用隧道协议实现不同dubbo集群间的透明通信
用隧道协议实现不同dubbo集群间的透明通信
前言
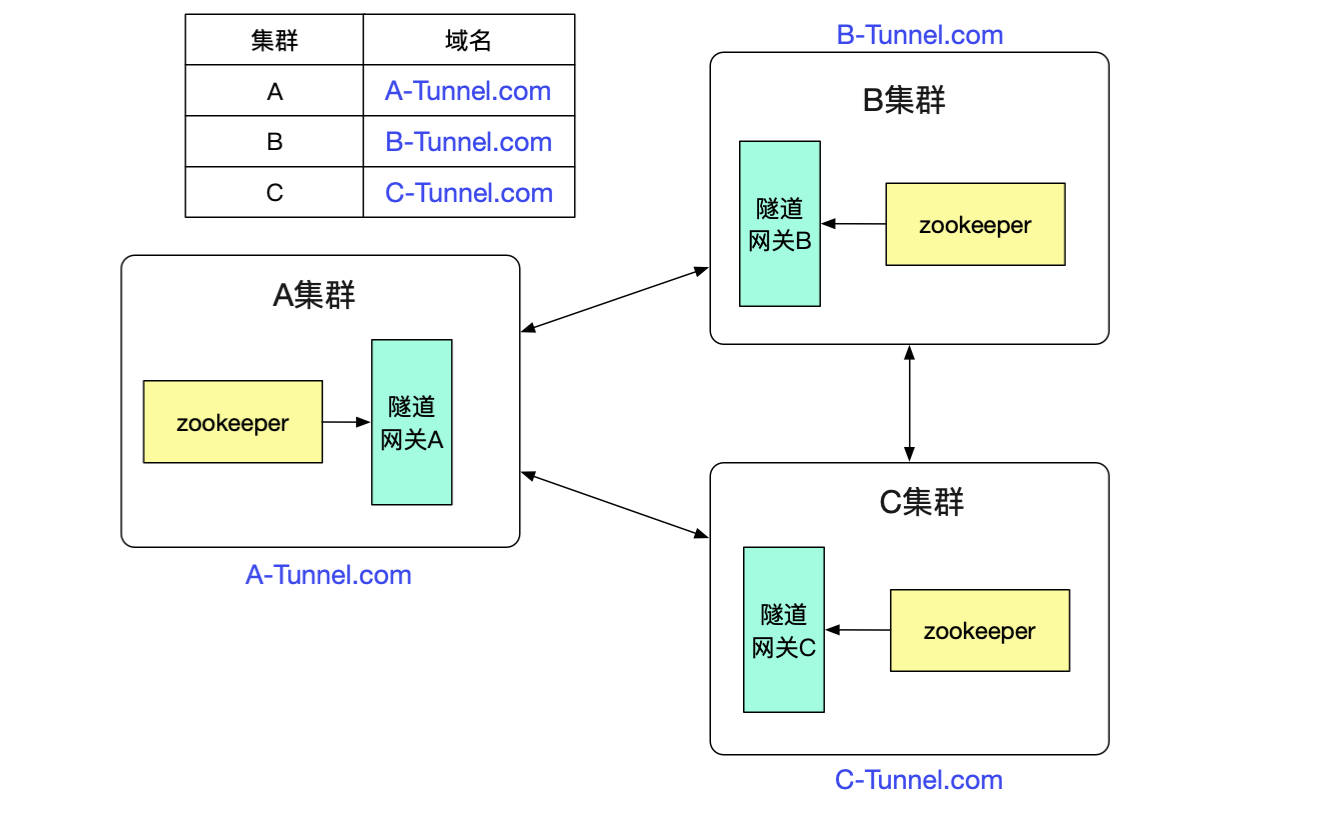
笔者最近完成了一个非常有意思的隧道机制(已在产线运行),可以让注册到不同zookeeper之间的dubbo集群之间能够正常进行通信。如下图所示:
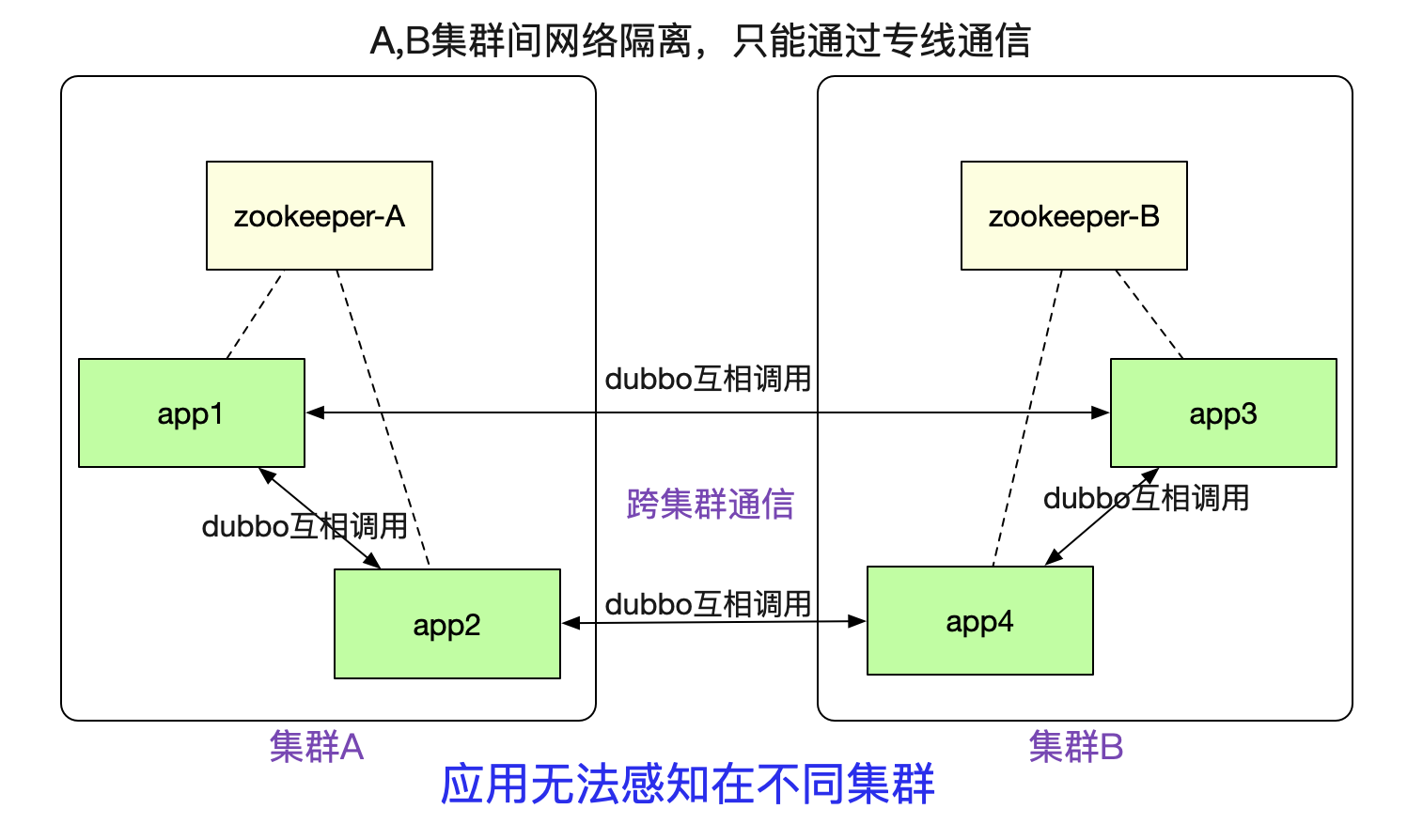
例如图中A/B两个网络隔离的集群,两者只能通过专线进行通信。但是对于在里面的应用来说,调用另外一个集群的dubbo服务(例如app1调用app3)依旧和原来的方式一模一样,无需做任何修改。这个特性对于新建单元(机房),业务网络隔离等场景非常有用。
本文就稍稍聊一下这个机制。
场景
这个dubbo集群通信机制,可被用在下面的场景中。
新建机房
在我们新建一个机房的过程中。正常情况下,需要将一整条链路的所有应用以及相关设施全部部署到新的机房中。如下图所示:
