Elasticsearch如何保证数据不丢失?
如何保证数据写入过程中不丢
数据写入请求达到时,以需要的数据格式组织并写入磁盘的过程叫做数据提交,对应es就是创建倒排索引,维护segment文件
如果我们同步的方式,来处理上述过程,那么系统的吞吐量将很低
如果我们以异步的方式,先写入内存,然后再异步提交到磁盘,则有可能因为机器故障而而丢失还未写入到磁盘中的数据
为了解决这个问题,一般的存储系统都会设计transag log (事务日志)或这write ahead log(预写式日志)。它的作用时,将最近的写入数据或操作以日志的形式直接落盘,从而使得即便系统崩溃后,依然可以基于这些磁盘日志进行数据恢复。
Mysql有redo undo log ,而HBASE、LevelDB,RockDB等采用的LSM tree则提供了write ahead log 这样的设计,来保证数据的不丢失
直接落盘的 translog 为什么不怕降低写入吞吐量?
上述论述中,数据以同步方式落盘会有性能问题,为什么将translog和wal直接落盘不影响性能?原因如下:
- 写的日志不需要维护复杂的数据结构,它仅用于记录还未真正提交的业务数据。所以体量小
- 并且以顺序方式写盘,速度快
es默认是每个请求都会同步落盘translog ,即配置index.translog.durability 为request。当然对于一些可以丢数据的场景,我们可以将index.translog.durability配置为async 来提升写入translog的性能,该配置会异步写入translog到磁盘。具体多长时间写一次磁盘,则通过index.translog.sync_interval来控制
前面说了,为了保证translog足够小,所以translog不能无限扩张,需要在一定量后,将其对应的真实业务数据以其最终数据结构(es是倒排索引)提交到磁盘,这个动作称为flush ,它会实际的对底层Lucene 进行一次commit。我们可以通过index.translog.flush_threshold_size 来配置translog多大时,触发一次flush。每一次flush后,原translog将被删除,重新创建一个新的translog
elasticsearch本身也提供了flush api来触发上述commit动作,但无特殊需求,尽量不要手动触发
如何保证已写数据在集群中不丢
对每个shard采用副本机制。保证写入每个shard的数据不丢
in-memory buffer
