Mysql性能优化专栏
1. 最大数据量
Mysql没有对单表的数据量大小做限制,单表的大小取决于操作系统对文件大小的限制。
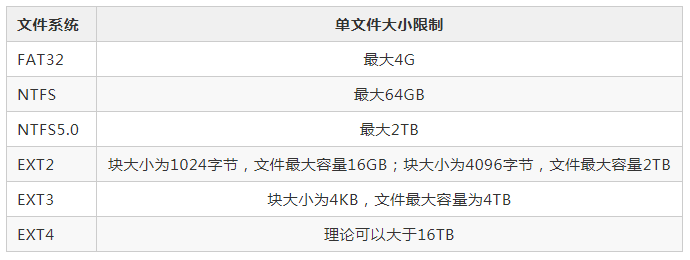
《阿里巴巴Java开发手册》中建议当单表的数据量大小超过500万行或者大于2GB时需要分库分表。
2. 最大连接数
Mysql的最大连接数由 max_connections 和 max_user_connections 两个参数决定。
max_connections 表示Mysql实例的最大连接数,上限为16384。max_user_connections表示每个用户的最大连接数,0则表示无限制。
查询最大连接数设置:
1 show variables like '%max_connections%';
2 show variables like '%max_user_connections%';
Mysql为每个连接提供缓冲池,过多的连接意味着消耗更过的内存,因此一般设置两者的比值超过10%,计算公式为:max_user_connections / max_connections * 100%
设置最大连接数:
- 临时设置,重启后失效
1 set global max_connections = 1000;
2 set global max_user_connections = 100;
- 配置文件设置,永久有效
max_connections=200
max_user_connections=20
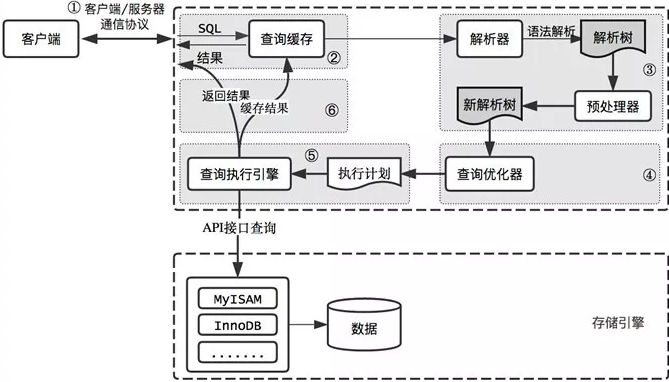
3. Mysql查询过程
4. 查询耗时
建议单次查询耗时控制在0.5秒之内,源于用户体验3秒原则。
响应时间 = 客户端UI渲染耗时 + 网络请求耗时 + 应用程序处理耗时 + 查询数据库耗时。
5. 实施原则
- 合理使用索引,滥用索引会消耗磁盘空间和CPU
- 不推荐使用函数格式化数据,而交给应用程序处理
- 不推荐使用外键约束,而在应用程序中保持数据的准确性