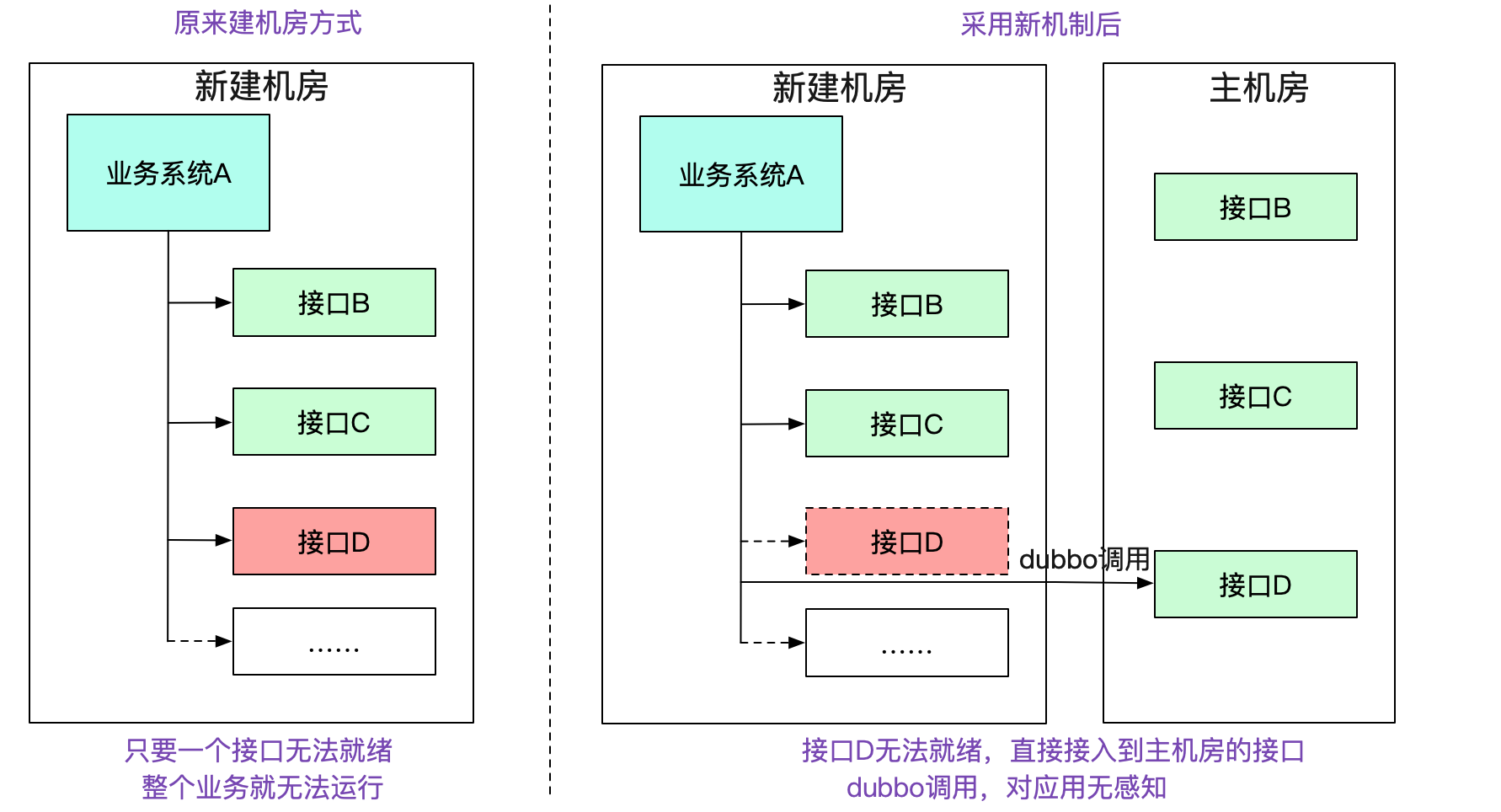
而在笔者新的机制中,如果本集群没有对应的接口,会去寻找有对应接口的集群,就算其中缺失了一些系统,整个机房依旧能够work,将新建机房变为可迭代式的。大幅度减少了新建机房的复杂性。
新建业务单元
由于单机房机架位的限制或者一些其它原因,有一些业务希望剥离到一个单独的单元(机房里面)。但是业务确需要一大堆原来单元的基础服务。而不同单元之间的网络又无法打通(安全性要求)。
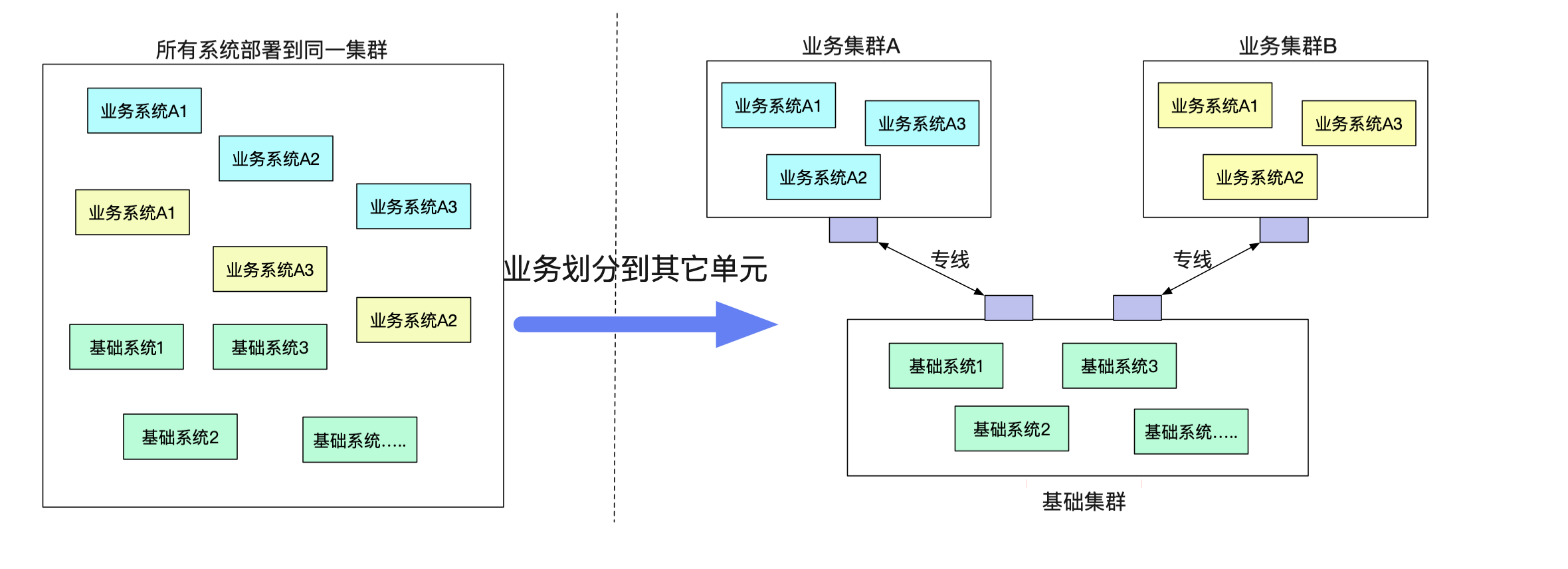
如果按照传统的模式,势必要对业务系统做改造,例如建立一个业务网关来负责和基础系统的通信,这个网关明显费时费力而且没什么技术含量,例如在业务代码中将dubbo调用强行转换为对业务网关的http调用,如下图所示:
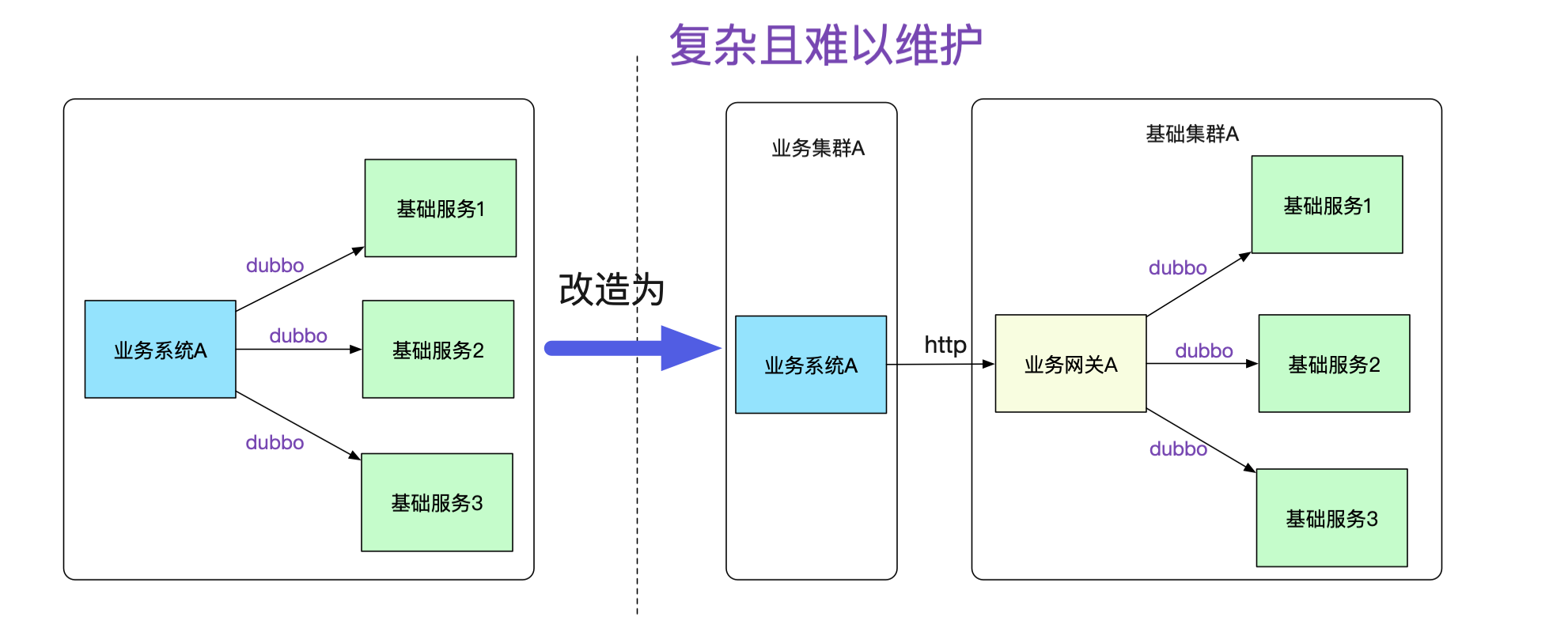