前述translog只是保证数据不丢,为了其记录的高效性,其本身并不维护复杂的数据结构。 实际的业务数据的会先写入到in-memory buffer中,当调用refresh后,该buffer中的数据会被清空,转而reopen一个segment,使得其数据对查询可见。但这个segment本身也还是在内存中,如果系统宕机,数据依然会丢失。需要通过translog进行恢复
其实这跟lsm tree非常相似,新写入内存的业务数据存放在内存的MemTable(对应es的in-memory buffer),它对应热数据的写入,当达到一定量并维护好数据结构后,将其转成内存中的ImmutableMemTable(对应es的内存segment),它变得可查询。
总结
refresh 用于将写入内存in-memory buffer数据,转为查询可见的segment
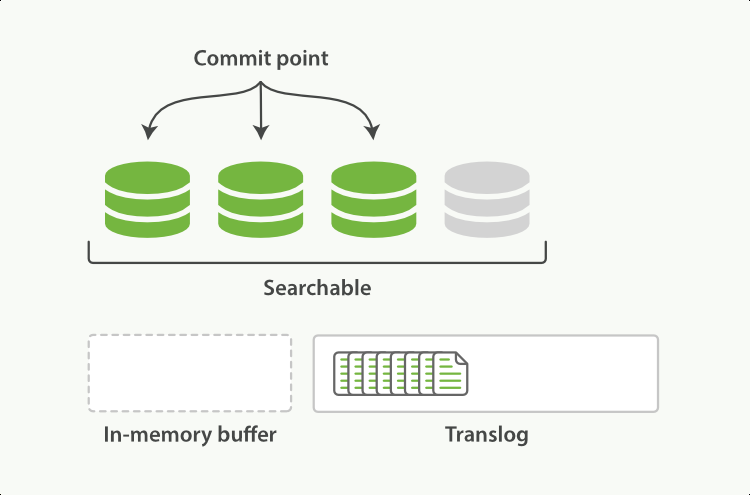
每次一次写入除了写入内存外in-memory buffer,还会默认的落盘translog
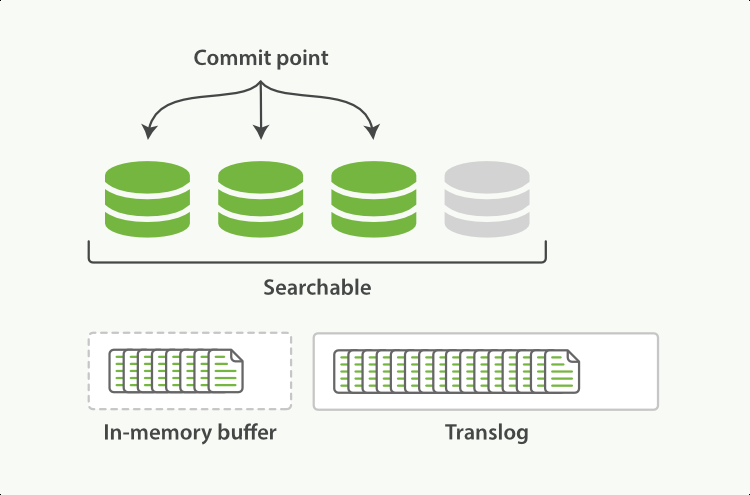
translog 达到一定量后,触发in-memory buffer落盘,并清空自己,这个动作叫做flush
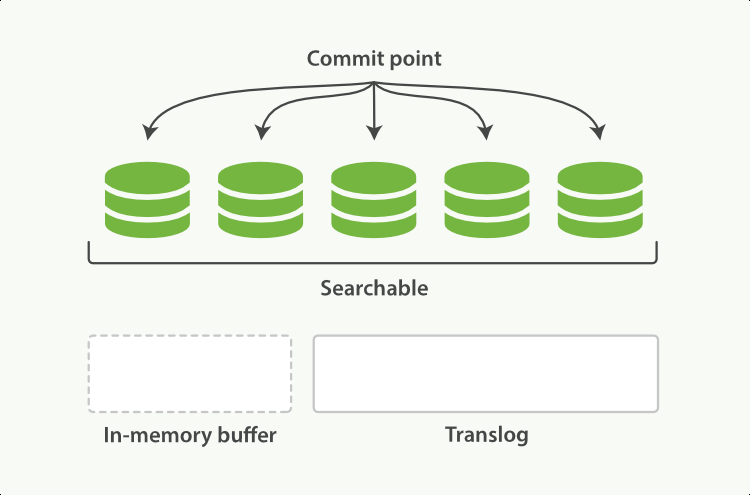
如遇当前写入的shard宕机,则可以通过磁盘中的translog进行数据恢复
LSM Tree的详细介绍
https://www.cnblogs.com/niceshot/p/14321372.html
参考资料
https://ezlippi.com/blog/2018/04/elasticsearch-translog.html
https://stackoverflow.com/questions/19963406/refresh-vs-flush
https://qbox.io/blog/refresh-flush-operations-elasticsearch-guide/
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html#index-modules-translog-retention
https://www.elastic.co/guide/cn/elasticsearch/guide/current/translog.html
欢迎关注我的个人公众号"西北偏北UP",记录代码人生,行业思考,科技评论
Elasticsearch如何保证数据不丢失?的更多相关文章
- Spark Streaming使用Kafka保证数据零丢失
来自: https://community.qingcloud.com/topic/344/spark-streaming使用kafka保证数据零丢失 spark streaming从1.2开始提供了 ...
