tensorflow张量排序
本篇记录一下TensorFlow中张量的排序方法
tf.sort和tf.argsort
# 声明tensor a是由1到5打乱顺序组成的
a = tf.random.shuffle(tf.range(5))
# 打印排序后的tensor
print(tf.sort(a,direction='DESCENDING').numpy())
# 打印从大到小排序后,数字对应原来的索引
print(tf.argsort(a,direction='DESCENDING').numpy())
index = tf.argsort(a,direction='DESCENDING')
# 按照索引序列取值
print(tf.gather(a,index)) # 返回最大的两个值信息
res = tf.math.top_k(a,2)
# indices返回索引
print(res.indices)
# values返回值
print(res.values)

计算准确率实例:
# 定义模型输出预测概率
prob = tf.constant([[0.1,0.2,0.7],[0.2,0.7,0.1]])
# 定义y标签
target = tf.constant([2,0])
# 求top3的索引
k_b = tf.math.top_k(prob,3).indices
# 将矩阵进行转置,即把top-1,top-2,top-3分组
print(tf.transpose(k_b,[1,0]))
# 将y标签扩展成与top矩阵相同维度的tensor,方便比较
target = tf.broadcast_to(target,[3,2]) # 实现求准确率的方法
def accuracy(output,target,topk=(1,)):
maxk = max(topk)
batch_size = target.shape[0] pred = tf.math.top_k(output,maxk).indices
pred = tf.transpose(pred,perm=[1,0])
target_ = tf.broadcast_to(target,pred.shape)
correct = tf.equal(pred,target_) res = []
for k in topk:
correct_k = tf.cast(tf.reshape(correct[:k],[-1]),dtype=tf.float32)
correct_k = tf.reduce_sum(correct_k)
acc = float(correct_k/batch_size)
res.append(acc)
return res
import tensorflow as tf
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
tf.random.set_seed(2467) def accuracy(output, target, topk=(1,)):
maxk = max(topk)
batch_size = target.shape[0] pred = tf.math.top_k(output, maxk).indices
pred = tf.transpose(pred, perm=[1, 0])
target_ = tf.broadcast_to(target, pred.shape)
# [10, b]
correct = tf.equal(pred, target_) res = []
for k in topk:
correct_k = tf.cast(tf.reshape(correct[:k], [-1]), dtype=tf.float32)
correct_k = tf.reduce_sum(correct_k)
acc = float(correct_k* (100.0 / batch_size) )
res.append(acc) return res output = tf.random.normal([10, 6])
output = tf.math.softmax(output, axis=1)
target = tf.random.uniform([10], maxval=6, dtype=tf.int32)
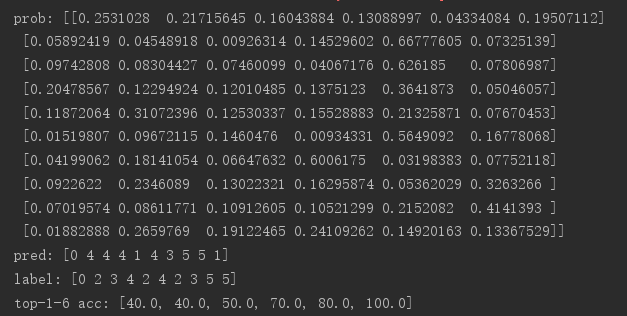
print('prob:', output.numpy())
pred = tf.argmax(output, axis=1)
print('pred:', pred.numpy())
print('label:', target.numpy()) acc = accuracy(output, target, topk=(1,2,3,4,5,6))
print('top-1-6 acc:', acc)
tensorflow张量排序的更多相关文章
- AI - TensorFlow - 张量(Tensor)
张量(Tensor) 在Tensorflow中,变量统一称作张量(Tensor). 张量(Tensor)是任意维度的数组. 0阶张量:纯量或标量 (scalar), 也就是一个数值,例如,\'Howd ...
