Python抓取豆瓣电影top250!
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:404notfound 
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧。当然如果你学的不好,建议可以先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目,一起交流学习进步!
实现目标:抓取豆瓣电影top250,并输出到文件中
1.找到对应的url:https://movie.douban.com/top250
2.进行页面元素的抓取:
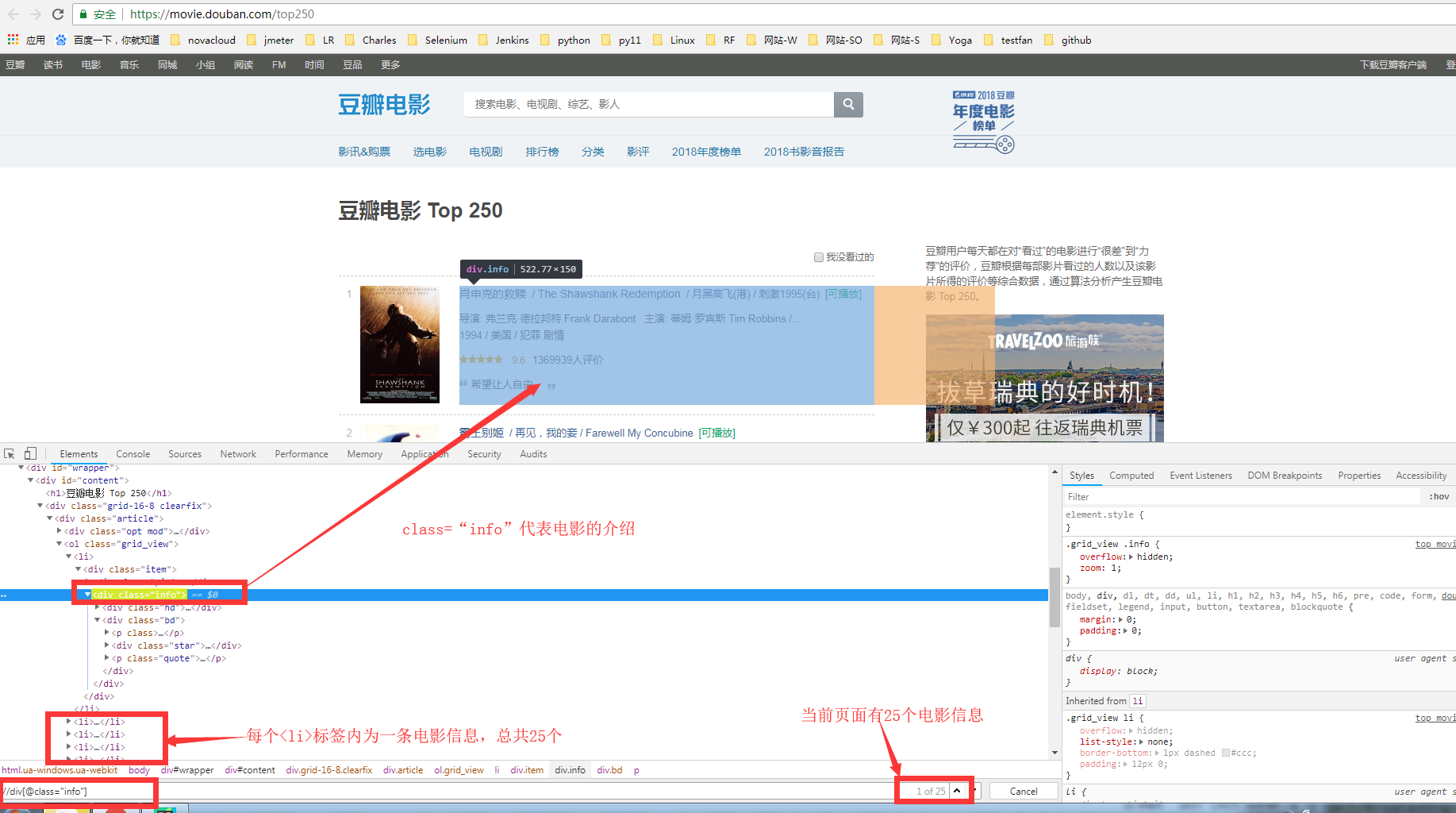
3.编写代码:
第一步:实现抓取第一个页面;
第二步:将其他页面的信息也抓取到;
第三步:输出到文件;
4.代码:
import sys
import io
from selenium import webdriver #改变标准输出,解决输出到文件时遇到的编码问题。
# 如果输出到控制行,不要加这一行
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') class DouBan:
#初始化driver对象,打开页面,最大化页面
def __init__(self):
self.driver=webdriver.Chrome()
self.driver.get('https://movie.douban.com/top250')
self.driver.maximize_window() # 分页判断,默认显示第一页,输出第一页后,点击下一页按钮,再输出。总共10页
def get_content(self):
for page in range(1,10):
#获取元素定位: 对当前页面中 单个电影元素进行定位
movie = self.driver.find_elements_by_class_name('info') # for循环:循环输出当前页面中单部影片的电影信息(text输出元素的文本内容);
i = 1
for item in movie:
#输出格式: 电影序号 + 电影介绍 +换行展示
print(str(i+ page*25-25)+": "+item.text+'')
print("")
i+=1 # 判断:如果当前页面码小于10,则查找页码的元素,并点击页码。否则不用进行查找,因为最多点击第10页;
# 获取底部的页签元素(采用了format格式输出,根据当前页面做加1操作)
if page<10:
page_but = self.driver.find_element_by_xpath('//div[@class="paginator"]//a[contains(text(),{0})]'.format(page + 1))
page_but.click()
else:
pass if __name__ == '__main__':
DouBan().get_content()
5.结果:
1)控制台输出部分截图:

2)如果想要输出到文件,执行命令并重定向到TXT文件中:
python xxxx.py >d:/out_test.txt
6.遇到的问题:
1.多页时,for循环的数字设置,来回试几次就可以了,不难。
2.输出到文件中

真的很简单,不知道你们都懂了没? 如果没懂可以去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目,一起交流学习进步!有问题留言问我吧~
Python抓取豆瓣电影top250!的更多相关文章
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- python2.7抓取豆瓣电影top250
