python批量爬取猫咪图片
不多说直接上代码
首先需要安装需要的库,安装命令如下
pip install BeautifulSoup
pip install requests
pip install urllib
pip install lxmlfrom bs4 import BeautifulSoup # 贵族名宠网页爬虫
import requests
import urllib.request
# 网址
url = 'http://www.hengdadog.com/sale-1.html'
def allpage(): # 获得所有网页
all_url = []
for i in range(1, 8): #循环翻页次数
each_url = url.replace(url[-6], str(i)) # 替换
all_url.append(each_url)
return (all_url) # 返回地址列表 if __name__ == '__main__':
img_url = allpage() # 调用函数
for url in img_url:
# 获得网页源代码
print(url)
requ = requests.get(url)
req = requ.text.encode(requ.encoding).decode()
html = BeautifulSoup(req, 'lxml')
t = 0
# 选择目标url
img_urls = html.find_all('img')
for k in img_urls:
img = k.get('src') # 图片
print(img)
name = str(k.get('alt')) # 名字,这里的强制类型转换很重要
type(name)
# 先本地新建一下文件夹,保存图片并且命名
path = 'F:\\CAT\\' # 路径
file_name = path + name + '.jpg'
imgs = requests.get(img) # 存储入文件
try:
urllib.request.urlretrieve(img, file_name) # 打开图片地址,下载图片保存在本
except:
print("error")
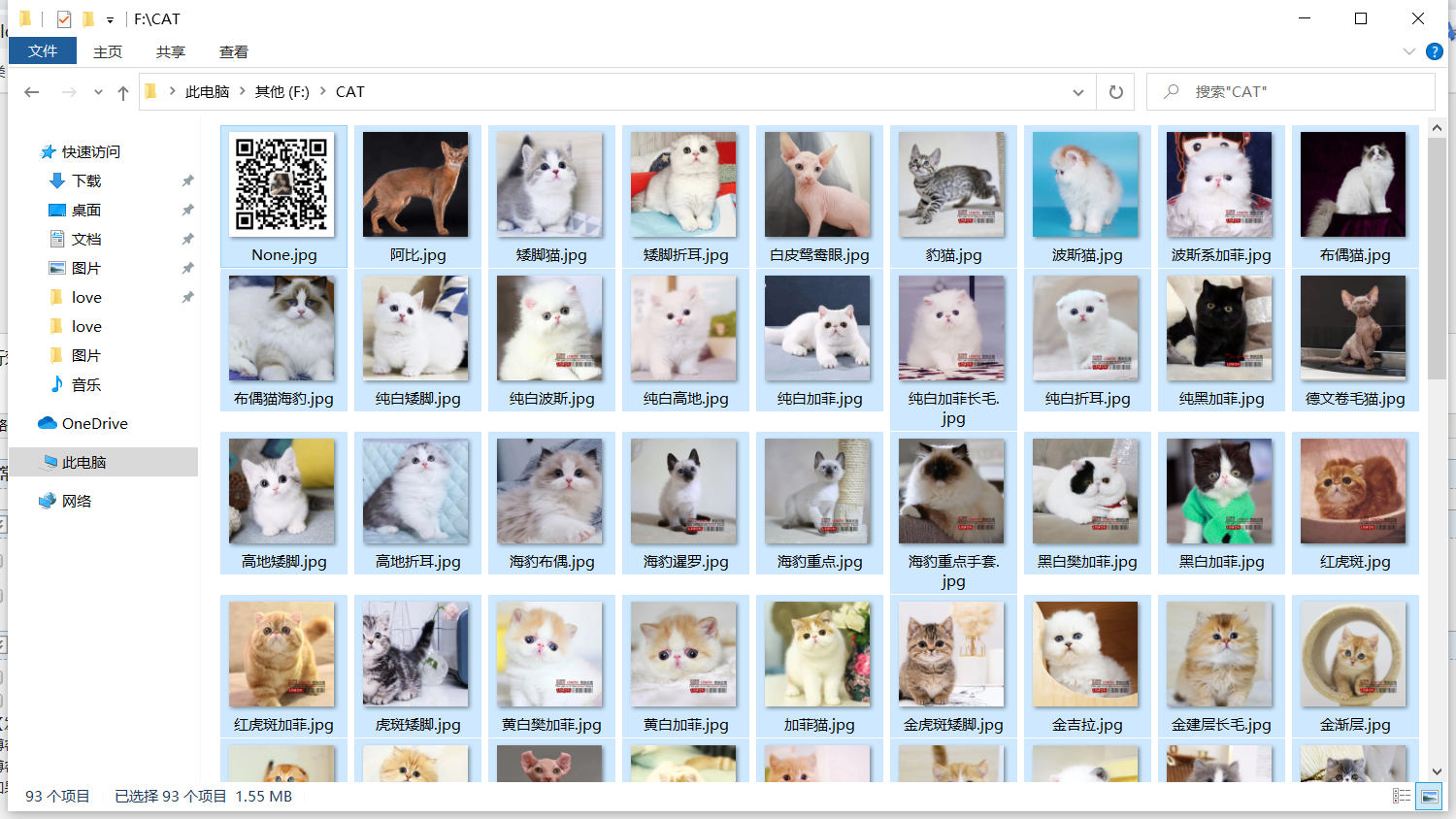
运行效果:
上面代码有不少缺陷,比如需要手动创建目录以及判断目录是否存在,下载没有提示,于是做了些优化:
from bs4 import BeautifulSoup # 贵族名宠网页爬虫
import requests
import urllib.request
import os
# 网址
url = 'http://www.hengdadog.com/sale-1.html'
