【DeepLearning】GoogLeNet
InceptionV1 论文原文:Going deeper with convolutions 中英文对照
InceptionBN 论文原文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 中英文对照
InceptionV2/V3 论文原文:Rethinking the Inception Architecture for Computer Vision 中英文对照
InceptionV4 论文原文: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learnin
本文介绍的是著名的网络结构GoogLeNet及其延伸版本,目的是试图领会其中的思想而不是单纯关注结构。本文大量参考该博客 和 GoogleNet详解,感谢。
Notes
- Inception V1
- Motivation
- Architectural details
- GoogLeNet
- Auxililary Classifier
- Conclusion
- Inception BN
- Motivation
- BN
- Architectural Details
- Conclusion
- Inception V2、V3
- Inception V4
## GoogLeNet Inception V1
【Motivation】
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,或者增加核的数量,但这也意味着巨量的参数。但这种方式存在着明显的问题:
(1)参数太多,如果训练数据集有限,很容易产生过拟合;
(2)网络越大、参数越多,计算复杂度越大,难以应用,尤其是W中含有大量0的情况下,造成资源的浪费;
(3)网络越深,容易出现梯度弥散问题,难以优化模型。(ReLU不解决梯度弥散的问题,只延缓)
解决这些问题的方法当然就是在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接甚至一般的卷积变成稀疏连接。但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是计算所消耗的时间却很难减少。这就代表着,我们要寻找一个方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能。因此,GoogLeNet团队提出了Inception网络结构,就是构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构。
【Architectural Details】
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构,下图为原始的Inception结构:
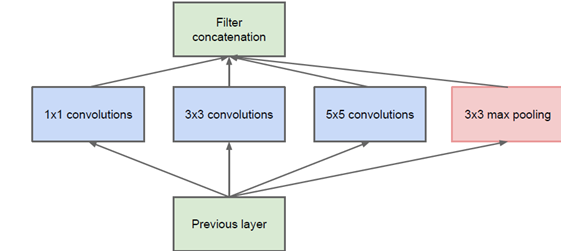
该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起,一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。具体来看,对Inception做如下的解释:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
但是,这种叠加不可避免的使得Inception 模块的输出通道数增加,这就增加了Inception 模块中每个卷积的计算量。因此在经过若干个模块之后,计算量会爆炸性增长。为此采用1×1卷积核来进行降维,改进后的Inception Module如下:
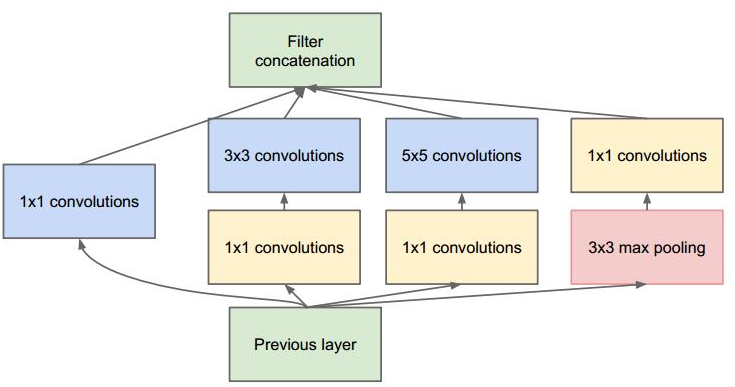
值得注意的是:
1x1卷积是在最大池化层之后,而不是之前。这是因为:池化层是为了提取图像的原始特征,一旦它接在1x1卷积之后就失去了最初的本意。1x1卷积在3x3、5x5卷积之前。这是因为:如果1x1卷积在它们之后,则3x3卷积、5x5卷积的输入通道数太大,导致计算量仍然巨大。
为了方便理解它是如何有效的,我们举下述的例子:

【GoogLeNet】
在GoogLeNet中,借鉴了AlexNet和VGG的stack(repeat)策略,将Inception单元重复串联起来,构成基本的特征提取结构。
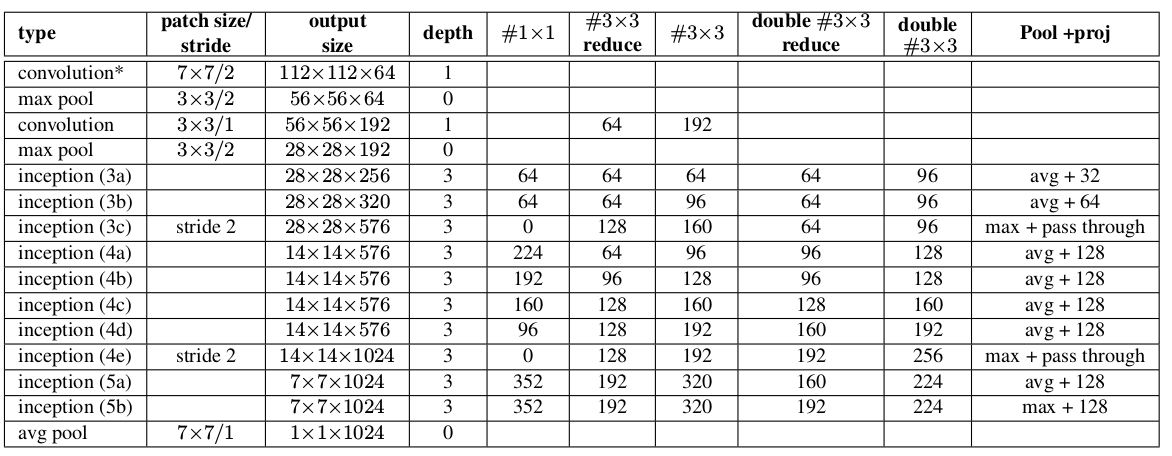
InceptionNet V1 是一个22层的深度网络。 如果考虑池化层,则有29层。如下图中的depth 列所示。