而且,每增加一个接口调用,都得在业务网关中转换一把,添加对应的接口包,然后发布。这样的网关维护起来肯定是个天坑!随着日益严格的安全性要求,不同业务间的网络隔离要求会与日俱增。
笔者是搞中间件的,坚信做的基础服务能够对业务透明,让其感知不到才是一个好的设计。一旦需要业务大量配合这种由基础架构变更而引起的改造,无疑是非常的不友好,甚至是个失败的设计。
故障隔离
事实上,笔者搞这一套隧道机制的初衷还有很大一部分原因是故障隔离。例如,笔者遇到数次由于业务系统使用zookeeper不当,往zookeeper写了一大堆数据,从而让整个集群陷入不可用的风险。而新的机制,可以让不同的业务注册到不同的zookeeper,zookeeper挂了,也只是这个业务宕了,其它业务则不受影响。
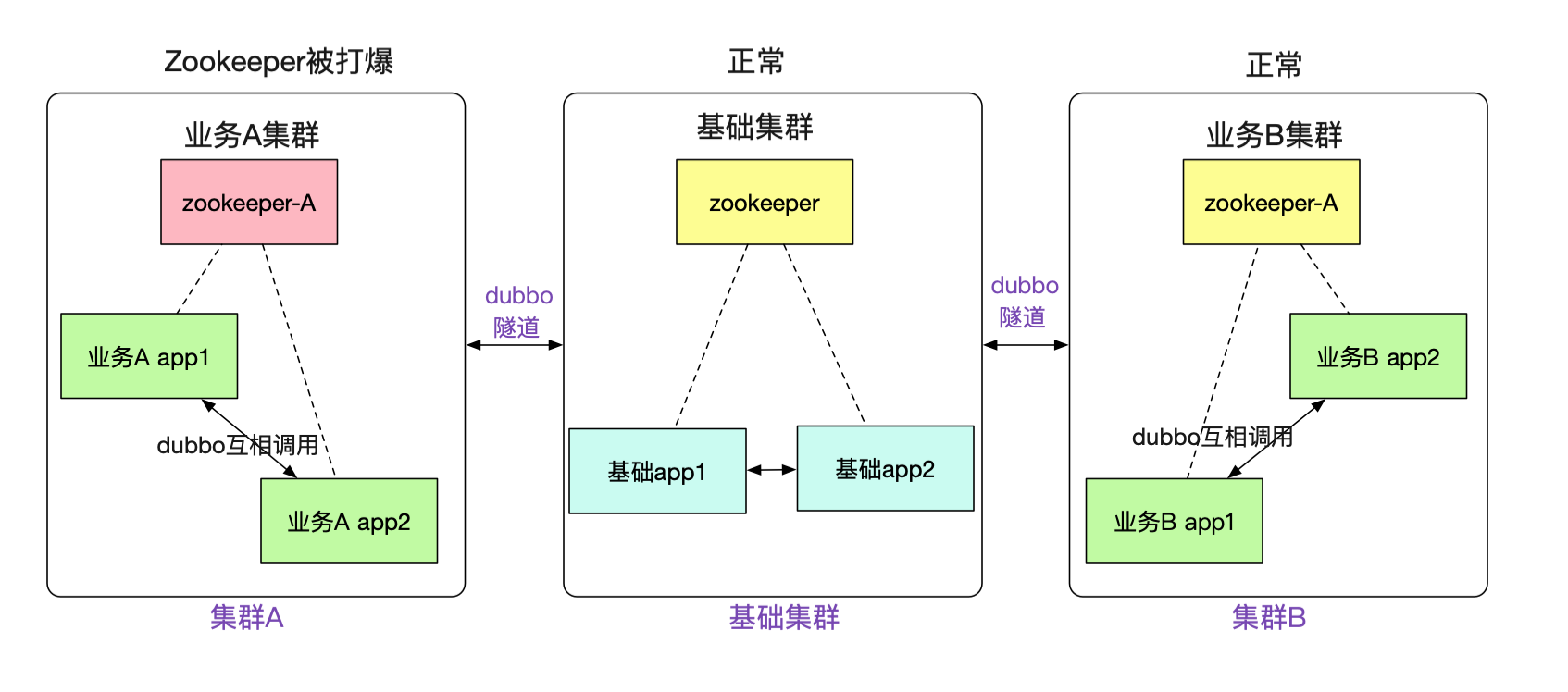
事实上不仅为zookeeper,由于笔者对消息(例如activemq)也做了这一套类似的隧道机制。使得我们的整个业务能够更好的进行故障隔离!