if os.path.exists('F:\\CAT'):#判断目录是否存在,存在则跳过,不存在则创建
pass
else:
os.mkdir('F:\\CAT')
def allpage(): # 获得所有网页
all_url = []
for i in range(1, 10): #循环翻页次数
each_url = url.replace(url[-6], str(i)) # 替换
all_url.append(each_url)
return (all_url) # 返回地址列表 if __name__ == '__main__':
img_url = allpage() # 调用函数
for url in img_url:
# 获得网页源代码
print(url)
requ = requests.get(url)
req = requ.text.encode(requ.encoding).decode()
html = BeautifulSoup(req, 'lxml')
t = 0
# 选择目标url
img_urls = html.find_all('img')
for k in img_urls:
img = k.get('src') # 图片
print(img)
name = str(k.get('alt')) # 名字,这里的强制类型转换很重要
type(name)
# 保存图片并且命名
path = 'F:\\CAT\\' # 路径
file_name = path + name + '.jpg'
imgs = requests.get(img) # 存储入文件
try:
urllib.request.urlretrieve(img, file_name) # 打开图片地址,下载图片保存在本地,
print('正在下载图片到F:\CAT目录······')
except:
print("error")
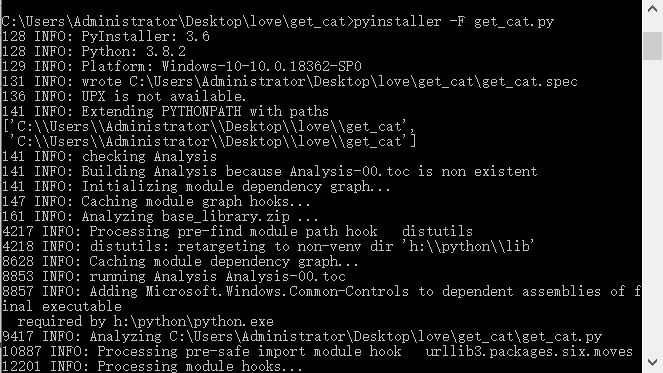
打包成EXE文件:
进入文件目录输入如下命令
pyinstaller -F get_cat.py
python批量爬取猫咪图片的更多相关文章
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
- python爬虫——爬取NUS-WIDE数据库图片
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需 ...
- python 批量爬取四级成绩单
使用本文爬取成绩大致有几个步骤:1.提取表格(或其他格式文件——含有姓名,身份证等信息)中的数据,为进行准考证爬取做准备.2.下载准考证文件并提取出准考证和姓名信息.3.根据得到信息进行数据分析和存储 ...