- 写多读少时,避免使用唯一索引,而使用应用程序保持数据唯一性
- 避免冗余字段,建立中间表,空间换时间
- 避免使用极度消耗事务,而应由应用程序分割出尽可能小的事务
- 对重点表提前预知,提前优化
6. 数据库表设计
- 如果长度允许,尽量使用tinyint(1字节)、smallint(2字节)、mediumint(3字节)而非int(4字节)、bigint(8字节)
- 如果长度固定,则使用char类型,而非varchar
- 如果varchar足够,则不使用text
- 精度较高则是由decimal,或者使用bigint类型,存实际数值*小数点后位数*10,例如小数点后两位5.67则存567
- 使用timestamp(4字节)而非datatime(8字节),以UTC的格式储存自动转换时区
- text类型字段存储大量数据,表容量也随之增大,建议使用子表存储,业务数据关联
7. 数据库引擎
InnoDB:两个文件,一个存结构,一个存索引和数据等信息
- 使用B+树存储表数据索引文件
- B+树的叶子结点存储表的所有数据
- 推荐使用数值自增主键
- 非主键索引的叶子结点存储的是主键(一致性和节约空间)
- MyISAM:三个文件,一个存结构,一个存索引及数据磁盘地址,一个存数据
8. 优化维度
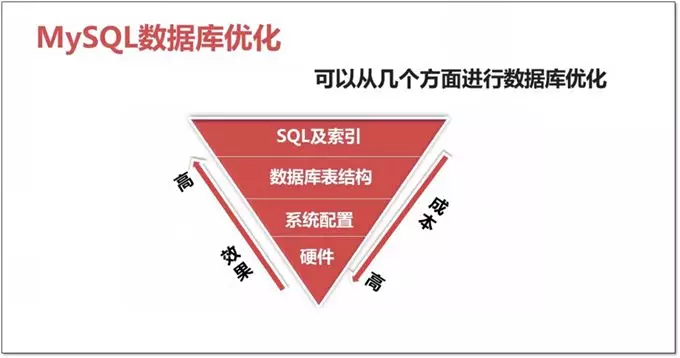
优化选择:
- 优化成本:硬件 > 系统配置 > 数据库表结构 > SQL及索引
- 优化效果:硬件 < 系统配置 < 数据库表结构 < SQL及索引
9. 索引
从存储结构上来划分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引。
从应用层次来分:普通索引,唯一索引,复合索引。
根据中数据的物理顺序与键值的逻辑(索引)顺序关系:聚集索引,非聚集索引。
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:即一个索引包含多个列