隧道机制
笔者这个机制的最大便利性在于对业务的侵入性很少。对于基础集群的应用甚至完全不需要做修改。为了达成这个需求,笔者引入了在网络上非常常用的隧道概念(Tunnel),这个大家可能平时都接触过,VPN/Vxlan这些网络协议都用了隧道。
隧道穿透
我们先来看一下最基本的原理,在系统A通过Dubbo调用系统B的时候,在同一个集群中走的是dubbo协议。而跨集群的时候,笔者将dubbo原始比特流承载在http协议上,在专线上发出去。
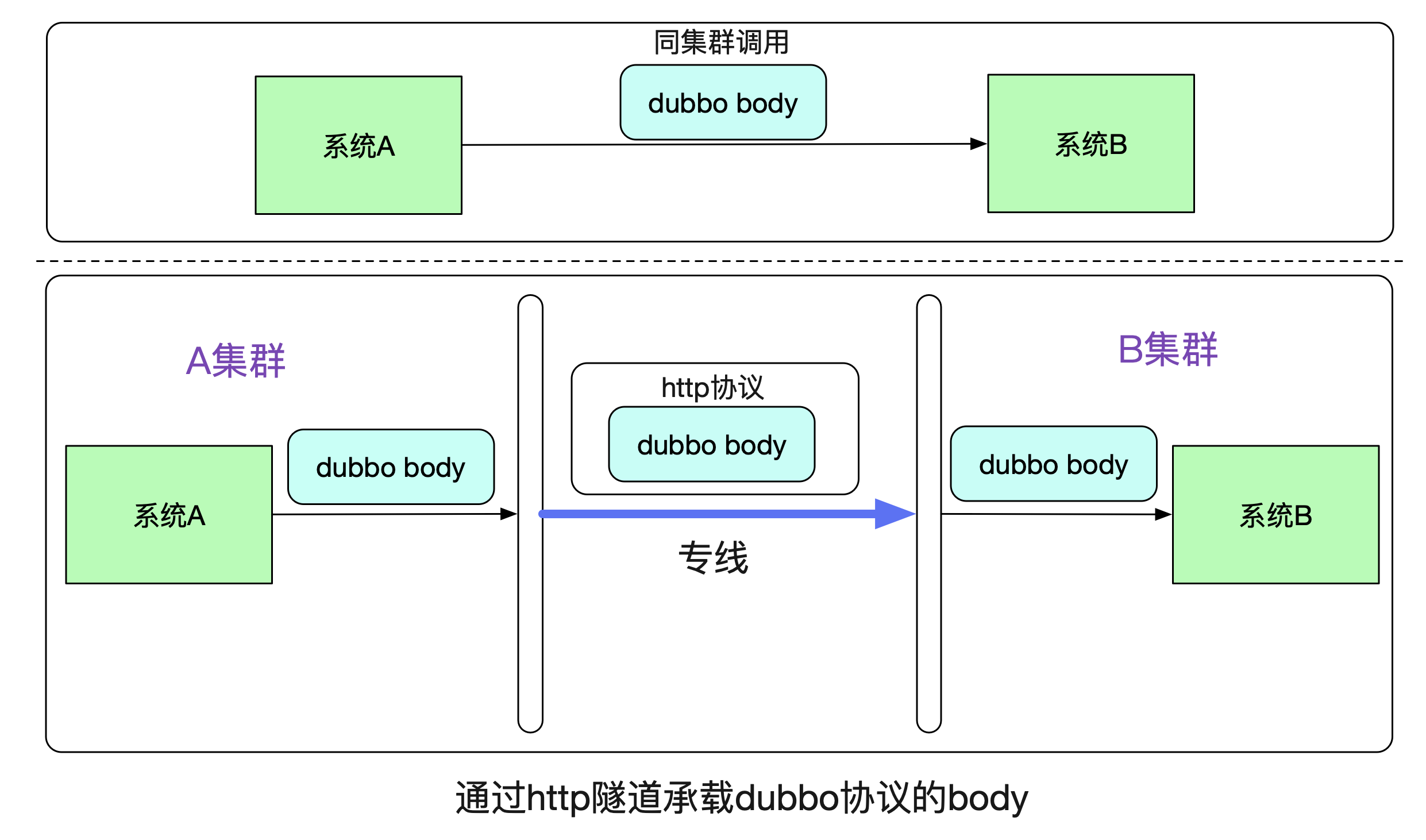
由于在B系统看来,接收到的都是相同的byte流,其无法(也不用)区分到底是走了一层专线还是直接调用。所以B系统无需更改任何代码。
隧道实现
那么,这个隧道具体是如何实现,系统A又是如何知道需要本集群没有对应的接口,需要通过http隧道调用到另一个集群的呢?这就引入了我们的隧道网关。
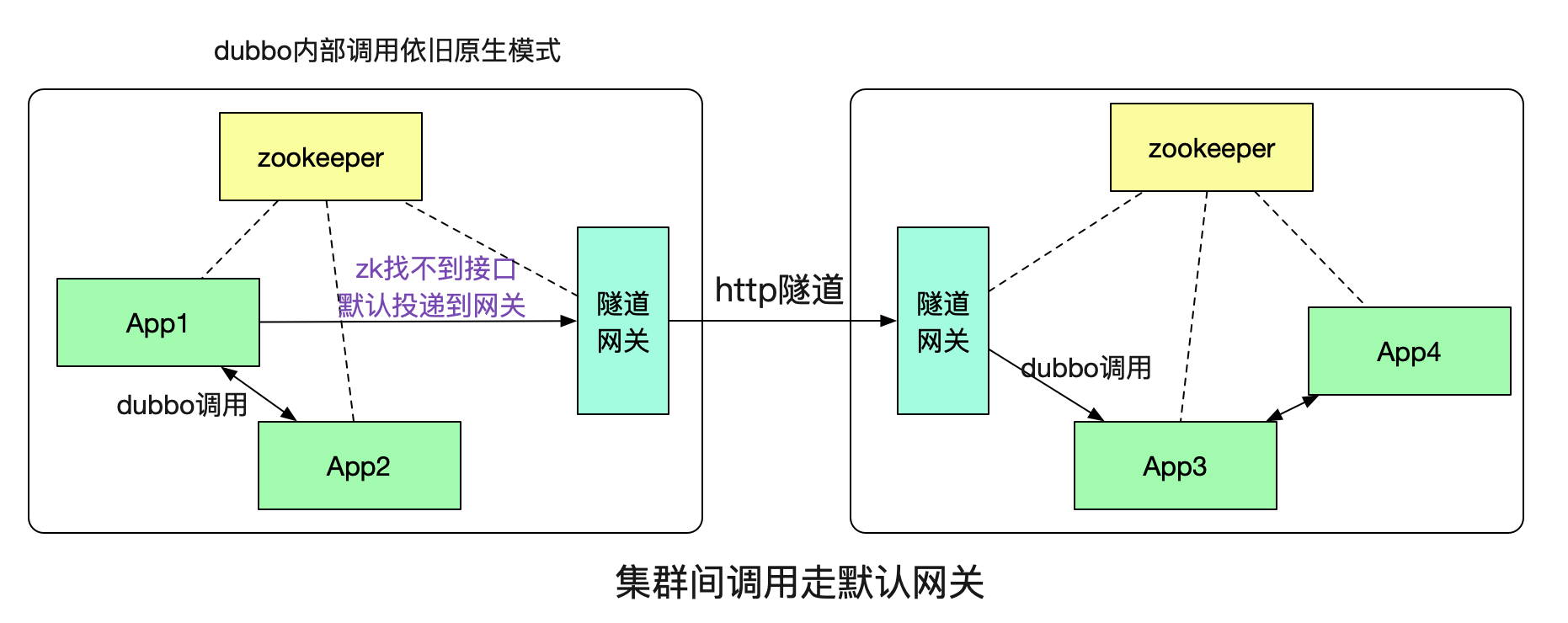
这里的概念也是和网络上的默认网关类似,如果本集群内找不到对应的接受者就投递到一个默认的网关,由这个隧道网关来替我们传递调用。
如何发现这个网关
为了充分利用dubbo接口的注册发现机制,笔者将隧道网关也暴露为一个dubbo接口,其输入和输出分别如下所示:
// 隧道网关接口请求体