- 用Python批量爬取优质ip代理
前言 有时候爬的次数太多时ip容易被禁,所以需要ip代理的帮助.今天爬的思路是:到云代理获取大量ip代理,逐个检测,将超时不可用的代理排除,留下优质的ip代理. 一.爬虫分析 首先看看今天要爬取的网址 ...
- python批量爬取动漫免费看!!
实现效果 运行环境 IDE VS2019 Python3.7 Chrome.ChromeDriver Chrome和ChromeDriver的版本需要相互对应 先上代码,代码非常简短,包含空行也才50 ...
- Python批量爬取谷歌原图,2021年最新可用版
文章目录 前言 一.环境配置 1.安装selenium 2.使用正确的谷歌浏览器驱动 二.使用步骤 1.加载chromedriver.exe 2.设置是否开启可视化界面 3.输入关键词.下载图片数.图 ...
- python 批量爬取代理ip
import urllib.request import re import time import random def getResponse(url): req = urllib.request ...
- java爬取猫咪上的图片
首先是对知识点归纳 1.用到获取网页源代码,分析图片地址,发现图片的地址都是按编号排列的,所以想到用循环获取 2.保存图片要用到流操作和文件操作,对两部分知识进行了复习巩固 3.保存后的图片有一部分是 ...
随机推荐
- IOS8 对flex兼容性问题
问题: IOS8.2 dispaly:flex:不生效: 注意一下兼容写法的顺序问题, display: -webkit-box; /* Chrome 4+, Safari 3.1, iOS Saf ...
- OpenCV开发笔记(七十三):红胖子8分钟带你使用opencv+dnn+yolov3识别物体
前言 级联分类器的效果并不是很好,准确度相对深度学习较低,上一章节使用了dnn中的tensorflow,本章使用yolov3模型,识别出具体的分类. Demo 320x320,置信度0 ...
- 本地文件r如何上传到github上
来源:http://www.cnblogs.com/shenchanghui/p/7184101.html 来源:http://blog.csdn.net/zamamiro/article/detai ...
- 源码都没调试过,怎么能说熟悉 redis 呢?
一:背景 1. 讲故事 记得在很久之前给初学的朋友们录制 redis 视频课程,当时结合了不少源码进行解读,自以为讲的还算可以,但还是有一个非常核心的点没被分享到,那就是源码级调试, 对,读源码还远远 ...
- 【转】Loading PNGs with SDL_image
FROM:http://lazyfoo.net/tutorials/SDL/06_extension_libraries_and_loading_other_image_formats/index2. ...
- P5530 [BOI 2002]双调路径
题意描述 [BOI 2002]双调路径 题意描述的确实不是很清楚(出题人惜字如金). 给定一张有 \(n\) 个点,\(m\) 条边的无向图,每条边有两个权值,分别表示经过这个点的代价和时间. 同时给 ...
- P1948 [USACO08JAN]Telephone Lines S
题意描述 在无向图中求一条从 \(1\) 到 \(N\) 的路径,使得路径上第 \(K+1\) 大的边权最小. 等等,最大的最小...如此熟悉的字眼,难道是 二分答案. 下面进入正题. 算法分析 没错 ...
- Java并发队列与容器
[前言:无论是大数据从业人员还是Java从业人员,掌握Java高并发和多线程是必备技能之一.本文主要阐述Java并发包下的阻塞队列和并发容器,其实研读过大数据相关技术如Spark.Storm等源码的, ...
- 构建者模式(Builder pattern)
构建者模式应用场景: 主要用来构建一些复杂对象,这里的复杂对象比如说:在建造大楼时,需要先打牢地基,搭建框架,然后自下向上地一层一层盖起来.通常,在建造这种复杂结构的物体时,很难一气呵成.我们需要首先 ...
- XJOI 夏令营501-511测试11 统计方案
小B写了一个程序,随机生成了n个正整数,分别是a[1]..a[n],他取出了其中一些数,并把它们乘起来之后模p,得到了余数c.但是没过多久,小B就忘记他选了哪些数,他想把所有可能的取数方案都找出来.你 ...