算法-一步步教你如何用c语言实现堆排序(非递归)
看了左神的堆排序,觉得思路很清晰,比常见的递归的堆排序要更容易理解,所以自己整理了一下笔记,带大家一步步实现堆排序算法
首先介绍什么是大根堆:每一个子树的最大值都是子树的头结点,即根结点是所有结点的最大值
堆排序是基于数组和二叉树思想实现的(二叉树是脑补结构,实际是数组)
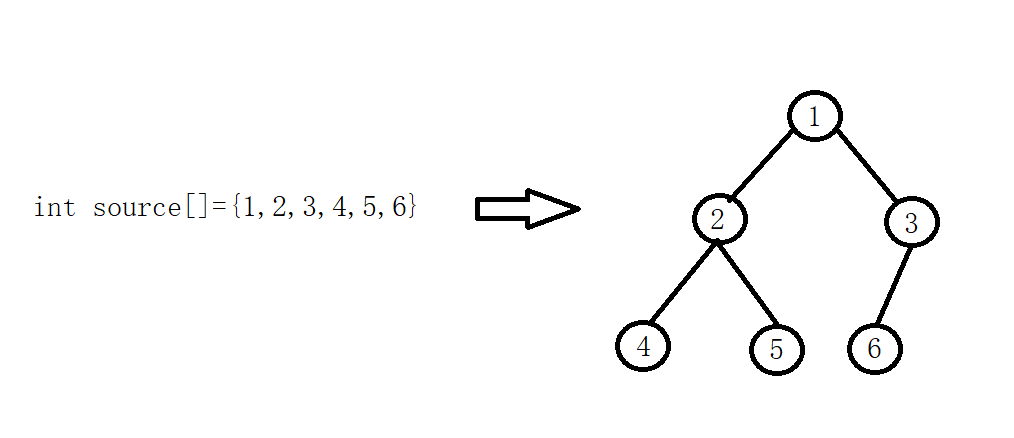
堆排序过程
1、数组建成大根堆,首先,遍历所有结点,当前结点index和父结点(index-1)/ 2 比较 (当前数组的下标是index,此结点的父结点的下标就是(index-1)/ 2 ),如果比父结点大,交换,变成父结点的位置再和上一层的父结点比较,直到满足大根堆条件
int swap(int source[], int a, int b)
{
int temp = source[a];
source[a] = source[b];
source[b] = temp;
}
int heapsort(int source[], int len)
{
for (int i = ; i <len; i++)
{
heapInsert(source, i);
}
}
int heapInsert(int source[], int index)
{
while (source[index] > source[(index - ) / ])
{
swap(source, index, (index - ) / );
index = (index - ) / ;
}
}
2、让根结点和最后一个结点交换位置,也就是数组的第一个数和最后一个数交换位置,接下来最后一个数不用考虑了,比如一个数组有5个数,定义一个变量size=5,大根堆的根结点放到最后一个数后,--size
int size = len;
swap(source, , --size);
3、让交换后的头结点经历一个向下的调整,让结点和自己的两个孩子比较,如果孩子的值比头结点大,交换,交换到孩子结点位置,继续和下面的两个孩子比较,直到满足大根堆条件
int heapify(int source[], int index, int size)//index表示要和它两个孩子比较的结点
{
int left = index * + ; //找到index左孩子结点的数组下标
while (left < size)
{
int largest = left + < size && source[left + ] > source[left] ? source[left + ] : source[left];//如果有右孩子且右孩子比左孩子大,令largest=右孩子的值,也就是把两个孩子中最大的一个数赋给largest
if (source[index] < source[largest])
{
swap(source, index, largest);
index = largest;
left = index * + ;
}
else break;
} }
4、重复第2步,第3步,直到size = 0 ,整个数组排序过程结束
while (size > )
{
swap(source, , --size);
heapify(source, , size);
}
源代码如下
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int swap(int source[], int a, int b)
{
int temp = source[a];
source[a] = source[b];
source[b] = temp;
}
int heapsort(int source[], int len)
{
for (int i = ; i < len; i++)
{
heapInsert(source, i);
}
int size = len;
while (size > )
{
swap(source, , --size);
heapify(source, , size);
}
}
int heapInsert(int source[], int index)
{
while (source[index] > source[(index - ) / ])
{
swap(source, index, (index - ) / );
index = (index - ) / ;
}
}
int heapify(int source[], int index, int size)//index表示要和它两个孩子比较的结点
{
int left = index * + ; //找到index左孩子结点的数组下标
while (left < size)
{
int largest = left + < size && source[left + ] > source[left] ? left + : left;//如果有右孩子且右孩子比左孩子大,令largest=右孩子的值,也就是把两个孩子中最大的一个数赋给largest
if (source[index] < source[largest])
{
swap(source, index, largest);
index = largest;
left = index * + ;
}
else break;
} }
int main()
{
int source[] = { ,,,,,,,,,,,,,,,,, };
int len;
len = sizeof(source) / sizeof(int);
heapsort(source, len);
for (int i = ; i < len; i++)
{
printf("%d ", source[i]);
} }
输出结果

以上就是堆排序的所有细节,这个版本很优良,堆排序的额外空间复杂度是O(1),如果用递归的话,递归有递归栈,额外空间复杂度不就上去了吗,设计成这种迭代的可以省空间,时间复杂度为O(n log n)
转载请注明出处、作者 谢谢
算法-一步步教你如何用c语言实现堆排序(非递归)的更多相关文章
- 自己写算法---java的堆的非递归遍历
import java.io.*; import java.util.*; public class Main { public static void main(String args[]) { S ...