class TunnelInterfaceReq {
// dubbo元信息,例如具体调用接口信息
MetaData dubbo
// 原始请求A调用序列化后的比特流
byte[] body;
}
// 隧道网关接口返回体
class TunnelInterfaceResp{
// dubbo元信息
MetaData dubbo
// 返回值调用序列化后的比特流,又另一个集群的对应系统返回
byte[] resp;
}
有了这个dubbo接口,我们就可以很容易的将数据传送给默认网关了。
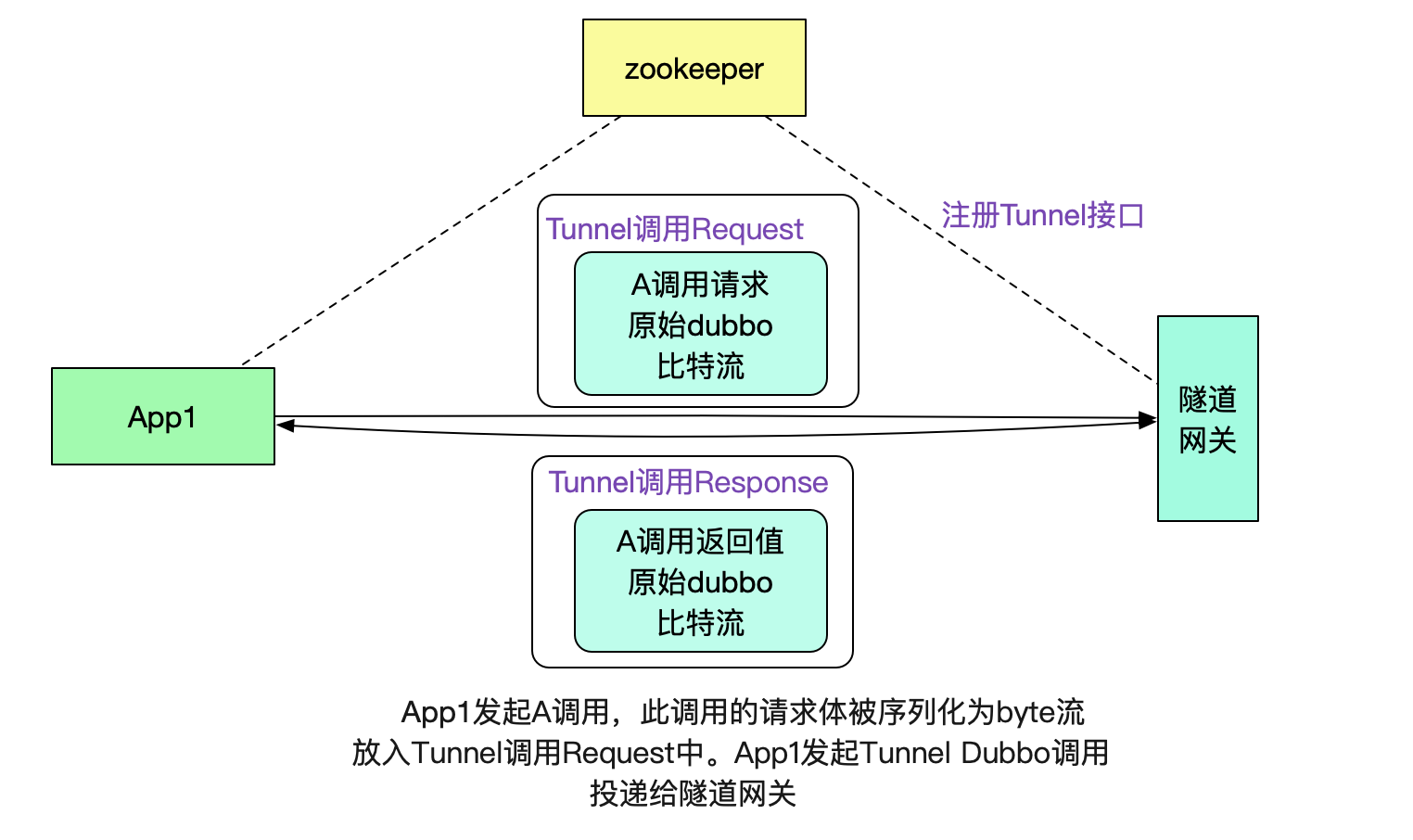
注意,这里其实也是做了一层隧道协议,即用dubbo协议承载dubbo协议,用这种类似套娃的方法有效的利用了dubbo本身的注册发现机制。
网关和网关之间通过http通信
由于不同集群之间通过专线进行通信,所以笔者采用了http通信来进行。在App1的请求到达隧道网关后,网关会将原始body比特流从TunnelInterfaceRequest中取出。然后放到一个http的请求中进行传递。如下图所示:

值得注意的是,由于传递的是byte流,没有携带任何业务信息(例如类型信息等),所以我们的隧道网关可以对任意dubbo请求进行隧道传输,而不像传统的网关那样需要添加各种业务对应的jar包并不停发布-_-!
