模型量化原理及tflite示例
模型量化
什么是量化
模型的weights数据一般是float32的,量化即将他们转换为int8的。当然其实量化有很多种,主流是int8/fp16量化,其他的还有比如
- 二进制神经网络:在运行时具有二进制权重和激活的神经网络,以及在训练时计算参数的梯度。
- 三元权重网络:权重约束为+1,0和-1的神经网络
- XNOR网络:过滤器和卷积层的输入是二进制的。 XNOR 网络主要使用二进制运算来近似卷积。
现在很多框架或者工具比如nvidia的TensorRT,xilinx的DNNDK,TensorFlow,PyTorch,MxNet 等等都有量化的功能.
量化的优缺点
量化的优点很明显了,int8占用内存更少,运算更快,量化后的模型可以更好地跑在低功耗嵌入式设备上。以应用到手机端,自动驾驶等等。
缺点自然也很明显,量化后的模型损失了精度。造成模型准确率下降.
量化的原理
先来看一下计算机如何存储浮点数与定点数:
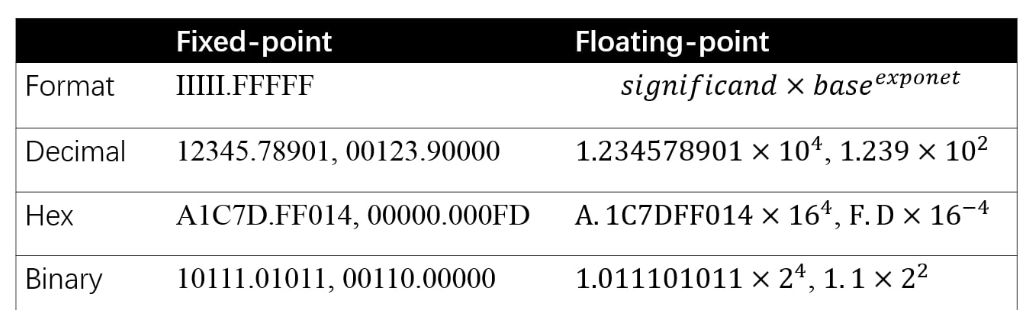
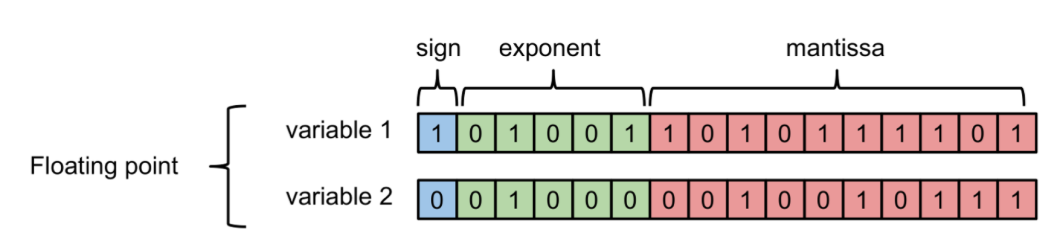
其中负指数决定了浮点数所能表达的绝对值最小的非零数;而正指数决定了浮点数所能表达的绝对值最大的数,也即决定了浮点数的取值范围。
float的范围为-2^128 ~ +2^128. 可以看到float的值域分布是极其广的。
说回量化的本质是:找到一个映射关系,使得float32与int8能够一一对应。那问题来了,float32能够表达值域是非常广的,而int8只能表达[0,255].
怎么能够用255个数代表无限多(其实也不是无限多,很多,但是也还是有限个)的浮点数?