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。
非聚簇索引:不是聚簇索引,就是非聚簇索引。
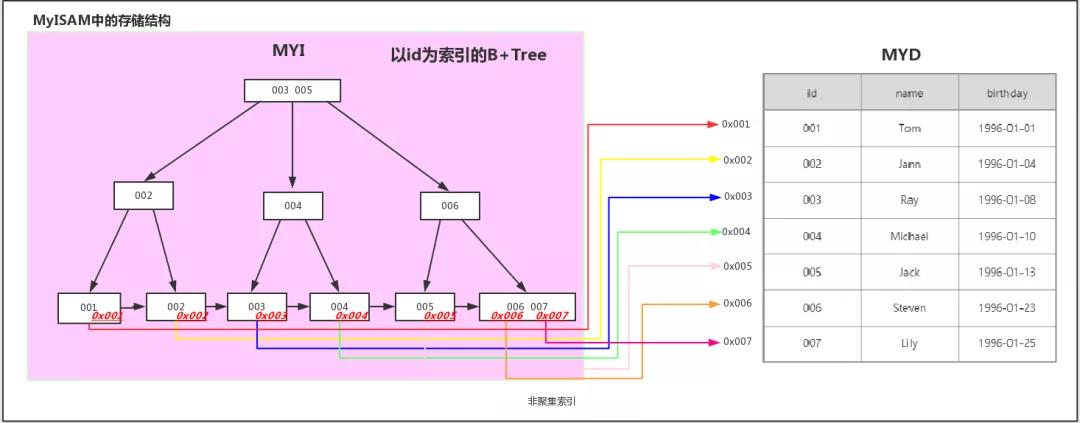
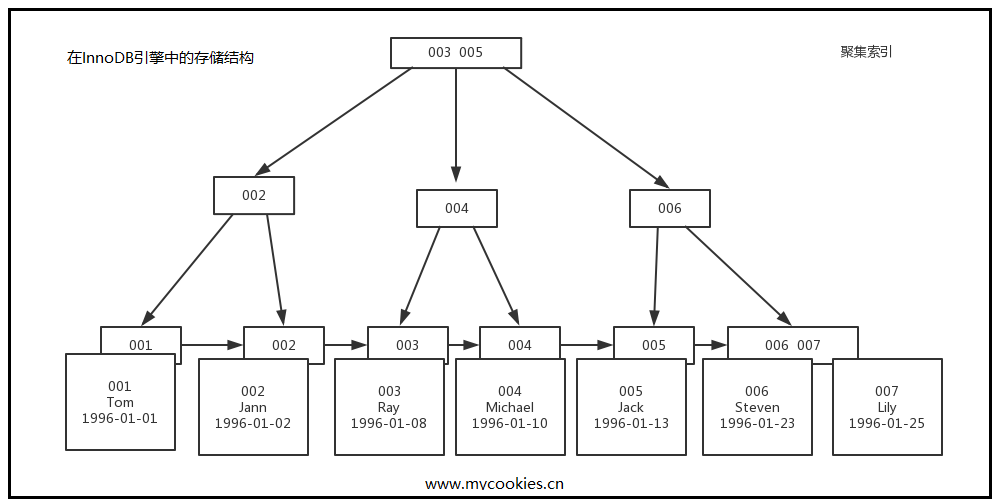
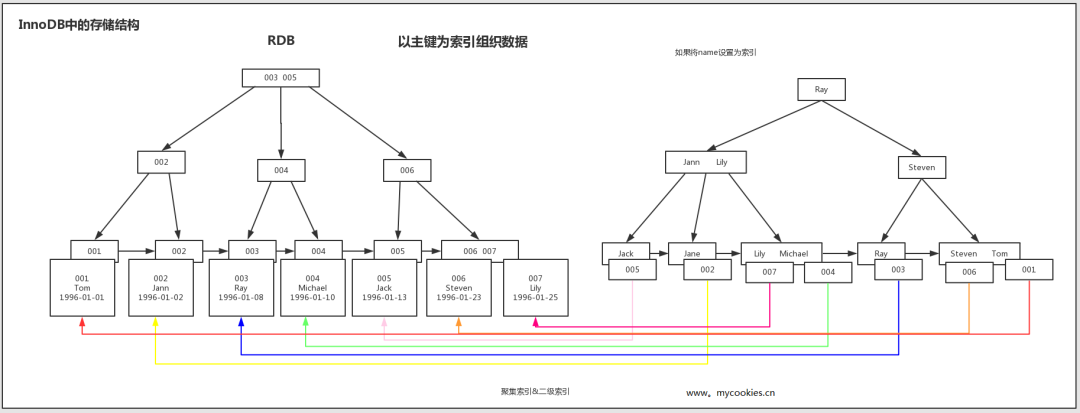
MyISAM引擎以主键作为索引时叶子节点存储的是数据的地址。InnoDB引擎以主键作为索引时叶子节点存储的是数据信息,非主键索引叶子节点存储的是主键,再通过主键查询数据。
建议使用自增主键作为索引。
10. Mysql索引失效
可以使用explain命令加在要分析的sql语句前面,在执行结果中查看key这一列的值,如果为NULL,说明没有使用索引。
- like 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效
- or语句前后没有同时使用索引。当or左右查询字段只有一个是索引,该索引
- 失效,只有当or左右查询字段均为索引时,才会生效
- 组合索引,不是使用第一列索引,索引失效
- 数据类型出现隐式转换。如varchar不加单引号的话可能会自动转换为int型,使索引无效,产生全表扫描
- 在索引列上使用 IS NULL 或 IS NOT NULL操作。索引是不索引空值的,所以这样的操作不能使用索引,可以用其他的办法处理,例如:数字类型,判断大于0,字符串类型设置一个默认值,判断是否等于默认值即可
- 在索引字段上使用not,<>,!=。不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。 优化方法: key<>0 改为 key>0 or key<0对索引字段进行计算操作,字段上使用函数
- 当全表扫描速度比索引速度快时,mysql会使用全表扫描,此时索引失效
11. Mysql索引总结
- 问:为什么索引结构默认使用B-Tree,而不是hash,二叉树,红黑树?
hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
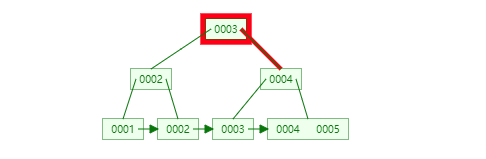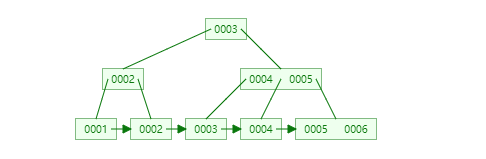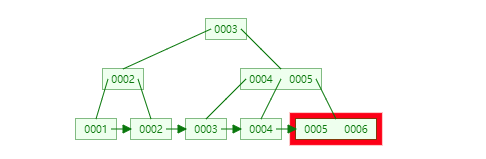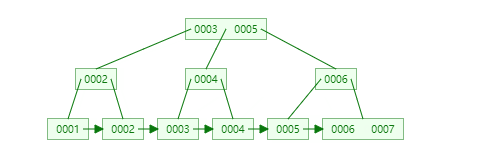
- 问:为什么官方建议使用自增长主键作为索引?
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
插入连续的数据:
插入非连续的数据:

12. SQL优化
- 分批处理
若批量更新整个表的状态,会导致当前事务阻塞,建议分小批次更新。
- 不等于优化
不等于会使索引失效,建议使用union all。例如:查询商品表不等于100元的商品,则查询商品 [0, 100) 并 (100, +∞]的价格。
- or优化
or会是组合索引优化,因此使用union。例如:查询人员表org_code为123456且login_code为zhangsan的信息,则查询org_code为123456 并 login_code为zhangsan的信息,前提是org_code和login_code都建立了索引。
- in优化
in适合主表大子表小,exist适合主表小子表大。由于查询优化器的不断升级,很多场景这两者性能差已经不明显了。
将in改为join语句。
- join优化
join的实现是采用Nested Loop Join算法,就是通过驱动表的结果集作为基础数据,通过该结数据作为过滤条件到下一个表中循环查询数据,然后合并结果。如果有多个join,则将前面的结果集作为循环数据,再次到后一个表中查询数据。
a. 驱动表和被驱动表尽可能的增加查询条件,能使用on则不使用where,小结果集驱动大结果集
b. 尽量给驱动表的join字段加上索引
c. 如果需要join三个以上的表,建议冗余字段
- limit优化
尽量使用分页查询,限制返回数据量大小。
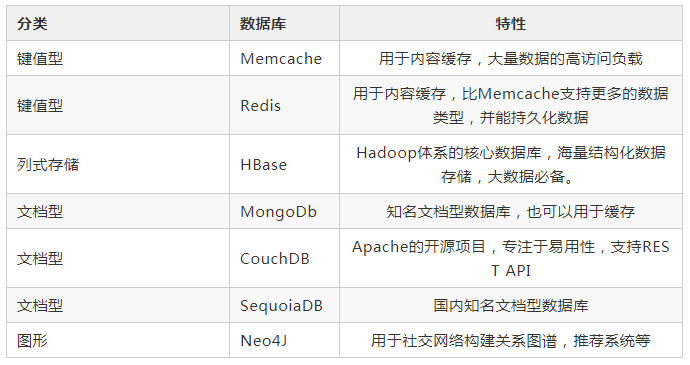
13. 其他数据库
Mysql性能优化专栏的更多相关文章
- Mysql性能优化:为什么你的count(*)这么慢?
导读 在开发中一定会用到统计一张表的行数,比如一个交易系统,老板会让你每天生成一个报表,这些统计信息少不了 sql 中的count函数. 但是随着记录越来越多,查询的速度会越来越慢,为什么会这样呢?M ...
- Mysql - 性能优化之子查询
记得在做项目的时候, 听到过一句话, 尽量不要使用子查询, 那么这一篇就来看一下, 这句话是否是正确的. 那在这之前, 需要介绍一些概念性东西和mysql对语句的大致处理. 当Mysql Server ...
- Mysql性能优化三(分表、增量备份、还原)
接上篇Mysql性能优化二 对表进行水平划分 如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了.如果我拆成100个表,那么每个表只有10万条记录.当然这需要数据在逻 ...
