Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理
问题导读
1.在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件?
2.在Standalone部署模式下分为几种模式?
3.在client模式和cluster模式下有什么不同?

概要
部署时的第三方依赖
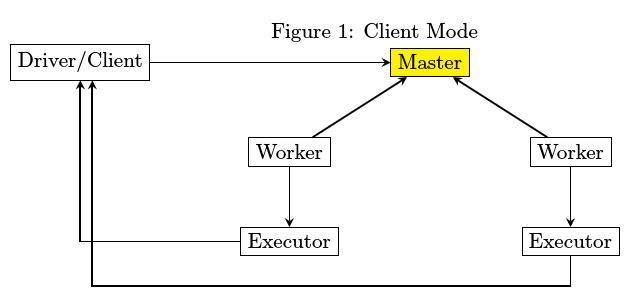
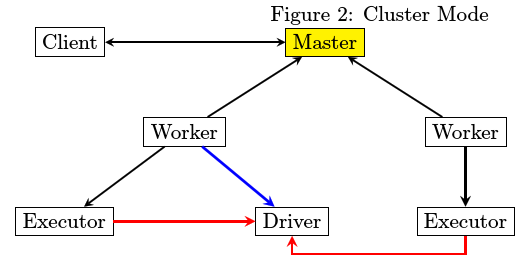 spark访问cassandra
spark访问cassandra
- Master进程最为简单,除了spark jar包之外,不存在第三方库依赖
- Driver和Executor在运行的时候都有可能存在第三方包依赖,分开来讲
- Driver比较简单,spark-submit在提交的时候会指定所要依赖的jar文件从哪里读取
- Executor由worker来启动,worker需要下载Executor启动时所需要的jar文件,那么从哪里下载呢。
HttpFileServer存储第三方jar包,然后由worker从HttpFileServer来获取。为此HttpFileServer需要创建
相应的目录,而Worker也需要创建相应的目录。