幸运地是,实践证明,神经网络的weights往往是集中在一个非常狭窄的范围,如下:
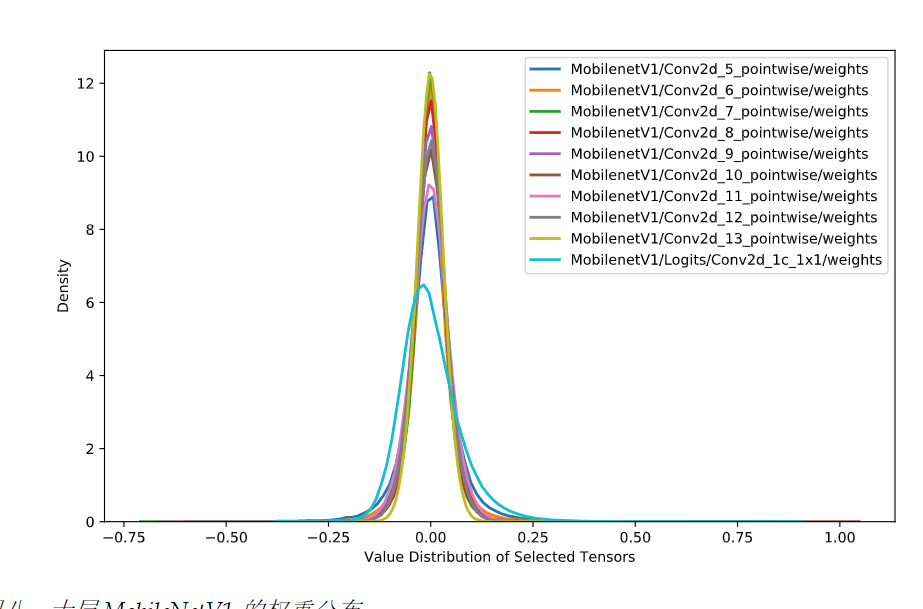
所以这个问题解决了,即我们并不需要对值域-2^128 ~ +2^128的所有值都做映射。但即便是一个很小的范围,比如[-1,1]能够表达的浮点数也是非常多的,所以势必
会有多个浮点数被映射成同一个int8整数.从而造成精度的丢失.
这时候,第二个问题来了,为什么量化是有效的,为什么weights变为int8后,并不会让模型的精度下降太多?
在搜索了大量的资料以后,我发现目前并没有一个很严谨的理论解释这个事情.
您可能会问为什么量化是有效的(具有足够好的预测准确度),尤其是将 FP32 转换为 INT8 时已经丢失了信息?严格来说,目前尚未出现相关的严谨的理论。一个直觉解释是,神经网络被过度参数化,进而包含足够的冗余信息,裁剪这些冗余信息不会导致明显的准确度下降。相关证据是,对于给定的量化方法,FP32 网络和 INT8 网络之间的准确度差距对于大型网络来说较小,因为大型网络过度参数化的程度更高
和深度学习模型一样,很多时候,我们无法解释为什么有的参数就是能work,量化也是一样,实践证明,量化损失的精度不会太多,do not know why it works,it just works.
如何做量化
由以下公式完成float和int8之间的相互映射.
\(x_{float} = x_{scale} \times (x_{quantized} - x_{zero\_point})\)
其中参数由以下公式确定:

举个例子,假设原始fp32模型的weights分布在[-1.0,1.0],要映射到[0,255],则\(x_{scale}=2/255\),\(x_{zero\_point}=255-1/(2/255)=127\)
量化后的乘法和加法:
依旧以上述例子为例:
我们可以得到0.0:127,1.0:255的映射关系.
那么原先的0.0 X 1.0 = 0.0 注意:并非用127x255再用公式转回为float,这样算得到的float=(2/255)x(127x255-127)=253

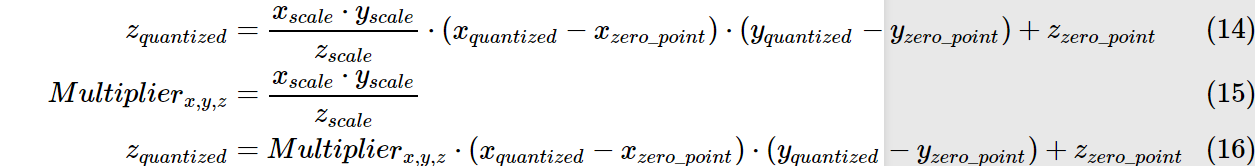
我们假设所有layer的数据分布都是一致的.则根据上述公式可得\(z_{quantized}=127\),再将其转换回float32,即0.0.