- Kafka如何保证数据不丢失
Kafka如何保证数据不丢失 1.生产者数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到,其中状态有0,1,-1. 如果是 ...
- [转帖]kafka 如何保证数据不丢失
kafka 如何保证数据不丢失 https://www.cnblogs.com/MrRightZhao/p/11498952.html 一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数 ...
- kafka 如何保证数据不丢失
一般我们在用到这种消息中件的时候,肯定会考虑要怎样才能保证数据不丢失,在面试中也会问到相关的问题.但凡遇到这种问题,是指3个方面的数据不丢失,即:producer consumer 端数据不丢失 b ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- rabbitmq保证数据不丢失方案
rabbitmq如何保证消息的可靠性 1.保证消息不丢失 1.1.开启事务(不推荐) 1.2.开启confirm(推荐) 1.3.开启RabbitMQ的持久化(交换机.队列.消息) 1.4.关闭Rab ...
- kafka保证数据不丢失机制
kafka如何保证数据的不丢失 1.生产者如何保证数据的不丢失:消息的确认机制,使用ack机制我们可以配置我们的消息不丢失机制为-1,保证我们的partition的leader与follower都保存 ...
- Spark Streaming和Kafka整合是如何保证数据零丢失
转载:https://www.iteblog.com/archives/1591.html 当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢 ...
- 23 mysql怎么保证数据不丢失?
MySQL的wal机制,得到的结论是:只要redo log和binlog 持久化到磁盘,就能确保mysql异常重新启动后,数据是可以恢复的. binlog的写入机制 其实,binlog的写入逻辑比较简 ...
随机推荐
- Tomcat服务器的下载以及配置
1,Tomcat的下载与安装 本人采用的是解压版安装,只需要在官网(https://tomcat.apache.org/)下载好压缩版的Tomcat,再解压在你想安装的目录下即可.我的安装目录是D:\ ...
- redis 作为 mysql的缓存服务器(读写分离)
redis 作为 mysql的缓存服务器(读写分离) 一.redis简介 Redis是一个key-value存储系统.和Memcached类似,为了保证效率,数据都是缓存在内存中.区别的是redis会 ...
- C++ string的内部究竟是什么样的?
在C语言中,有两种方式表示字符串: 一种是用字符数组来容纳字符串,例如char str[10] = "abc",这样的字符串是可读写的: 一种是使用字符串常量,例如char *st ...
- android基本组件 Button
android中提供了普通按钮Buttton和图片按钮ImageButton两种按钮组件,ImageButton按钮中主要有一个android:src属性,用于设置按钮的背景图片.可以在Button的 ...
- Spark学习进度-RDD
RDD RDD 是什么 定义 RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数 ...
- java内部类笔记
内部类 1. 普通内部类 <pre name="code" class="java">class className{ [private|pro ...
- 初识sa-token,一行代码搞定登录授权!
前言 在java的世界里,有很多优秀的权限认证框架,如Apache Shiro.Spring Security 等等.这些框架背景强大,历史悠久,其生态也比较齐全. 但同时这些框架也并非十分完美,在前 ...
- js原型链原理
先附上原型链的图,能看懂的本文就没必要看了,看不懂的可以带着疑问看文章 一.构造函数 什么是构造函数:当一个普通函数创建一个类对象是,那么就程它为构造函数. 特点: 默认首字母大写 使用new关键字来 ...
- Mac Navicat premium 12 连接mysql8.0.21出现 'caching_sha2_password' 解决方案
1.通过命令 select user,plugin from user where user='root'; 我们可以发现加密方式是caching_sha2_password. 2. 修改查看加密方 ...
- 使用msys2在window下构建和使用Linux的软件
目录 前言 安装 使用 总结 前言 在window下构建Linux编译环境是很常见的,以前用过mingw弄过差不多的环境. 但是使用msys2后就根本停不下来咯,太好用咯. 安装 去官网下载吧,安装跟 ...