在图中,投递到另一端的隧道网关后,其从http协议中取出调用元信息和原始调用byte流,通过调用元信息找到App2。然后给App2重放byte流,这样就可以进行dubbo调用了。事实上,App2从隧道网关看到的byte流和从集群内其它机器调用的byte流完全一致。如下图所示:
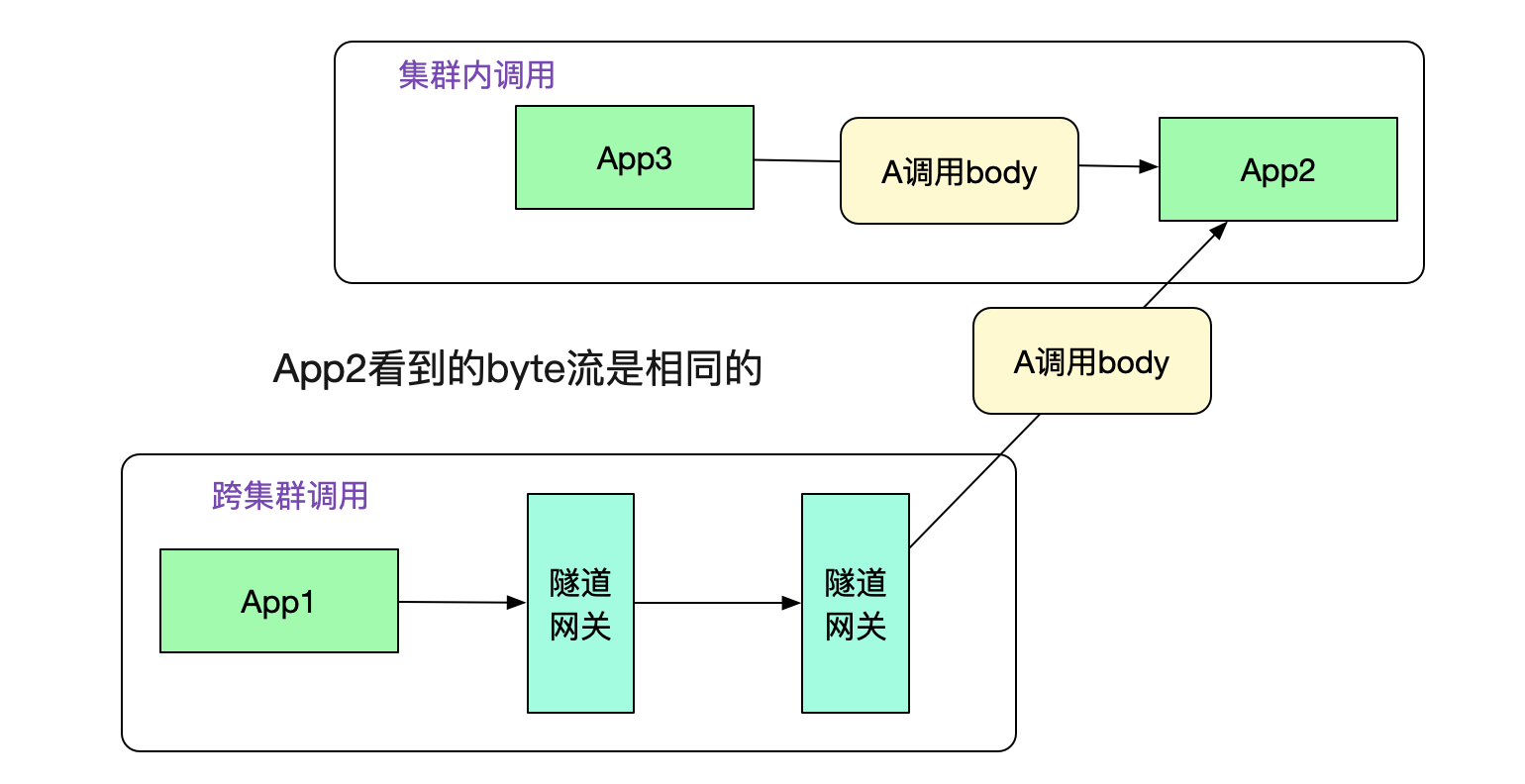
返回值也通过隧道机制
很明显的,我们的返回值也需要通过隧道机制。和Request一样,其也会走两次隧道协议,如下图所示:
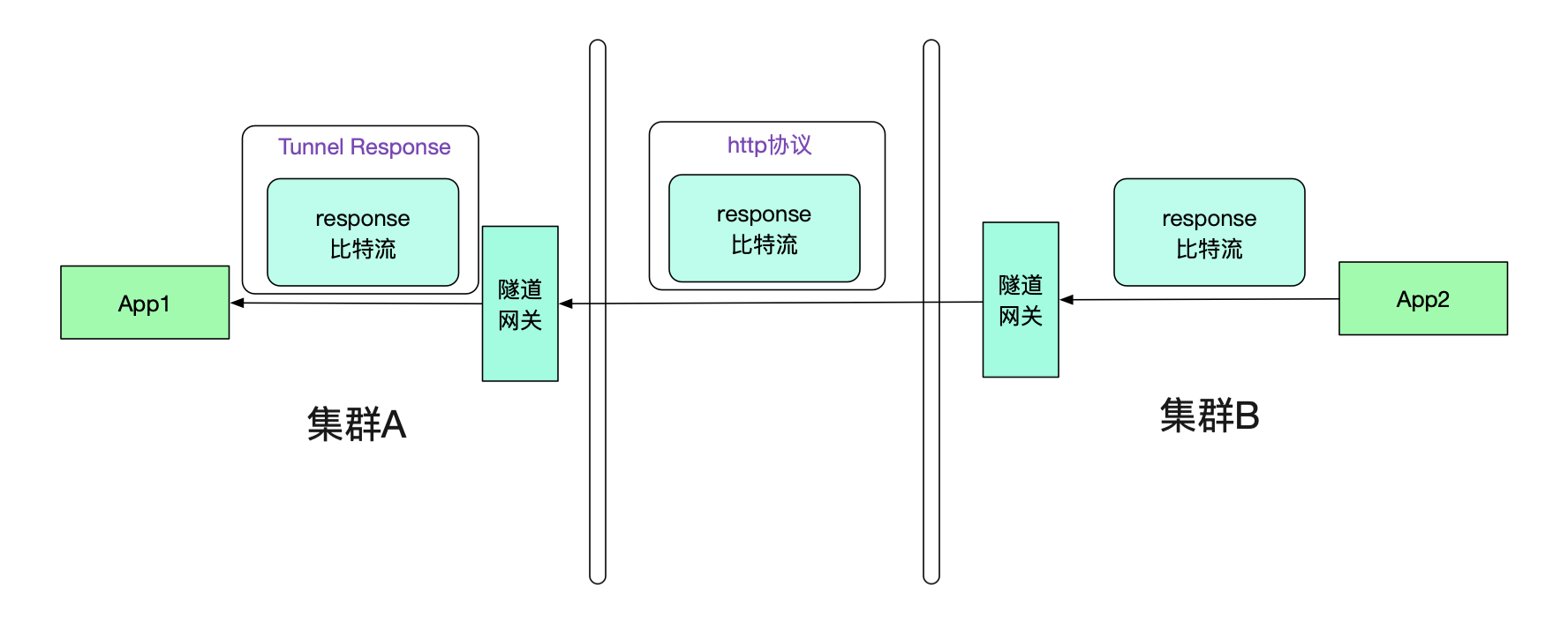
那么App1真正接收到的其实是Tunnel Response,怎么让其透明的接收原始response比特流呢?这就需要调用方接入笔者研发的轻量级jar包(其实,一开始的request的隧道也需要这样的jar包)
对dubbo进行扩展
由于dubbo有非常优秀的filter机制,可以在各种地方可以扩展。为了这个隧道机制,笔者就扩展了其中的invoke调用逻辑。如下图所示:

只要引入笔者写的jar包,就能够非常轻松的进行自动扩展,除了pom.xml加两行,其它业务代码完全无需修改。
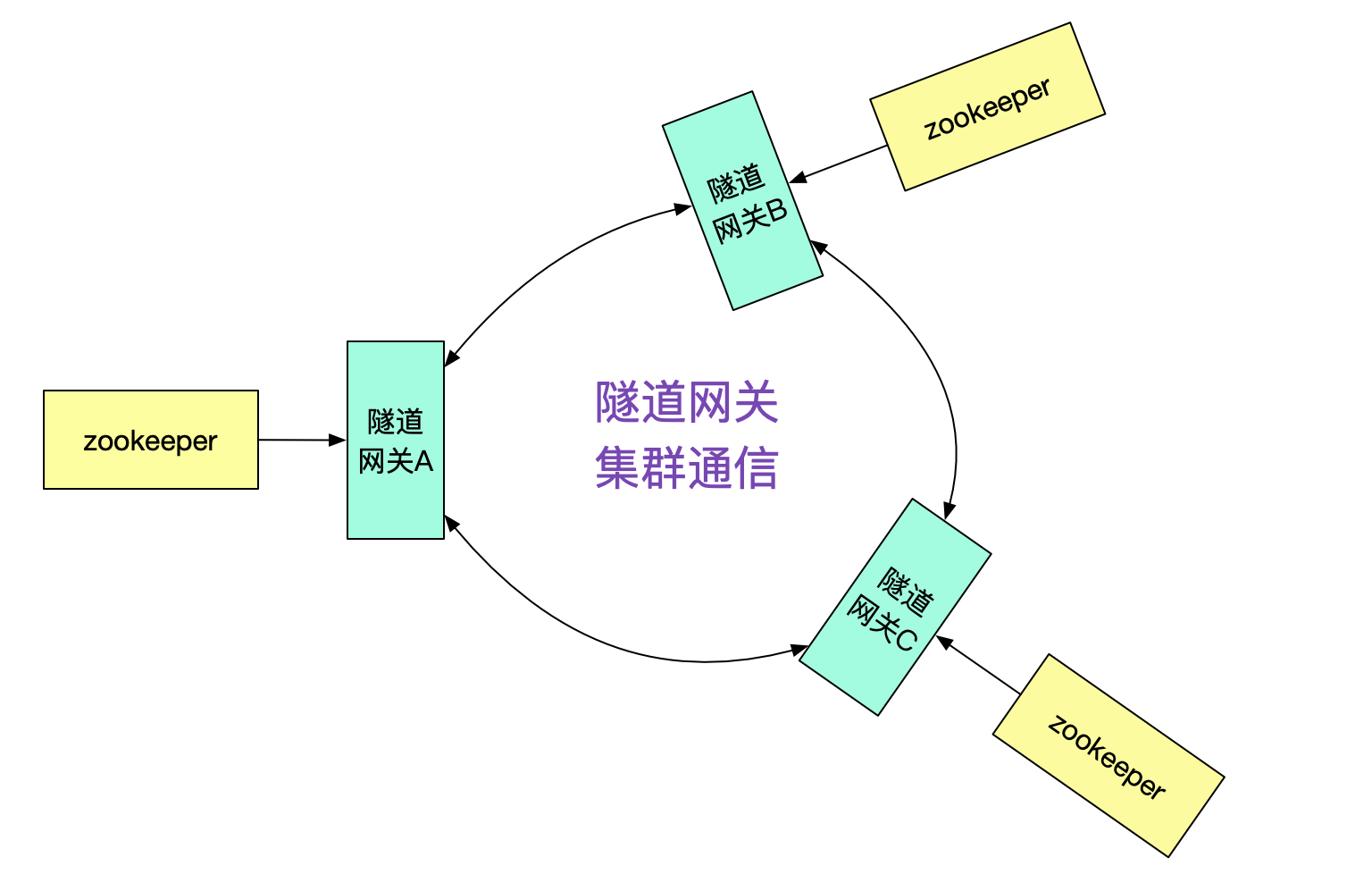