同理加法:

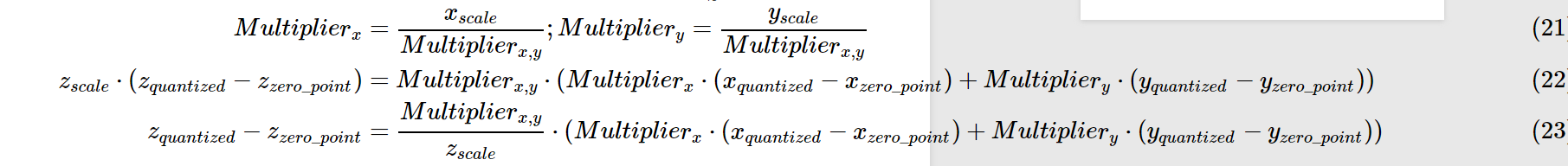
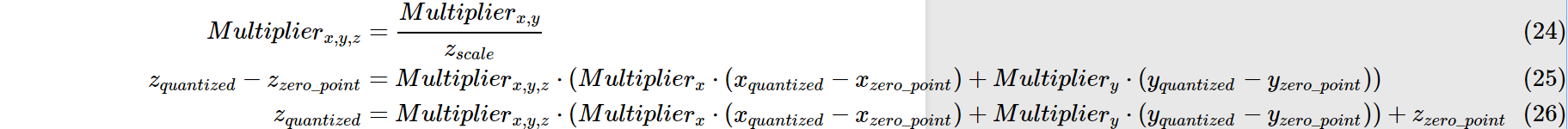
tflite_convert
日常吐槽:tensorflow sucks. tensorflow要不是大公司开发的,绝对不可能这么流行. 文档混乱,又多又杂,api难理解难使用.
tensorflow中使用tflite_convert做模型量化.用法:
tflite_convert \
--output_file=/tmp/foo.cc \
--graph_def_file=/tmp/mobilenet_v1_0.50_128/frozen_graph.pb \
--inference_type=QUANTIZED_UINT8 \
--input_arrays=input \
--output_arrays=MobilenetV1/Predictions/Reshape_1 \
--default_ranges_min=0 \
--default_ranges_max=6 \
--mean_values=128 \
--std_dev_values=127
官方指导:https://www.tensorflow.org/lite/convert/cmdline_examples
关于各参数的说明参见:
https://www.tensorflow.org/lite/convert/cmdline_reference
关于参数mean_values,std_dev_values比较让人困惑.tf的文档里,对这个参数的描述有3种形式.
- (mean, std_dev)
- (zero_point, scale)
- (min,max)
转换关系如下:
std_dev = 1.0 / scale
mean = zero_point
mean = 255.0*min / (min - max)
std_dev = 255.0 / (max - min)
结论:
训练时模型的输入tensor的值在不同范围时,对应的mean_values,std_dev_values分别如下:
- range (0,255) then mean = 0, std_dev = 1
- range (-1,1) then mean = 127.5, std_dev = 127.5
- range (0,1) then mean = 0, std_dev = 255
参考:
https://heartbeat.fritz.ai/8-bit-quantization-and-tensorflow-lite-speeding-up-mobile-inference-with-low-precision-a882dfcafbbd
https://stackoverflow.com/questions/54830869/understanding-tf-contrib-lite-tfliteconverter-quantization-parameters/58096430#58096430
https://arleyzhang.github.io/articles/923e2c40/
https://zhuanlan.zhihu.com/p/79744430
https://zhuanlan.zhihu.com/p/58182172
模型量化原理及tflite示例的更多相关文章
- Optaplanner规划引擎的工作原理及简单示例(2)
开篇 在前面一篇关于规划引擎Optapalnner的文章里(Optaplanner规划引擎的工作原理及简单示例(1)),老农介绍了应用Optaplanner过程中需要掌握的一些基本概念,这些概念有且于 ...
- tensorflow模型量化实例
1,概述 模型量化应该是现在最容易实现的模型压缩技术,而且也基本上是在移动端部署的模型的毕竟之路.模型量化基本可以分为两种:post training quantizated和quantization ...
- deeplearning模型量化实战
deeplearning模型量化实战 MegEngine 提供从训练到部署完整的量化支持,包括量化感知训练以及训练后量化,凭借"训练推理一体"的特性,MegEngine更能保证量化 ...
