第六篇 xpath的用法



使用pycharm debug调试效率会比较慢,因为每次调试都需要向url发送请求,等返回信息,scrapy提供一种方便调试的功能,如下:
>>>(third_project) bigni@bigni:pachong$ scrapy shell http://blog.jobbole.com/112239/
>>> title = response.xpath('//*[@id="post-112239"]/div[1]/h1')
>>> title
[<Selector xpath='//*[@id="post-112239"]/div[1]/h1' data='<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>'>]
>>> title.extract()
['<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>']
>>> title = response.xpath('//*[@id="post-112239"]/div[1]/h1/text()')
>>> title
[<Selector xpath='//*[@id="post-112239"]/div[1]/h1/text()' data='谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征'>]
extract()方法可以取到select list里的date,text()方法可以取到内容。
In []: title2 = response.xpath("//*[@id='post-112239']/div[1]/h1").extract()
In []: title2
Out[]: ['<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>']
In []: title2 = response.xpath("//*[@id='post-112239']/div[1]/h1")
In []: title2
Out[]: [<Selector xpath="//*[@id='post-112239']/div[1]/h1" data='<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>'>]
In []: title2 = response.xpath("//*[@id='post-112239']/div[1]/h1/text()").extr
...: act()
In []: title2
Out[]: ['谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征']
In []:
PS:在chrome里,按F12看到的代码是加载完所有插件后的,比如JS,如果通过通过根路径来定位要找的内容是容易出错的,因为xpath搜索的不会把js等生成的元素计算在内,这个可以通过鼠标右键查看源码来判断哪些是js生成的,然后过滤掉。
对于属性里有多个值的情况,比如class 里有多个值:

可以使用scrapy内置的contains方法:
In []: ret = response.xpath("//div[contains(@class,'post-112239')]")
In []: ret
Out[]: [<Selector xpath="//div[contains(@class,'post-112239')]" data='<div class="post-112239 post type-post s'>]
如果要爬取下面这个内容,可以这么操作:
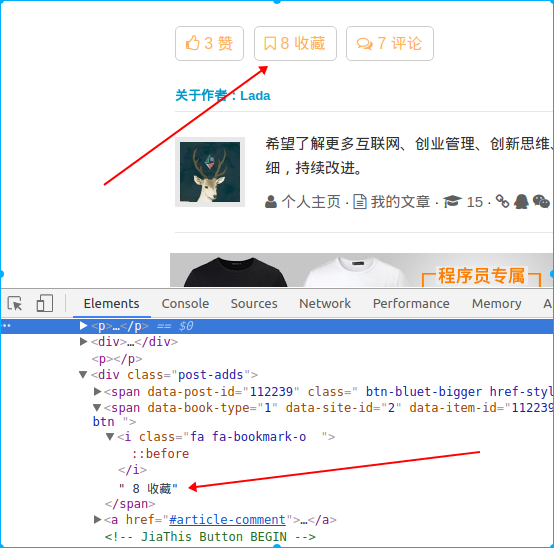
In []: rest = response.xpath('//*[@id="post-112239"]/div[3]/div[4]/span[2]/tex
...: t()').extract()[0]
In []: rest
Out[]: ' 8 收藏'
接着再用正则去掉别的信息,由于在scrapy shell中直接调用re模块会报错,那可以用ipython调试
In []: ret = re.match(r".*(\d+).*",' 8 收藏') In []: ret.group()
Out[]: ''
第六篇 xpath的用法的更多相关文章
- [老老实实学WCF] 第六篇 元数据交换
老老实实学WCF 第六篇 元数据交换 通过前两篇的学习,我们了解了WCF通信的一些基本原理,我们知道,WCF服务端和客户端通过共享元数据(包括服务协定.服务器终结点信息)在两个 终结点上建立通道从而进 ...
- Python爬虫利器六之PyQuery的用法
前言 你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有 ...
- (数据科学学习手札61)xpath进阶用法
一.简介 xpath作为对网页.对xml文件进行定位的工具,速度快,语法简洁明了,在网络爬虫解析内容的过程中起到很大的作用,除了xpath的基础用法之外(可参考我之前写的(数据科学学习手札50)基于P ...
- 解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译) http://improve.dk/orcamdf-rawdatabase-a-swiss-a ...
- 解剖SQLSERVER 第六篇 对OrcaMDF的系统测试里避免regressions(译)
解剖SQLSERVER 第六篇 对OrcaMDF的系统测试里避免regressions (译) http://improve.dk/avoiding-regressions-in-orcamdf-b ...
- Python之路【第十六篇】:Django【基础篇】
Python之路[第十六篇]:Django[基础篇] Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了O ...
- 第六篇 :微信公众平台开发实战Java版之如何自定义微信公众号菜单
我们来了解一下 自定义菜单创建接口: http请求方式:POST(请使用https协议) https://api.weixin.qq.com/cgi-bin/menu/create?access_to ...
- RabbitMQ学习总结 第六篇:Topic类型的exchange
目录 RabbitMQ学习总结 第一篇:理论篇 RabbitMQ学习总结 第二篇:快速入门HelloWorld RabbitMQ学习总结 第三篇:工作队列Work Queue RabbitMQ学习总结 ...
- 第六篇 Replication:合并复制-发布
本篇文章是SQL Server Replication系列的第六篇,详细内容请参考原文. 合并复制,类似于事务复制,包括一个发布服务器,一个分发服务器和一个或多个订阅服务器.每一个发布服务器上可以定义 ...
随机推荐
- python学习笔记:网络请求——urllib模块
python操作网络,也就是打开一个网站,或者请求一个http接口,可以使用urllib模块.urllib模块是一个标准模块,直接import urllib即可,在python3里面只有urllib模 ...
- CMS 开发全过程介绍
1.Web项目开发的一般流程 a) 需求确定 b) 需求分析 i. 架构分析和设计 ii. 业务逻辑分析和设计 iii. 界面设计 iv. 数据库的设计 c) 开发环境搭建 d) 开发和测试 e) 文 ...
- AWS使用教程
AWS使用教程 一.注册登录(https://portal.aws.amazon.com/billing/signup) 准备资料:信用卡(visa卡).电子邮箱.手机号 1.填写账号名和密码 2.填 ...
- js实现页面跳转的几种方法小结
地址:https://www.jb51.net/article/84335.htm 地址:https://blog.csdn.net/tsoteo/article/details/77849403
- mysql架构精选
◆主从架构1.安装服务(主从) yum -y install mysql* /etc/init.d/mysqld start2.修改配置文件:/etc/my.conf(主从) vi /etc/my.c ...
- ionic2(3) 密码键盘组件 ionic2-pincode-input 使用
1.效果展示: 2.安装: npm install ionic2-pincode-input --save 3.app.module.ts配置 app.module.ts import { NgMod ...
- word2vec 原理浅析 及高效训练方法
1. https://www.cnblogs.com/cymx66688/p/11185824.html (word2vec中的CBOW 和skip-gram 模型 浅析) 2. https://ww ...
- MYSQL增量备份与恢复
vim /etc/my.cnf在[mysqld]下添加max_binlog_size = 1024000 //二进制日志最大1M 要进行mysql的增量备份,首先要开启二进制日志功能方法一:在/etc ...
- mongoose 常用数据库操作 插入
项目 db.js var mongoose = require('mongoose'); mongoose.connect('mongodb://127.0.0.1:27017/whhhh', { u ...
- 【leetcode】667. Beautiful Arrangement II
题目如下: Given two integers n and k, you need to construct a list which contains ndifferent positive in ...