隧道网关的接口发现
那么隧道网关A是怎么知道接口在集群B,从而投递给隧道网关B的呢?很明显的,我们需要隧道网关间的集群通信机制。
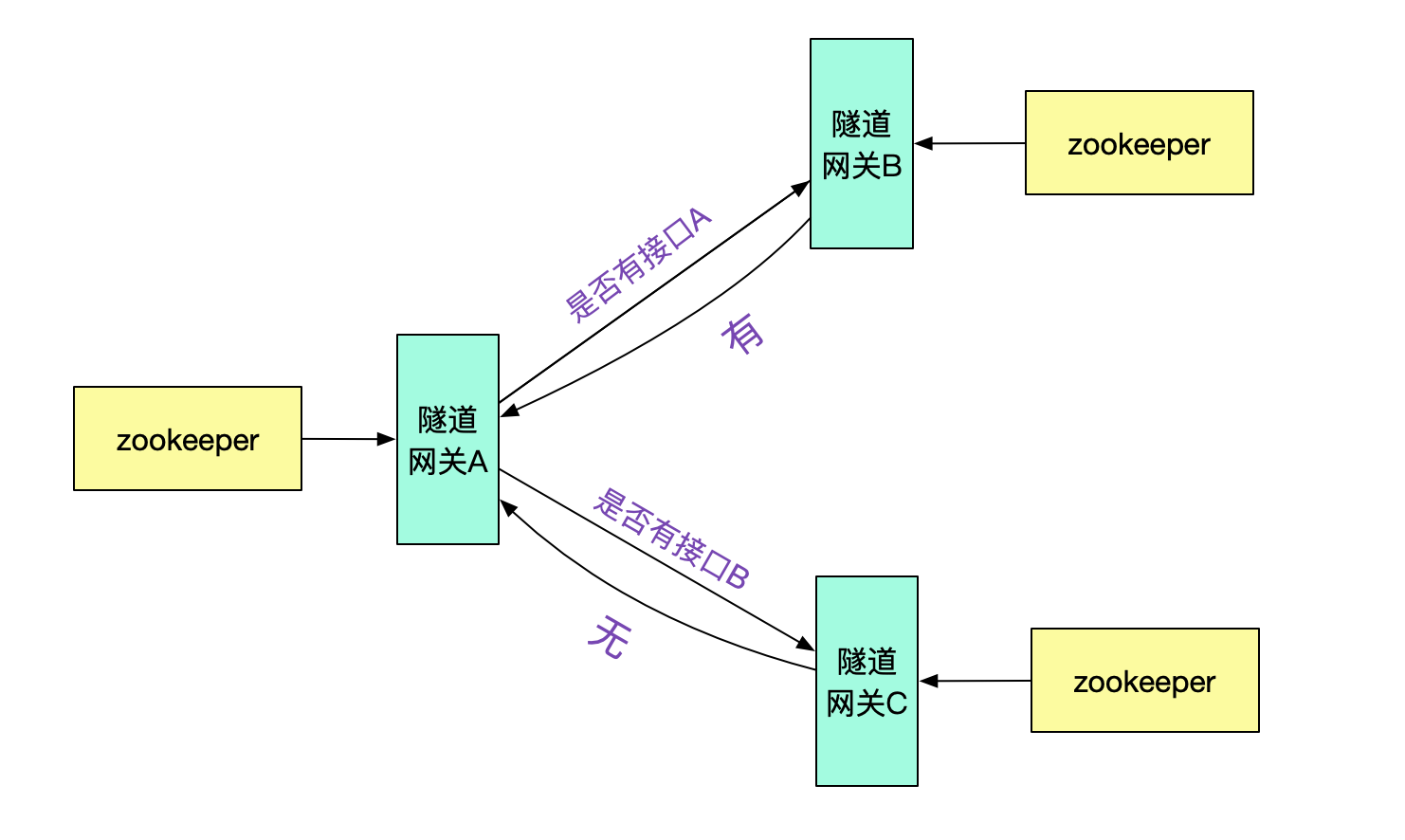
例如,由隧道网关向其它不同的隧道网关询问是否有此接口,并按一定策略做缓存即可。
dubbo集群的发现
最后的问题就是隧道网关怎么知道其它的dubbo集群的了,由于相对于dubbo接口数量,集群的数量是很少且不经常改变。我们只需要找个地方简单的记录下即可,例如放到数据库里面。然后由于是http调用,直接通过DNS解析域名即可做负载均衡。
性能
由于笔者的这套机制序列化和反序列化完全在Provider/Consumer端,完全没有对网关形成任何压力,所以网关的CPU消耗很低。在单个调用延迟上,由于多了两跳,不可避免的有所损耗,大概每个接口多了2ms左右。
总结
这套机制从一开始构想,到完全能够在产线运行,并且性能损耗还很小,笔者还是花费了不少的精力。看到这样的结果,还是非常有成就感的。事实上,这套隧道机制在非常多的地方借鉴了网络上的概念。可谓它山之石可以攻玉!不同技术之间确实可以相互迁移,他们只是在不同的层级上解决了本质相通的问题!