网络具有三组Inception 模块,分别为:inception(3a)/inception(3b)、inception(4a)/inception(4b)/inception(4c)/inception(4d)/inception(4e)、inception(5a)、inception(5b)。三组Inception 模块被池化层分隔。

对上图说明如下:
(1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了average pooling来代替全连接层,该想法来自NIN(Network in Network),事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ; (在avg pooling之后,FC之前)
(4)为了缓解梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器Auxililary Classifier)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号。
原始输入的图像为224×224×3,接下来的是对各层进行更细致的解释:

接下来就以第一层(卷积层)和第三层(Inception 3a层)为例进行详细的解释。


【Auxililary Classifier】
- 为了缓解梯度消失的问题,
InceptionNet V1给出了两个辅助分类器。这两个辅助分类器被添加到网络的中间层,它们和主分类器共享同一套训练数据及其标记。其中:- 第一个辅助分类器位于
Inception(4a)之后,Inception(4a)模块的输出作为它的输入。 - 第二个辅助分类器位于
Inception(4d)之后,Inception(4d)模块的输出作为它的输入。 - 两个辅助分类器的结构相同,包括以下组件:
- 一个尺寸为
5x5、步长为3的平均池化层。 - 一个尺寸为
1x1、输出通道数为128的卷积层。 - 一个具有
1024个单元的全连接层。 - 一个
drop rate = 70%的dropout层。 - 一个使用
softmax损失的线性层作为输出层。
- 一个尺寸为
- 第一个辅助分类器位于
- 在训练期间,两个辅助分类器的损失函数的权重是0.3,它们的损失被叠加到网络的整体损失上。在推断期间,这两个辅助网络被丢弃。
在
Inception v3的实验中表明:辅助网络的影响相对较小,只需要其中一个就能够取得同样的效果。事实上辅助分类器在训练早期并没有多少贡献。只有在训练接近结束,辅助分支网络开始发挥作用,获得超出无辅助分类器网络的结果。
- 两个辅助分类器的作用:提供正则化的同时,克服了梯度消失问题。
【Conclusion】
Inception v1 有 22 层,但只有 500w 的参数量,是 AlexNet 的 1/12。为什么要减少参数量?一是因为参数越多,需要喂给模型的数据量就越大,二是因为参数越多,耗费的计算资源就越大。
InceptionNet 为什么参数少而且效果好?一是因为用平均池化层代替了最后的全连接层,二是因为上面解释的 Inception Module 的作用。
## GoogleNet InceptionBN
关键点:优化策略:BN、用两个3x3代替一个5x5、LRN是不必要的。
【Motivation】
存在Internal Covariate Shift现象(协方差偏移,参考天雨粟)
- 当底层网络中参数发生微弱变化时,由于每一层中的线性变换与非线性激活映射,这些微弱变化随着网络层数的加深而被放大(类似蝴蝶效应);
- 参数的变化导致每一层的输入分布会发生改变,进而上层的网络需要不停地去适应这些分布变化,使得我们的模型训练变得困难。
- 较规范的定义:在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化的这一过程被称作Internal Covariate Shift。
Internal Covariate Shift的存在会使得 网络的学习速率降低、网络陷入梯度饱和区,网络收敛速率减缓。
解决办法:引入Batch Normalization,作为深度网络模型的一个层,每次先对input数据进行归一化,再送入神经网络输入层。
【Batch Normalization】
关于BN,论文看的我十分闹心,因为数学的底子太差,很多知识不熟悉。这里推荐莫烦的讲解视频,和这个博客来解释什么是BN,用一句话总结就是
批处理就是 对于每个隐层神经元,把 逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布 强制拉回到 均值为0方差为1的比较标准的正态分布 ,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。
