Python3.6爬虫+Djiago2.0+Mysql --数据爬取
1.下载对应版本的python mysql 模块 我的是:pymssql-2.2.0.dev0-cp36-cp36m-win_amd64.whl
2.手动创建table
create table grilsbase
(
id int primary key auto_increment,
name varchar(50),height varchar(50),bwh varchar(50),title varchar(100),img_upload varchar(100),pc_img_upload varchar(100),
resource_id varchar(50),totals varchar(50),recommend_id varchar(50),date varchar(50),headimg_upload varchar(50),
show_datetime varchar(50),client_show_datetime varchar(50),video_duration varchar(50),free_select varchar(50),
trial_time varchar(50),viewtimes varchar(50),coop_customselect_654 varchar(50),coop_id varchar(50),tag_class varchar(50),
tag_name varchar(50),playerid varchar(50),block_detailid varchar(50),type varchar(50),istop varchar(50)
)
3.实现爬虫代码
导入模块:requests ,os,json,re,Mysqldb
流程:获取数据=>分析数据=>解析数据=>持久化保存
#coding:utf-8
import requests
import os
import json
import re
import MySQLdb
import threading
#获取数据url
gilsUrl='http://act.vip.xunlei.com/ugirls/js/ugirlsdata.js'
gilsDetailUrl='http://meitu.xunlei.com/detail.html'
gilsImgUrl='http://data.meitu.xunlei.com/data/image/%s/%s'
executor = threading.BoundedSemaphore(10)
regex=re.compile('\/([^\/]*?\.jpg)$')
regexhead=re.compile('\/([^\/]*?)\.jpg$')
class MySQL:
def __init__(self,host,user,pwd,db):
self.host=host
self.user=user
self.db=db
self.pwd=pwd
def GetConnect(self):
if not self.db:
raise(NameError,'没有目标数据库')
self.connect=MySQLdb.connect(host=self.host,user=self.user,password=self.pwd,database=self.db,port=3306,charset='utf8')
cur=self.connect.cursor()
if not cur:
raise(NameError,'数据库访问失败')
else:
return cur
def ExecSql(self,sql):
cur=self.GetConnect()
cur.execute(sql)
self.connect.commit()
self.connect.close()
def ExecQuery(self,sql):
cur=self.GetConnect()
cur.execute(sql)
resList = cur.fetchall()
self.connect.close()
return resList def getGirlsData():
regex=re.compile("var ugirlsData=(.+)")
r=requests.get(gilsUrl)
jsond=regex.findall(r.text)
with open('ugirlsdata.json','w+',encoding='utf-8') as f:
f.write(jsond[0])
#print('写入json成功')
return json.loads(jsond[0]) def getImgName(imgurl):
if(imgurl==''):
return ''
m=regex.findall(imgurl)
if m is None:
return ''
else:
return m[0] if len(m)>0 else '' def getImgNameHead(imgurl):
if(imgurl==''):
return ''
m=regexhead.findall(imgurl)
if m is None:
return ''
else:
return m[0] if len(m)>0 else '' def WriteDB(jsdata):
ms = MySQL(host="192.168.0.108", user="lin", pwd="", db="grils")
for data in jsdata:
sql="insert into grilsbase(\
name,height,bwh,title,img_upload,pc_img_upload,resource_id,totals,recommend_id,\
date,headimg_upload,show_datetime,client_show_datetime,video_duration,free_select,trial_time,\
viewtimes,coop_customselect_654,coop_id,tag_class,tag_name,playerid,block_detailid,type,istop)\
values('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" % \
(data['name'],data['height'],data['bwh'],data['title'],getImgName(data.get('img_upload','')),data['pc_img_upload'],data['resource_id'],data["totals"],data["recommend_id"], \
data['date'],getImgName(data.get("headimg_upload",'')),data["show_datetime"],data["client_show_datetime"],data["video_duration"],data["free_select"],data["trial_time"], \
data['viewtimes'],data['coop_customselect_654'],data['coop_id'],data.get('tag_class',''),data.get('tag_name',''),data.get('playerid',''),data['block_detailid'],data['type'],data['istop'])
#print(sql)
ms.ExecSql(sql)
print('完成'+data['name']+'数据更新...')