利用python2.7抓取豆瓣电影top250 1.任务说明 抓取top100电影名称 依次打印输出 2.网页解析 要进行网络爬虫,利用工具(如浏览器)查看网页HTML文件的相关内容是很有必要,我使用 ...
- Python3 抓取豆瓣电影Top250
利用 requests 抓取豆瓣电影 Top 250: import re import requests def main(url): global num headers = {"Use ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- Python 爬取豆瓣电影Top250排行榜,爬虫初试
from bs4 import BeautifulSoup import openpyxl import re import urllib.request import urllib.error # ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
随机推荐
- tomcat 日志(2)
一.Log4j在Tomcat中的配置说明(tomcat6) 学习Java中,从简单的开始.如果需要文中提到的文件可以找我要. http://www.apache.org/dist/tomcat/tom ...
- EXISTS的用法介绍
比如在Northwind数据库中有一个查询为 SELECT c.CustomerId,CompanyName FROM Customers c WHERE EXISTS( SELECT OrderID ...
- spark集群搭建(三台虚拟机)——hadoop集群搭建(2)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- Python 常用模块系列学习(1)--random模块常用function总结--简单应用--验证码生成
random模块--random是一个生成器 首先: import random #导入模块 print (help(random)) #打印random模块帮助信息 常用function ...
- lqb 基础练习 查找整数 (遍历)
基础练习 查找整数 时间限制:1.0s 内存限制:256.0MB 问题描述 给出一个包含n个整数的数列,问整数a在数列中的第一次出现是第几个. 输入格式 第一行包含一个整数n. 第二行包含 ...
- ArcGIS API For Javascript :双屏(多屏)地图联动的方法
在遇到地图对比的应用场景下,我们需要双屏地图或者多屏地图来满足我们的业务需求. 解决思路:首先生成两份(多份)地图,然后通过监听地图缩放拖拽,用地图四至将不同的地图对象做绑定,实现多地图联动. 前端部 ...
- 力扣(LeetCode)第一个错误的版本 个人题解
你是产品经理,目前正在带领一个团队开发新的产品.不幸的是,你的产品的最新版本没有通过质量检测.由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的. 假设你有 n 个版本 [1, ...
- wait()、notify、notifyAll()的使用
wait().notify.notifyAll()的使用 参考:https://www.jianshu.com/p/25e243850bd2?appinstall=0 一).java 中对象锁的模型 ...
- Redshitf Install
创建VPC 和 子网和internet网关(子网需开启自动分配公网IP,VPN 需添加到internet网关的路由) 创建安全组: 创建cluster subnet Group; 创建redshift ...
- [FPGA]Verilog实现寄存器LS374
目录 想说的话... 正文 IC介绍 电路连接图 功能表 逻辑图 实验原理 单元实现_D触发器 整体实现(完整代码) 想说的话... 不久前正式开通了博客,以后有空了会尽量把自己学习过程中的心得或者感 ...