- Batch normalization实现:转自 <深度学习优化策略-1>Batch Normalization(BN)
1、使网络某一层的输入样本做白化处理(最后发现等价于零均值化(Normalization)处理,拥有零均值,方差为1),输入样本之间不相关。通过零均值化每一层的输入,使每一层拥有服从相同分布的输入样本,因此克服内部协方差偏移的影响。
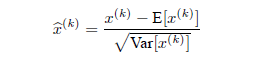
E(X)是输入样本X的期望,Var是输入样本X的方差。注意,对于一个d维的输入样本X=(x1,x2,....xd),要对某一层所有的维度一起进行零均值化处理,计算量大,且部分地方不可导,因此,这里的是针对每个维度k分别处理。
2、数据简化:输入样本X规模可能上亿,直接计算几乎是不可能的。因此,选择每个batch来进行Normalization,得出Batch Normalization(BN)的处理方式:

从上图可以看出,因为简单的对数据进行normalize处理会降低,把数据限制在[0,1]的范围内,对于型激活函数来说,只使用了其线性部分,会限制模型的表达能力。所以,还需要对normalize之后的进行变换:
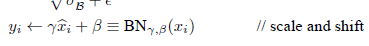
r和B做为参数,可以通过网络训练学到。
3、BN的参数求导:输入样本进行变换之后,要进行梯度反向传播,就必须计算BN各个参数的梯度,梯度计算公式如下:
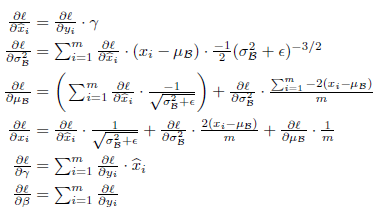
可见,通过BN对输入样本进行变换是可导的,不会对梯度反向传播造成影响。
4、为了加快训练,我们在模型训练阶段使用BN,但是在推理阶段并不一定要使用。训练一个BN网络完整的流程:

关于具体实现,可以参考机器不学习的专栏,实现的很具体
【Architectural details】
InceptionBN的主要贡献是提出了Batch Normalization。论文指出,使用了Batch Normalization之后:- BN 减少了内部协方差,提高了梯度在网络中的流动,加速了网络的训练。
- 减少梯度对参数大小或初始值的依赖,使网络在使用较大学习速率训练网络参数时,也不会出现参数发散的情况。
- 正则化模型,减少模型对dropout,careful weight initialnization依赖
- 网络具有更好的泛化能力。
InceptionBN网络训练的技巧有:- 使用更高的学习率。
- 删除
dropout层、LRN层。 - 减小
L2正则化的系数。 - 更快的衰减学习率。学习率以指数形式衰减。
- 更彻底的混洗训练样本,使得一组样本在不同的
epoch中处于不同的mini batch中。 - 减少图片的形变。
InceptionBN的网络结构比Inception v1有少量改动:5x5卷积被两个3x3卷积替代。这使得网络的最大深度增加了 9 层,同时网络参数数量增加 25%,计算量增加 30%。28x28的inception模块从2个增加到3个。- 在
inception模块中,有的采用最大池化,有的采用平均池化。 - 在
inception模块之间取消了用作连接的池化层。 inception(3c),inception(4e)的子层采用步长为 2 的卷积/池化。
Pool+proj列给出了inception中的池化操作。avg+32意义为:平均池化层后接一个尺寸1x1、输出通道32的卷积层。max+pass through意义为:最大池化层后接一个尺寸1x1、输出通道数等于输入通道数的卷积层。
【Conclusion】
总的来说,BN通过将每一层网络的输入进行normalization,保证输入分布的均值与方差固定在一定范围内,减少了网络中的Internal Covariate Shift问题,并在一定程度上缓解了梯度消失,加速了模型收敛;并且BN使得网络对参数、激活函数更加具有鲁棒性,降低了神经网络模型训练和调参的复杂度;最后BN训练过程中由于使用mini-batch的mean/variance作为总体样本统计量估计,引入了随机噪声,在一定程度上对模型起到了正则化的效果。
【DeepLearning】GoogLeNet的更多相关文章
- 【DeepLearning】用于几何匹配的卷积神经网络体系结构
[论文标题]Convolutional neural network architecture for geometric matching (2017CVPR) [论文作者]Ignacio Rocc ...