- Tensorflow张量
张量常规解释 张量(tensor)理论是数学的一个分支学科,在力学中有重要应用.张量这一术语起源于力学,它最初是用来表示弹性介质中各点应力状态的,后来张量理论发展成为力学和物理学的一个有力的数学工具. ...
- tensorflow 张量的阶、形状、数据类型及None在tensor中表示的意思。
x = tf.placeholder(tf.float32, [None, 784]) x isn't a specific value. It's a placeholder, a value th ...
- TensorFlow—张量运算仿真神经网络的运行
import tensorflow as tf import numpy as np ts_norm=tf.random_normal([]) with tf.Session() as sess: n ...
- Tensorflow张量的形状表示方法
对输入或输出而言: 一个张量的形状为a x b x c x d,实际写出这个张量时: 最外层括号[…]表示这个是一个张量,无别的意义! 次外层括号有a个,表示这个张量里有a个样本 再往内的括号有b个, ...
- 121、TensorFlow张量命名
# tf.Graph对象定义了一个命名空间对于它自身包含的tf.Operation对象 # TensorFlow自动选择一个独一无二的名字,对于数据流图中的每一个操作 # 但是给操作添加一个描述性的名 ...
- tensorflow张量限幅
本篇内容有clip_by_value.clip_by_norm.gradient clipping 1.tf.clip_by_value a = tf.range(10) print(a) # if ...
- 吴裕雄--天生自然TensorFlow2教程:张量排序
import tensorflow as tf a = tf.random.shuffle(tf.range(5)) a tf.sort(a, direction='DESCENDING') # 返回 ...
- Tensorflow Lite从入门到精通
TensorFlow Lite 是 TensorFlow 在移动和 IoT 等边缘设备端的解决方案,提供了 Java.Python 和 C++ API 库,可以运行在 Android.iOS 和 Ra ...
随机推荐
- HDU_3415_单调队列
http://acm.hdu.edu.cn/showproblem.php?pid=3415 初探单调队列,需要注意的是每次i维护的是i-1. #include<iostream> #in ...
- gridFS-Nginx的安装与使用
在使用gridFs的nginx模块时,先确认好你的机器上已经安装好了mongo 首先通过git将最新的gridfs的nginx模块下载到本地 git clone https://github.com/ ...
- vue学习(二)模板页配置(bootstrap)
1.替换我们的显示页面 删除components下的所有文件,新建模板页文件夹 layout. //Layout.vue <template> <div> <header ...
- k8s系列--- dashboard认证及分级授权
http://blog.itpub.net/28916011/viewspace-2215214/ 因版本不一样,略有改动 Dashboard官方地址: https://github.com/kube ...
- 2Nginx+keepalive+2tomcat 故障转移
根据真实生产环境 总结. 硬件:共计2台Linux服务器 76和77 每台服务器都安装 Nginx Keepalive Tomcat80作为虚拟ip,负责对外连接. 78和79是两台mys ...
- codewars--js--Valid Braces--正则、键值数组
问题描述: Write a function that takes a string of braces, and determines if the order of the braces is v ...
- clr via c# 运行时序列化
1,快速了解序列化----windows IO 系统,FileStream,BinaryFormatter,SoapFormatter--不支持泛型. public class SerializeRe ...
- 随着页面滚动,数字自动增大的jquery特效
首先为了截出gif图,我下载了一个小工具 GifCam: https://www.appinn.com/gifcam/ 随着页面滚动,数字自动增大的jquery特效 主要就是依赖这个脚本script. ...
- uniapp简易直播
实验准备 在服务器部署nginx-rtmp作为我们直播推流和拉流的服务器(如果服务商选择七牛,也是直接给地址推流).为了加快部署,我在这一步使用Docker. docker pull tiangolo ...
- qt creator源码全方面分析(2-9)
目录 Semantic Highlighting 通用高亮 高亮和折叠块 Semantic Highlighting Qt Creator将C++,QML和JavaScript语言理解为代码,而不是纯 ...