DownImg(data['name'],data["totals"],data['resource_id'],data["headimg_upload"],data["img_upload"]) def DownImg(name,totals,resource_id,headimg_upload,img_upload):
path=creatFile(resource_id)
if headimg_upload.strip()!='':
#os.remove('./pic/'+resource_id+'/'+getImgName(headimg_upload)+'.jpg')
DownImgRun(headimg_upload,path,getImgNameHead(headimg_upload))
if img_upload.strip()!='':
#os.remove('./pic/'+resource_id+'/'+getImgName(img_upload)+'.jpg')
DownImgRun(img_upload,path,getImgNameHead(img_upload))
#print('正在下载'+name+'图片') for i in range(1,int(totals)+1):
url=gilsImgUrl%(resource_id,str(i)+'.jpg')
DownImgRun(url,path,i)
#t=threading.Thread(target=DownImgRun,args={url,path,i})
#t.start()
#t.join() def DownImgRun(url,path,i):
#print(url) r=requests.get(url)
if(r.status_code==200):
with open(path+'/'+str(i)+'.jpg','wb') as fimg:
fimg.write(r.content) def creatFile(dirname):
path='./pic/'+dirname
if os.path.exists(path):
return path
else:
os.makedirs(path)
return path if __name__ == '__main__':
gri=getGirlsData()
WriteDB(gri)
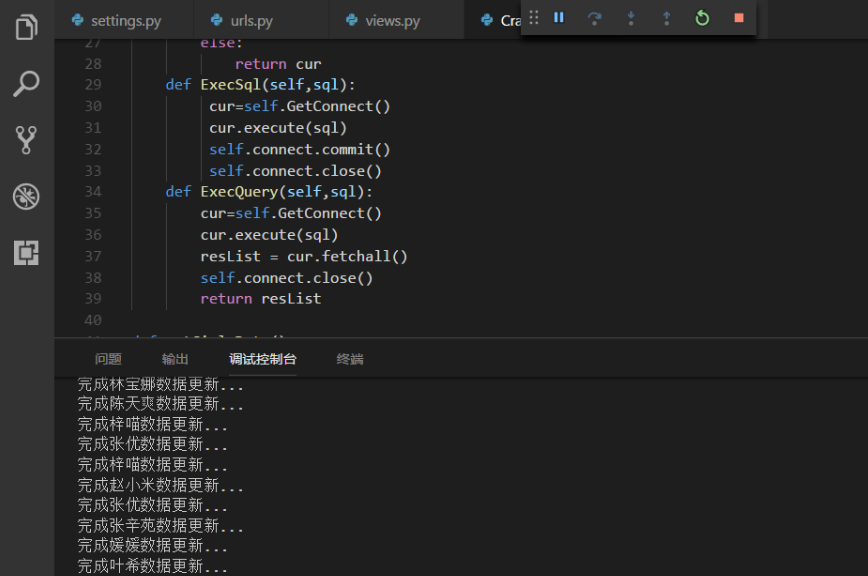
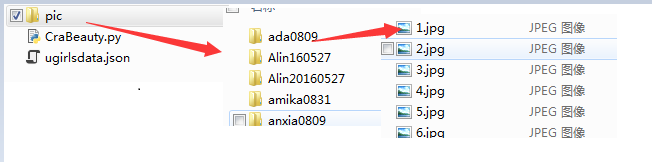
4.运行效果 和结果

Python3.6爬虫+Djiago2.0+Mysql --数据爬取的更多相关文章
- sulin Python3.6爬虫+Djiago2.0+Mysql --实例demo
1.切换到项目目录下,启动测试服务器 manage.py runserver 192.168.0.108:8888 2.设置相关配置 项目目录展示如下: beauty=>settings.py ...
- Python3.6爬虫+Djiago2.0+Mysql --运行djiago环境
1.安装djiago 模块 pip install Django --默认安装最新的 安装完成以后可以python -m pip list 查看模块是否安装 2.创建项目及app 及生成目录 备注 ...
- [Python3网络爬虫开发实战] 6-Ajax数据爬取
有时候我们在用requests抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但是使用requests得到的结果并没有.这是因为requests获取的都是 ...
