLP = testData
.select(col("label"), col("features"))
.map(row -> new LabeledPoint(
row.getDouble(0),
Vectors.dense((double[])row.get(1))),
Encoders.bean(LabeledPoint.class)); //创建朴素贝叶斯分类器
NaiveBayes nb = new NaiveBayes()
.setSmoothing(1.0)
.setModelType("multinomial"); //拟合模型
NaiveBayesModel model = nb.fit(trainingLP); //进行预测
Dataset<Row> predictions = model.transform(testLP); //查看前10条预测结果
predictions.show(10); } finally {
//关闭SparkSession
spark.close();
}
}
}
请注意替换代码中的数据文件路径,以匹配实际路径。另外,如果在集群上运行此代码,则需要更改master地址以指向正确的集群地址。
Java语言在Spark3.2.4集群中使用Spark MLlib库完成朴素贝叶斯分类器的更多相关文章
- solr java api 使用solrj操作zookeeper集群中的solrCloud中的数据
1 导入相关的pom依赖 <dependencies> <dependency> <groupId>org.apache.solr</groupId> ...
- Cloudera集群中提交Spark任务出现java.lang.NoSuchMethodError: org.apache.hadoop.hbase.HTableDescriptor.addFamily错误解决
Cloudera及相关的组件版本 Cloudera: 5.7.0 Hbase: 1.20 Hadoop: 2.6.0 ZooKeeper: 3.4.5 就算是引用了相应的组件依赖,依然是报一样的错误! ...
- Java实现基于朴素贝叶斯的情感词分析
朴素贝叶斯(Naive Bayesian)是一种基于贝叶斯定理和特征条件独立假设的分类方法,它是基于概率论的一种有监督学习方法,被广泛应用于自然语言处理,并在机器学习领域中占据了非常重要的地位.在之前 ...
- 朴素贝叶斯算法分析及java 实现
1. 先引入一个简单的例子 出处:http://www.ruanyifeng.com/blog/2013/12/naive_bayes_classifier.html 一.病人分类的例子 让我从一个例 ...
- 【机器学习与R语言】3-概率学习朴素贝叶斯(NB)
目录 1.理解朴素贝叶斯 1)基本概念 2)朴素贝叶斯算法 2.朴素贝斯分类应用 1)收集数据 2)探索和准备数据 3)训练模型 4)评估模型性能 5)提升模型性能 1.理解朴素贝叶斯 1)基本概念 ...
- 利用朴素贝叶斯算法进行分类-Java代码实现
http://www.crocro.cn/post/286.html 利用朴素贝叶斯算法进行分类-Java代码实现 鳄鱼 3个月前 (12-14) 分类:机器学习 阅读(44) 评论(0) ...
- Hadoop(八)Java程序访问HDFS集群中数据块与查看文件系统
前言 我们知道HDFS集群中,所有的文件都是存放在DN的数据块中的.那我们该怎么去查看数据块的相关属性的呢?这就是我今天分享的内容了 一.HDFS中数据块概述 1.1.HDFS集群中数据块存放位置 我 ...
- Java --本地提交MapReduce作业至集群☞实现 Word Count
还是那句话,看别人写的的总是觉得心累,代码一贴,一打包,扔到Hadoop上跑一遍就完事了????写个测试样例程序(MapReduce中的Hello World)还要这么麻烦!!!?,还本地打Jar包, ...
- Storm官方文档翻译之在生产环境集群中运行Topology
在进群生产环境下运行Topology和在本地模式下运行非常相似.下面是步骤: 1.定义Topology(如果使用Java开发语言,则使用TopologyBuilder来创建) 2.使用StormSub ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
随机推荐
- 面向对象ooDay6
精华笔记: static final常量:应用率高 必须声明同时初始化 由类名打点来访问,不能被改变 建议:常量所有字母都大写,多个单词用_分隔 编译器在编译时会将常量直接替换为具体的数,效率高 何时 ...
- django_应用及分布式路由
一.应用的定义 1.应用在Django中是一个独立的业务模块,可以包含自己的路由.视图.模板.模型. 例如如下图所示,一个资讯类网站中会有不同的模块,如果所有的模块共用一个views.py文件,则会导 ...
- idea中新建java类
project是项目,一个大目录,里面可以放多个module project里面存放: .idea文件(project相当于workplace) module(模块) out(编译生成的.class文 ...
- JQUERY选择器大全(转载)
在Web应用程序中,大部分的客户端操作都是基于对象的操作,要操作对象就必须先获取对象,jQuery提供了强大的选择器让我们获取对象.我人为地将jQuery选择器分为两大部分:选择对象和筛选条件.选择对 ...
- Hadoop之HDFS优缺点、设计原理、框架
如需大数据开发整套视频(hadoop\hive\hbase\flume\sqoop\kafka\zookeeper\presto\spark):请联系QQ:1974983704 Hadoop的前世今 ...
- Python之路径处理
路径处理,需导入 os包 1 import os # 导入 os 包 2 3 """获取运行脚本文件夹的路径""" 4 current_di ...
- input_subsys 输入子系统框架分析
在linux内核中 已做好各类驱动的框架,驱动程序也属于内核的一部分,我们可以在原有的驱动上修改,来匹配我们自已的硬件,也可以自已编写符合内核驱动框架的驱动程序.出于学习的目的,便于更好的理解各类驱动 ...
- finereport连接mysql8.0
1.java包更新 2.下载地址:https://dev.mysql.com/downloads/connector/j/ 3.替换文件为8.0删除5.1版本 4.驱动器手动输入com.mysql.c ...
- Winform 应用DotnetBar
Winform 使用NotNetBar namespace WindowsFormExample { public partial class FrmMain : Office2007Form { p ...
- 漫谈Python魔术方法,见过的没见过的都在这里了
漫谈Python魔术方法,见过的没见过的都在这里了 就说一下,不深入 假的一览 提到魔术方法,学过python都应该知道一些.至少你得会__init__吧. 在我之前写的博文中有很多都涉及魔术方法.比 ...