欢迎大家关注我公众号,里面有各种干货,还有大礼包相送哦!

用隧道协议实现不同dubbo集群间的透明通信的更多相关文章
- Dubbo学习(二) Dubbo 集群容错模式-负载均衡模式
Dubbo是Alibaba开源的分布式服务框架,我们可以非常容易地通过Dubbo来构建分布式服务,并根据自己实际业务应用场景来选择合适的集群容错模式,这个对于很多应用都是迫切希望的,只需要通过简单的配 ...
- 相同版本的CDH集群间迁移hdfs以及hbase
前言 由于项目数据安全的需要,这段时间看了下hadoop的distcp的命令使用,不断的纠结的问度娘,度娘告诉我的结果也让我很纠结,都是抄来抄去, 还好在牺牲大量的时间的基础上还终于搞出来了,顺便写这 ...
- hadoop集群间的hdfs文件拷贝
1.背景 部门有个需求,在网络互通的情况下,把现有的hadoop集群(未做Kerberos认证,集群名为:bd-stg-hadoop)的一些hdfs文件拷贝到新的hadoop集群(做了Kerberos ...
- hbase 学习(十三)集群间备份原理
集群建备份,它是master/slaves结构式的备份,由master推送,这样更容易跟踪现在备份到哪里了,况且region server是都有自己的WAL 和HLog日志,它就像mysql的主从备份 ...
- Java之JVM调优案例分析与实战(2) - 集群间同步导致的内存溢出
环境:一个基于B/S的MIS系统,硬件为两台2个CPU.8GB内存的HP小型机,服务器是WebLogic 9.2,每台机器启动了3个WebLogic实例,构成一个6个节点的亲合式集群. 说明:由于是亲 ...
- 基于uReplicator复制的kafka主备集群间的切换策略
一.概述 目前基于中间件uReplicator实现了kafka集群间的迁移复制,可以实现跨区.跨云的kafka集群间复制同步,也可以实现kafka集群的冷热互备架构:在实现集群间同步以后,需要解决一个 ...
- 配置两个不同kerberos认证中心的集群间的互信
两个Hadoop集群开启Kerberos验证后,集群间不能够相互访问,需要实现Kerberos之间的互信,使用Hadoop集群A的客户端访问Hadoop集群B的服务(实质上是使用Kerberos Re ...
- Zookeeper的基本原理(zk架构、zk存储结构、watch机制、独立安装zk、集群间同步复制)
1.Hbase集群的高可用性与伸缩性 HBase可以实现对Regionserver的监控,当个别Regionserver不可访问时,将其负责的分区分给其他Regionsever,其转移过程较快,因为只 ...
- dubbo集群容错解决方案
dubbo主要核心部件 Remoting:网络通信框架,实现了sync-over-async和request-response消息机制. RPC:一个远程过程调用的抽象,支持负载均衡.容灾和集群功能. ...
随机推荐
- Docker 安装-在centos7下安装Docker(二)
参考docker安装的方式: http://www.runoob.com/docker/centos-docker-install.html Docker中文官网安装步骤:https://docs.d ...
- 几句话说明 .NET MVC中ViewData, ViewBag和TempData的区别
ViewData和TempData是字典类型,赋值方式用字典方式, ViewData["myName"] ViewBag是动态类型,使用时直接添加属性赋值即可 ViewBag.my ...
- 第 4篇 Scrum 冲刺博客
一.站立式会议 1.站立式会议照片 2.昨天已完成的工作 登录信息的匹配 3.今天计划完成的工作 ①售货员页面功能 ②销售排行 4.工作中遇到的困难 ①页面按钮太过复杂,逻辑错乱 ②有的同学数据库驱动 ...
- 题解 CF1437G Death DBMS
这题感觉不是很难,但是既然放在 \(\texttt{EDU}\) 的 \(\texttt{G}\) 题,那么还是写写题解吧. \(\texttt{Solution}\) 首先看到 "子串&q ...
- 笔记-AHOI2013 差异
AHOI2013 差异 方法1:SA 先板个后缀数组(带 \(height\) 不带 \(st\) 表),用单调队列递推每个后缀 \(sa_i\) 对答案的贡献,求和,用定值减之. #include ...
- MySQL技术内幕InnoDB存储引擎(二)——InnoDB存储引擎
1.概述 是一个高性能.高可用.高扩展的存储引擎. 2.InnoDB体系架构 InnoDB存储引擎主要由内存池和后台线程构成. 其中,内存池由许多个内存块组成,作用如下: 维护所有进程和线程需要访问的 ...
- RocketMQ(六):nameserver队列存储定位解析
在rocketmq中,nameserver充当了一个配置管理者的角色,看起来好似不太重要.然而它是一个不或缺的角色,没有了它的存在,各个broker就是一盘散沙,各自为战. 所以,实际上,在rocke ...
- Day3 条件判断和循环
条件判断 if...else if...elif...else 格式: 注意缩进! if x: active elif y: active else : active 注 ...
- Linux端口被占用解决
有时候关闭软件后,后台进程死掉,导致端口被占用.下面以JBoss端口8083被占用为例,列出详细解决过程. 解决方法: 1.查找被占用的端口 netstat -tln netstat -tln | g ...
- [日常摸鱼]pojKaka's Matrix Travels-拆点+最大费最大流
方格取数的升级版,每个格子最多取一次. $k=1$的话就是个普及组的dp题,$k=2$就是在之前的基础上多加两维. 然而现在$k$太大了当然就不dp啦 对于$k=1$的情况我们还可以把$(i,j)$向 ...