- 一步步教你轻松学奇异值分解SVD降维算法
一步步教你轻松学奇异值分解SVD降维算法 (白宁超 2018年10月24日09:04:56 ) 摘要:奇异值分解(singular value decomposition)是线性代数中一种重要的矩阵分 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
- 一步步教你轻松学关联规则Apriori算法
一步步教你轻松学关联规则Apriori算法 (白宁超 2018年10月22日09:51:05) 摘要:先验算法(Apriori Algorithm)是关联规则学习的经典算法之一,常常应用在商业等诸多领 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- 一步步教你轻松学朴素贝叶斯模型算法Sklearn深度篇3
一步步教你轻松学朴素贝叶斯深度篇3(白宁超 2018年9月4日14:18:14) 导读:朴素贝叶斯模型是机器学习常用的模型算法之一,其在文本分类方面简单易行,且取得不错的分类效果.所以很受欢迎,对 ...
- 一步步教你轻松学KNN模型算法
一步步教你轻松学KNN模型算法( 白宁超 2018年7月24日08:52:16 ) 导读:机器学习算法中KNN属于比较简单的典型算法,既可以做聚类又可以做分类使用.本文通过一个模拟的实际案例进行讲解. ...
随机推荐
- 13 CSS样式权重问题
<!-- 权重问题整体说明: 1.权重的意义:判定CSS属性的优先级高低,也就是说判定那个CSS的属性优先显示,将其他的低优先级的CSS样式覆盖掉. 2.如何判断权重:数选择器的数量,按照Id选 ...
- git的基本指令
更多详情请看廖雪峰官方网站 http://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000 1.删 ...
- GRPC Oauth Identity
gRPC中集成asp.net identity实现oAuth认证 在asp.net core 3.0中开启identity认证 asp.net core 3.0种需要导入的identity包与core ...
- kali Linux渗透测试技术详解
kali Linux渗透测试技术详解 下载:https://pan.baidu.com/s/1g7dTFfzFRtPDmMiEsrZDkQ 提取码:p23d <Kali Linux渗透测试技术详 ...
- mysql计算日期之间相差的天数
TO_DAYS(NOW()) - TO_DAYS(createTime) as dayFactor,
- ORACLE导入数据库详细步骤
登录PLSQL 点击然后打开命令窗口执行命令 创建表空间(红色字体是你需要创建表空间的地址,蓝色的是表空间大小) create temporary tablespace ZJY_TEMP tempfi ...
- 利用consul在spring boot中实现最简单的分布式锁
因为在项目实际过程中所采用的是微服务架构,考虑到承载量基本每个相同业务的服务都是多节点部署,所以针对某些资源的访问就不得不用到用到分布式锁了. 这里列举一个最简单的场景,假如有一个智能售货机,由于机器 ...
- css单位中px和em,rem的区别
css单位中分为相对长度单位.绝对长度单位. 今天我们主要讲解rem.em.px这些常用单位的区别和用法. px(绝对长度单位) 相信对于前端来说px这个单位是大家并不陌生,px这个单位,兼容性可以说 ...
- 论文阅读 <Relocalization, Global Optimization and Map Merging for Monocular Visual-Inertial SLAM>
看了一下港科的基于vins拓展的论文<relocalization, global optimization and merging for vins>,在回环的实现部分总体没有什么变化, ...
- springcloud-路由Zull
1. 场景描述 今天接着介绍springcloud,今天介绍下springcloud的路由网关-Zull,外围系统或者用户通过网关访问服务,网关通过注册中心找到对应提供服务的客户端,网关也需要到注册中 ...