- [MySQL性能优化系列]提高缓存命中率
1. 背景 通常情况下,能用一条sql语句完成的查询,我们尽量不用多次查询完成.因为,查询次数越多,通信开销越大.但是,分多次查询,有可能提高缓存命中率.到底使用一个复合查询还是多个独立查询,需要根据 ...
- [MySQL性能优化系列]巧用索引
1. 普通青年的索引使用方式 假设我们有一个用户表 tb_user,内容如下: name age sex jack 22 男 rose 21 女 tom 20 男 ... ... ... 执行SQL语 ...
- MySQL性能优化:索引
MySQL性能优化:索引 索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序.数据库使用索引以找到特定值,然后顺指针找到包含该值的行.这样可以使对应于表的SQL语句执 ...
- mysql 性能优化方向
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- MySQL性能优化总结
一.MySQL的主要适用场景 1.Web网站系统 2.日志记录系统 3.数据仓库系统 4.嵌入式系统 二.MySQL架构图: 三.MySQL存储引擎概述 1)MyISAM存储引擎 MyISAM存储引擎 ...
- MYSQL性能优化的最佳20+条经验
MYSQL性能优化的最佳20+条经验 2009年11月27日 陈皓 评论 148 条评论 131,702 人阅读 今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显.关于数 ...
随机推荐
- elementui checkbox复选框实现层级联动
使用elementui 实现复选框的层级联动,可能我的表述不准确,先上一个效果图. 实际开发中可能遇到这样的场景,当选择高一层级的复选框时它包含的低级的复选框就不需要再勾选,需要默认选中并且禁止选用. ...
- Java并发编程 - Runnbale、Future、Callable 你不知道的那点事(二)
Java并发编程 - Runnbale.Future.Callable 你不知道的那点事(一)大致说明了一下 Runnable.Future.Callable 接口之间的关系,也说明了一些内部常用的方 ...
- python中a+=b 和a=a+b的结果一样吗
这里涉及到可变类型和不可变类型. 可变类型:列表,字典,集合 不可变:数字,字符串,元祖 先看一下不可变类型的运算: +=运算 >>> a, b = 1, 2 >>> ...
- list scheduling algorithm 指令调度 —— 笔记
作者:Yaong 出处:https://www.cnblogs.com/yaongtime/articles/14033444.html 版权:本文版权归作者和博客园共有 转载:欢迎转载,但未经作者同 ...
- jQuery 第一章 $()选择器
jquery 是什么? jquery 其实就是一堆的js函数(js库),也是普通的js而已. 有点像我们封装一个函数,把他放到单独的js 文件,等待有需要的时候调用它. 那么使用它有啥好处呢? jqu ...
- PHP获取数组中重复值的键值
$array = array ( 0=>'a', 1=>'b', 2=>'a', 5=>'b', 6=>'c', 40=>'d' ); $keyarr =[];$r ...
- dubbo与zk
一.总体流程: 1.服务提供者启动时,会向注册中心写入自己的元数据信息,同时会订阅配置元数据信息: 2.消费者启动时,也会向注册中心写入自己的元数据信息,并订阅服务提供者.路由和配置元数据信息: 3. ...
- SpringBoot整合阿里短信服务
导读 由于最近手头上需要做个Message Gateway,涉及到:邮件(点我直达).短信.公众号(点我直达)等推送功能,网上学习下,整理下来以备以后使用. 步骤 点我直达 登录短信服务控制台 点我直 ...
- 06_Intent和IntentFilter
Intent是同一个或不同的应用中的组件之间的消息传递的媒介,是一个将要执行动作的抽象描述,一般来说是作为参数来使用. Intent描述要启动的基本组件: IntentFilter对组件进行过滤. 下 ...
- Boost随机库的简单使用:Boost.Random(STL通用)
文章目录 文章目录 文章内容介绍 Boost随机库的简单使用 生成一个随机的整数 生成一个区间的平均概率随机数 按概率生成一个区间的随机整数 一些经典的分布 与STL的对比 Ref 文章内容介绍 Bo ...