- python爬虫-上期所持仓排名数据爬取
摘要:笔记记录爬取上期所持仓数据的过程,本次爬取使用的工具是python,使用的IDE是pycharm 一.查看网页属性,分析数据结构 在浏览器中打开上期所网页,按F12或者选择表格文字-右键-审查元 ...
- 前端反爬虫策略--font-face 猫眼数据爬取
1 .font-face定义了字符集,通过unicode去印射展示. 2 .font-face加载网络字体,我么可以自己创建一套字体,然后自定义一套字符映射关系表例如设置0xefab是映射字符1, ...
- python-day7爬虫基础之Ajax数据爬取
前几天一直在忙老师的项目,就没有继续学python,也没有写什么收获,今天晚上有空看看书,边看边理解着写吧: 首先说一下,我对Ajax的理解,就是有时候我们在浏览某个网页的时候,只要我们鼠标一直往下滑 ...
- python3编写网络爬虫13-Ajax数据爬取
一.Ajax数据爬取 1. 简介:Ajax 全称Asynchronous JavaScript and XML 异步的Javascript和XML. 它不是一门编程语言,而是利用JavaScript在 ...
- python3下scrapy爬虫(第八卷:循环爬取网页多页数据)
之前我们做的数据爬取都是单页的现在我们来讲讲多页的 一般方式有两种目标URL循环抓取 另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源 话不多说全在代码里(因为刚才写 ...
- Python爬虫入门教程 3-100 美空网数据爬取
美空网数据----简介 从今天开始,我们尝试用2篇博客的内容量,搞定一个网站叫做"美空网"网址为:http://www.moko.cc/, 这个网站我分析了一下,我们要爬取的图片在 ...
随机推荐
- mac的终端运行ifconfig
lo0:loopback回环地址一般是127.0.0.0,loopback指本地环回接口(或地址),亦称回送地址().此类接口是应用最为广泛的一种虚接口,几乎在每台路由器上都会使用. gif0: so ...
- java 8 lambda函数
1 为什么要引进lambda函数 可以简化编码,将事情更多的交给编译器,让编译器帮我们推断我们写的代码的完整形式. 2 lambda函数的语法 2.1 -> (arg1, arg2) -> ...
- 5步减小你的CSS样式表
第一步:学会如何组合选择器 什么是选择器?如果你还不知道什么叫做”选择器”,你可以先参考一下w3schools.com的CSS语法概述. 未优化的CSS代码在下面的图例中,你会看到来自三个不同选择器的 ...
- 基于第三方开源库的OPC服务器开发指南(2)——LightOPC的编译及部署
前文已经说过,OPC基于微软的DCOM技术,所以开发OPC服务器我们要做的事情就是开发一个基于DCOM的EXE文件.一个代理/存根文件,然后就是写一个OPC客户端测试一下我们的服务器了.对于第一项工作 ...
- Repeater 分页
1.RepeaterDemo_Page.aspx前台代码 <body> <form id="form1" runat="server"> ...
- Mysql ---部署,创建用户
版本:mysql-5.7.18-win32 步骤: 1 准备my.ini文件放在bin同级目录 My.ini文件可以设置bsedir/datadir/port等等 2 初始化数据库(5.7版本需要初始 ...
- XML、JSON、ProtocolBuffer特点比较
XML JSON PB Lua 数据结构支持 复杂结构 简单结构 较复杂结构 复杂结构 数据保存方式 文本 文本 二进制 文本 数据保存大小 大 一般 小 一般 解析效率 慢 一般 快 稍快 语言支持 ...
- VS2010-MFC(对话框:颜色对话框)
转自:http://www.jizhuomi.com/software/177.html 颜色对话框大家肯定也不陌生,我们可以打开它选择需要的颜色,简单说,它的作用就是用来选择颜色.MFC中提供了CC ...
- (15)python打包
.py文件在没有安装python软件的电脑上是不能被执行的
- Hexo 博客图片添加至图床---腾讯云COS图床使用。
个人博客:https://mmmmmm.me 源码:https://github.com/dataiyangu/dataiyangu.github.io 腾讯云官网 登录注册 创建存储桶 进入上面的存 ...