- 【DeepLearning】LeNet-5
手写字体识别模型LeNet5诞生于1994年,是最早的卷积神经网络之一.原文地址为Gradient-Based Learning Applied to Document Recognition,感谢网 ...
- 【DeepLearning】基本概念:卷积、池化、Backpropagation
终于有了2个月的空闲时间,给自己消化沉淀,希望别有太多的杂事打扰.在很多课程中,我都学过卷积.池化.dropout等基本内容,但目前在脑海中还都是零散的概念,缺乏整体性框架,本系列博客就希望进行一定的 ...
- 【DeepLearning】AlexNet
在前文中,我们介绍了LeNet的相关细节,它是由两个卷积层.两个池化层以及两个全链接层组成.卷积都是5*5的模板,stride =1,池化为MAX.整体来说它有三大特点:局部感受野,权值共享和池化.2 ...
- 【网络结构】GoogLeNet inception-v1:Going deeper with convolutions论文笔记
目录 0. 论文链接 1. 概述 2. inception 3. GoogleNet 参考链接 @ 0. 论文链接 1. 概述 GoogLeNet是谷歌团队提出的一种大体保持计算资源不变的前提下, ...
- 【DeepLearning】优化算法:SGD、GD、mini-batch GD、Moment、RMSprob、Adam
优化算法 1 GD/SGD/mini-batch GD GD:Gradient Descent,就是传统意义上的梯度下降,也叫batch GD. SGD:随机梯度下降.一次只随机选择一个样本进行训练和 ...
- 【DeepLearning】深入理解dropout正则化
本文为转载,作者:Microstrong0305 来源:CSDN 原文:https://blog.csdn.net/program_developer/article/details/80737724 ...
- 【DeepLearning】Exercise:Softmax Regression
Exercise:Softmax Regression 习题的链接:Exercise:Softmax Regression softmaxCost.m function [cost, grad] = ...
- 【DeepLearning】Exercise:Convolution and Pooling
Exercise:Convolution and Pooling 习题链接:Exercise:Convolution and Pooling cnnExercise.m %% CS294A/CS294 ...
随机推荐
- WPF DataGrid 复合表头 (实现表头合并,自定义表头)
功能说明: 将 DataGrid嵌套在本控件内,使用Label自定义表头,如果需要上下左右滚动 需要在控件外围添加 ScrollViewer 并且设置 ScrollVisibility 为Auto ...
- 关于VS编译报错,但是错误信息未提示问题解决方案
可能代码中引用了别的类库中的函数,然后未编译被引用库导致编译报错,重新编译被引用库然后再编译当前库即可解决问题
- 【性能监控-Perfmon工具】Perfmon工具使用教程
一.Perfmon工具简介 Perfmon是一款Windows自带的性能监控工具,提供了图表化的系统性能实时监视器.性能日志和警报管理.通过添加性能计数器可以实现对CPU.内存.网络.磁盘.进程等多类 ...
- gRPC-微服务间通信实践
微服务间通信常见的两种方式 由于微服务架构慢慢被更多人使用后,迎面而来的问题是如何做好微服务间通信的方案.我们先分析下目前最常用的两种服务间通信方案. gRPC(rpc远程调用) 场景:A服务主动发起 ...
- shiro认证流程源码分析--练气初期
写在前面 在上一篇文章当中,我们通过一个简单的例子,简单地认识了一下shiro.在这篇文章当中,我们将通过阅读源码的方式了解shiro的认证流程. 建议大家边读文章边动手调试代码,这样效果会更好. 认 ...
- Matlab中的uigetfile用法
参考:https://ww2.mathworks.cn/help/matlab/ref/uigetfile.html?searchHighlight=uigetfile&s_tid=doc_s ...
- MQTT消息队列压力测试
环境准备: jmeter插件下载:mqttxmeter1.0.1jarwithdependencies.jar 把MQTT插件放在 %JMeter_Home%/lib/ext下.重启jmeter. M ...
- 一文带你定制unittest测试用例的名称
在之前的文章中,我在之前的文章中提到过,这里呢,考虑后,感觉之前的写法不够优雅,于是乎呢,我自己抽空去研究了下,主要是新写方法,这样呢,以后的要使用的时候,可以直接去使用,而不是每次换个环境就要修改环 ...
- ORA-00001: unique constraint (string.string) violated 违反唯一约束条件(.)
ORA-00001: unique constraint (string.string) violated ORA-00001: 违反唯一约束条件(.) Cause: An UPDATE or I ...
- 关于android和Linux的一些问题
1.Android为什么选择java? 由于java虚拟机,实现软件层的编程与硬件无关性(无需进行特定编译或平台配置). 2.Android和Linux内核区别? Android上的应用软件运行在da ...