- 大数据运算模型 MapReduce 原理
大数据运算模型 MapReduce 原理 2016-01-24 杜亦舒 MapReduce 是一个大数据集合的并行运算模型,由google提出,现在流行的hadoop中也使用了MapReduce作为计 ...
- tensorflow模型量化
tensorflow模型量化/DATA/share/DeepLearning/code/tensorflow/bazel-bin/tensorflow/tools/graph_transforms/t ...
- Python进阶(十六)----面向对象之~封装,多态,鸭子模型,super原理(单继承原理,多继承原理)
Python进阶(十六)----面向对象之~封装,多态,鸭子模型,super原理(单继承原理,多继承原理) 一丶封装 , 多态 封装: 将一些东西封装到一个地方,你还可以取出来( ...
- CUDA上深度学习模型量化的自动化优化
CUDA上深度学习模型量化的自动化优化 深度学习已成功应用于各种任务.在诸如自动驾驶汽车推理之类的实时场景中,模型的推理速度至关重要.网络量化是加速深度学习模型的有效方法.在量化模型中,数据和模型参数 ...
- Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算.这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少: 可以更快 ...
- TensorFlow 8 bit模型量化
本文基本参考自这篇文章:8-Bit Quantization and TensorFlow Lite: Speeding up mobile inference with low precision ...
随机推荐
- (day29) 进程互斥锁 + 线程
目录 进程互斥锁 队列和堆栈 进程间通信(IPC) 生产者和消费者模型 线程 什么是线程 为什么使用线程 怎么开启线程 线程对象的属性 线程互斥锁 进程互斥锁 进程间数据不共享,但是共享同一套文件系统 ...
- Vue实例与模板语法
VUE基础使用方法 一.安装 1.NPM 在用 Vue 构建大型应用时推荐使用 NPM 安装[1].NPM 能很好地和诸如 webpack 或 Browserify 模块打包器配合使用.同时 Vue ...
- CSS3 变形、过渡、动画、关联属性浅析
一.变形 transform:可以对元素对象进行旋转rotate.缩放scale.移动translate.倾斜skew.矩阵变形matrix.示例: transform: rotate(90deg) ...
- opacity层叠问题
使用了position属性值为 absolute.relative 的层,将会比普通层更高层次.使用了小于1的opacity属性的层,也比普通层更高层次并且和指定 position 的层同层,但是不支 ...
- Apache Tomcat 远程代码执行漏洞(CVE-2019-0232)漏洞复现
Apache Tomcat 远程代码执行漏洞(CVE-2019-0232)漏洞复现 一. 漏洞简介 漏洞编号和级别 CVE编号:CVE-2019-0232,危险级别:高危,CVSS分值:官方 ...
- RocketMQ实战:生产环境中,autoCreateTopicEnable为什么不能设置为true
1.现象 很多网友会问,为什么明明集群中有多台Broker服务器,autoCreateTopicEnable设置为true,表示开启Topic自动创建,但新创建的Topic的路由信息只包含在其中一台B ...
- CSPS Oct目标
超过skyh 删了一些sb话,不过目标不会变的
- NOIP 模拟赛 23 T4 大逃亡O(二分+广搜)(∩_∩)O
题目描述 给出数字N(1≤N≤10000),X(1≤x≤1000),Y(1≤Y≤1000),代表有N个敌人分布一个X行Y列的矩阵上,矩形的行号从0到X-1,列号从0到Y-1再给出四个数字x1,y1,x ...
- 009-2010网络最热的 嵌入式学习|ARM|Linux|wince|ucos|经典资料与实例分析
前段时间做了一个关于ARM9 2440资料的汇总帖,很高兴看到21ic和CSDN等论坛朋友们的支持和鼓励.当年学单片机的时候datasheet和学习资料基本都是在论坛上找到的,也遇到很多好心的高手朋友 ...
- 006.Kubernetes二进制部署ETCD
一 部署ETCD集群 1.1 安装ETCD etcd 是基于 Raft 的分布式 key-value 存储系统,由 CoreOS 开发,常用于服务发现.共享配置以及并发控制(如 leader 选举.分 ...