实验1

运行中的临时文件
实验2:不进行RDD Cache

进入spark-shell之后运行
- spark-shell>sc.textFile(“README.md”).flatMap(l=>l.split(“ “)).map(w=>(w,1)).reduceByKey(_ + _).foreach(println)
复制代码
实验3: 进行RDD Cache
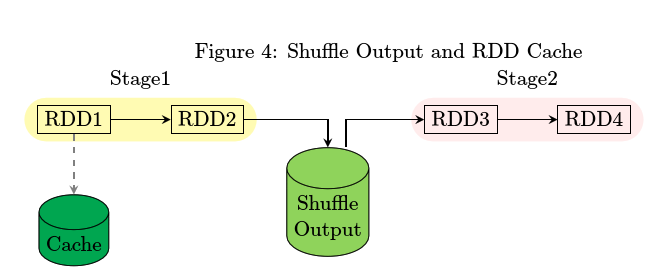
- spark-shell>val rdd1 = sc.textFile(“README.md”).flatMap(l=>l.split(“ “)).map(w=>(w,1)).reduceByKey(_ + _)
- spark-shell> rdd1.persist(MEMORY_AND_DISK_SER)
- spark-shell>rdd1.foreach(println)
复制代码
配置项
文件的清理
下的产生的文件夹,确实会在应用程序退出的时候自动清理掉,如果观察仔细的话,还会发现在spark_local_dirs目录有有诸如*_cache
和*_lock的文件,它们没有被自动清除。这是一个BUG,可以会在spark 1.3中加以更正。有关该BUG的具体描述,参考spark-4323
https://issues.apache.org/jira/browse/SPARK-4323
下的*_cache文件是为了避免同一台机器中多个executor执行同一application时多次下载第三方依赖的问题而引进的patch,详见
JIRA case spark-2713. 对就的代码见spark/util/Utils.java中的fetchFile函数。https://issues.apache.org/jira/browse/SPARK-2713
- find $SPARK_LOCAL_DIRS -max-depth 1 -type f -mtime 1 -exec rm -- {} \;
复制代码
而SPARK_WORK_DIR目录下的形如app-timestamp-seqid的文件夹默认不会自动清除。
那么可以设置哪些选项来自动清除已经停止运行的application的文件夹呢?当然有。
在spark-env.sh中加入如下内容
- SPARK_WORKER_OPTS=”-Dspark.worker.cleanup.enabled=true”
复制代码
实验4
- import org.apache.spark._
- import org.apache.spark.{SparkConf, SparkContext}
- import org.apache.spark.SparkContext._
- import java.util.Date
- object HelloApp {
- def main(args: Array[String]): Unit = {
- val conf = new SparkConf()
- val sc = new SparkContext()
- val fileName = "$SPARK_HOME/README.md"
- val rdd1 = sc.textFile(fileName).flatMap(l => l.split(" ")).map(w => (w, 1))
- rdd1.reduceByKey(_ + _).foreach(println)
- var i: Int = 0
- while ( i < 10 ) {
- Thread.sleep(10000)
- i = i + 1
- }
- }
- }
复制代码
提交运行
- spark-submit –class HelloApp –master spark://127.0.0.1:7077 --deploy-mode cluster HelloApp.jar
复制代码
小结
相关文章
Spark技术实战之1 -- KafkaWordCount
http://www.aboutyun.com/thread-9580-1-1.html
Spark技术实战之2 -- Spark Cassandra Connector的安装和使用
http://www.aboutyun.com/thread-9582-1-1.html
Spark技术实战之3 -- 利用Spark将json文件导入Cassandra
http://www.aboutyun.com/thread-9583-1-1.html
Apache Spark技术实战之4 -- SparkR的安装及使用
http://www.aboutyun.com/thread-10082-1-1.html
Apache Spark技术实战之5 -- spark-submit常见问题及其解决
http://www.aboutyun.com/thread-10083-1-1.html
Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理
http://www.aboutyun.com/thread-11862-1-1.html
http://www.tuicool.com/articles/RV3MFz
Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理的更多相关文章
- Apache Spark技术实战之8:Standalone部署模式下的临时文件清理
未经本人同意严禁转载,徽沪一郎. 概要 在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件,这些临时目录和文件又是在什么时候被清理,本文将就这些问题做深入细致的解答. 从 ...
- Apache Spark源码走读之15 -- Standalone部署模式下的容错性分析
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就standalone部署方式下的容错性问题做比较细致的分析,主要回答standalone部署方式下的包含哪些主要节点,当某一类节点出现问题时,系统是如 ...
- Apache Spark技术实战之4 -- 利用Spark将json文件导入Cassandra
欢迎转载,转载请注明出处. 概要 本文简要介绍如何使用spark-cassandra-connector将json文件导入到cassandra数据库,这是一个使用spark的综合性示例. 前提条件 假 ...
- Apache Spark技术实战之3 -- Spark Cassandra Connector的安装和使用
欢迎转载,转载请注明出处,徽沪一郎. 概要 前提 假设当前已经安装好如下软件 jdk sbt git scala 安装cassandra 以archlinux为例,使用如下指令来安装cassandra ...
- Apache Spark技术实战之9 -- 日志级别修改
摘要 在学习使用Spark的过程中,总是想对内部运行过程作深入的了解,其中DEBUG和TRACE级别的日志可以为我们提供详细和有用的信息,那么如何进行合理设置呢,不复杂但也绝不是将一个INFO换为TR ...
- Apache Spark技术实战之6 -- spark-submit常见问题及其解决
除本人同意外,严禁一切转载,徽沪一郎. 概要 编写了独立运行的Spark Application之后,需要将其提交到Spark Cluster中运行,一般会采用spark-submit来进行应用的提交 ...
- Apache Spark技术实战之1 -- KafkaWordCount
欢迎转载,转载请注明出处,徽沪一郎. 概要 Spark应用开发实践性非常强,很多时候可能都会将时间花费在环境的搭建和运行上,如果有一个比较好的指导将会大大的缩短应用开发流程.Spark Streami ...
- Apache Spark技术实战之7 -- CassandraRDD高并发数据读取实现剖析
未经本人同意,严禁转载,徽沪一郎. 概要 本文就 spark-cassandra-connector 的一些实现细节进行探讨,主要集中于如何快速将大量的数据从cassandra 中读取到本地内存或磁盘 ...
- Apache Spark技术实战之5 -- SparkR的安装及使用
欢迎转载,转载请注明出处,徽沪一郎. 概要 根据论坛上的信息,在Sparkrelease计划中,在Spark 1.3中有将SparkR纳入到发行版的可能.本文就提前展示一下如何安装及使用SparkR. ...
随机推荐
- MyBatis学习总结(四)——MyBatis缓存与代码生成
一.MyBatis缓存 缓存可以提高系统性能,可以加快访问速度,减轻服务器压力,带来更好的用户体验.缓存用空间换时间,好的缓存是缓存命中率高的且数据量小的.缓存是一种非常重要的技术. 1.0.再次封装 ...
- EF怎样实现ORM思想的(转载)
EF简介 实体框架(Entity Framework)简称EF,是微软以ADO.NET为基础所发展出来的对象关系对应(O/R Mapping)解决方案.是ADO.NET中的一组支持开发面向数据的软件应 ...
- HTML标签笔记
换行符:<br/> 首部: <!DOCTYPE>: 说明html文档使用的标准, 在HTML5中仅为 <!DOCTYPE html>1.头标签 <head&g ...
- hive函数应用之操作json
1.创建表 createtable.sql中存放的创建表语句如下 create external table adt.jsontest ( appKey string comment "AP ...
- git参考, 小结
git官网: https://git-scm.com 菜鸟教程: http://www.runoob.com/git/git-tutorial.html 廖雪峰: https://www.liaoxu ...
- jsp引入本地图片
jsp引入本地图片 通用解决方法: 在tomcat的server.xml配置文件中,在<host></host>标签中间添上一句 <!-- docBase : 磁盘绝对路 ...
- Angular6 项目开发常用时间组件服务
一.利用Angular 命令行工具生成一个服务. 详情见:<Angular环境搭建>,服务代码如下: import { Injectable } from '@angular/core'; ...
- angular ng-repeat radio取值
- angular ztree 梯形结构json配置、点击节点事件、默认展开所有
// 获取树数据 $scope.initZtreeData = function () { var url = '/bpopstation/func/queryAll.do'; $http.post( ...
- 小tips:JS数值之间的转换,JS中最大的Number是多少?,JS == 与 === 的区别
JS数值之间的转换 Number(), parseInt(),parseFloat() Number()函数的转换规则如下: 1.如果boolean值,true和false将分别被转换为1和02.如果 ...