Python之路(第三十九篇)管道、进程间数据共享Manager
一、管道
概念
管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信.
先画一幅图帮助大家理解下管道的基本原理
%E3%80%90s9day38%E3%80%91\20180703145823936.jpg?lastModify=1556467586)
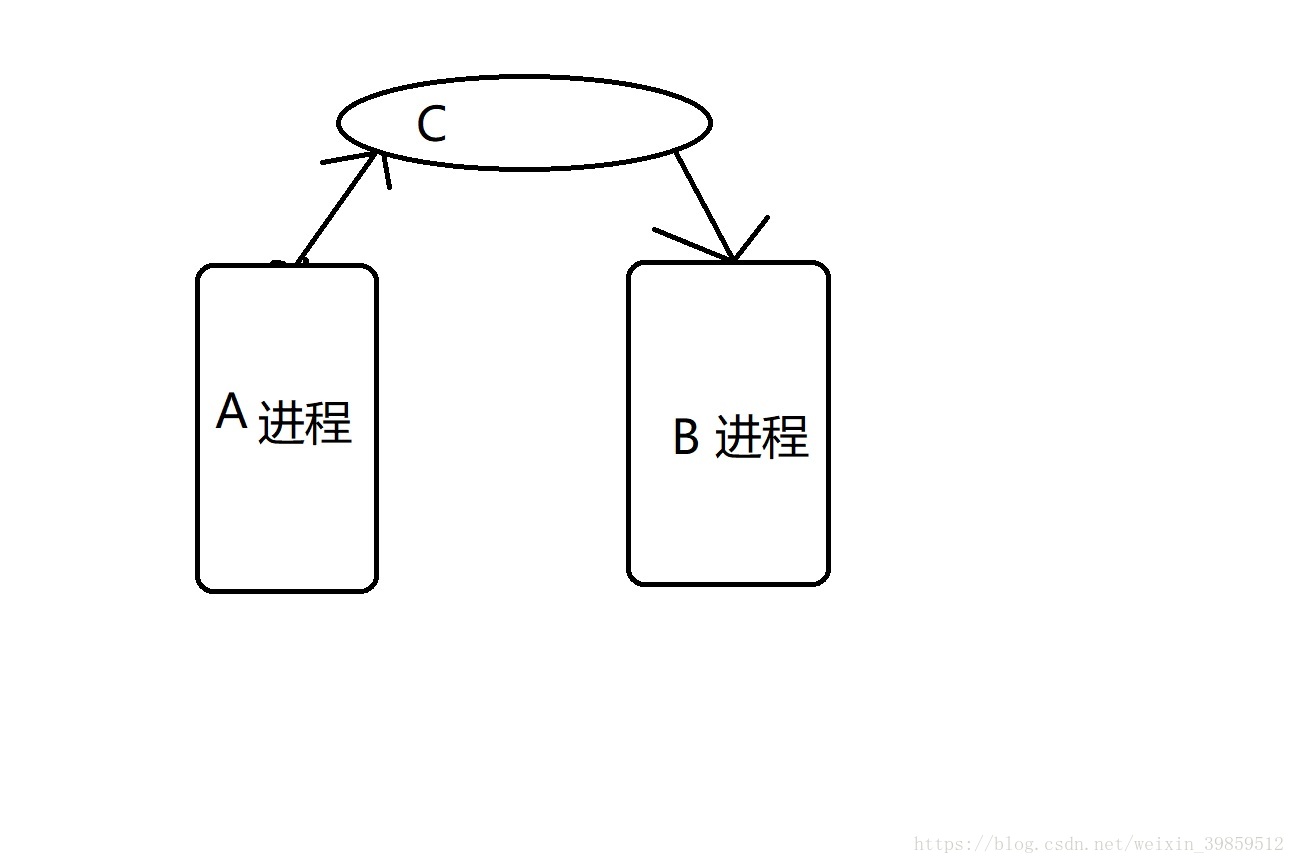
现有2个进程A和B,他们都在内存中开辟了空间,那么我们在内存中再开辟一个空间C,作用是连接这两个进程的。对于进程来说内存空间是可以共享的(任何一个进程都可以使用内存,内存当中的空间是用地址来标记的,我们通过查找某一个地址就能找到这个内存)A进程可以不断的向C空间输送东西,B进程可以不断的从C空间读取东西,这就是进程间的通信 .
管道在信息传输上是以流的方式传输, 也就是你从A进程不断的写入,B进程源源不断的读出,A进程先写入的就会被B进程先读出,后写进来的就会被后读出,
Pipe仅仅适用于只有两个进程一读一写的半双工情况,也就是说信息是只向一个方向流动。单项通信叫做半双工,双向叫做全双工.
单工:简单的说就是一方只能发信息,另一方则只能收信息,通信是单向的。
半双工:比单工先进一点,就是双方都能发信息,但同一时间则只能一方发信息。
全双工:比半双工再先进一点,就是双方不仅都能发信息,而且能够同时发送。
实现机制:
管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。
管道特点
管道是单向的、先进先出的、无结构的字节流,它把一个进程的输出和另一个进程的输入连接在一起。
写进程在管道的尾端写入数据,读进程在管道的首端读出数据。数据读出后将从管道中移走,其它读进程都不能再读到这些数据。
管道提供了简单的流控制机制。进程试图读一个空管道时,在数据写入管道前,进程将一直阻塞。同样,管道已经满时,进程再试图写管道,在其它进程从管道中读走数据之前,写进程将一直阻塞。
匿名管道具有的特点:
只能用于具有亲缘关系的进程之间的通信(也就是父子进程或者兄弟进程之间)。
一种半双工的通信模式,具有固定的读端和写端。
LINUX把管道看作是一种文件,采用文件管理的方法对管道进行管理,对于它的读写也可以使用普通的read()和write()等函数。但是它不是普通的文件,并不属于其他任何文件系统,只存在于内核的内存空间中。
参数介绍
#创建管道的类:
Pipe([duplex]):在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道
#参数介绍:
dumplex:默认管道是半双工的,如果将duplex射成False,conn1只能用于接收,conn2只能用于发送。
#主要方法:
conn1.recv():接收conn2.send(obj)发送的对象。如果没有消息可接收,recv方法会一直阻塞。如果连接的另外一端已经关闭,那么recv方法会抛出EOFError。
conn1.send(obj):通过连接发送对象。obj是与序列化兼容的任意对象
#其他方法:
conn1.close():关闭连接。如果conn1被垃圾回收,将自动调用此方法
conn1.fileno():返回连接使用的整数文件描述符
conn1.poll([timeout]):如果连接上的数据可用,返回True。timeout指定等待的最长时限。如果省略此参数,方法将立即返回结果。如果将timeout射成None,操作将无限期地等待数据到达。 conn1.recv_bytes([maxlength]):接收c.send_bytes()方法发送的一条完整的字节消息。maxlength指定要接收的最大字节数。如果进入的消息,超过了这个最大值,将引发IOError异常,并且在连接上无法进行进一步读取。如果连接的另外一端已经关闭,再也不存在任何数据,将引发EOFError异常。
conn.send_bytes(buffer [, offset [, size]]):通过连接发送字节数据缓冲区,buffer是支持缓冲区接口的任意对象,offset是缓冲区中的字节偏移量,而size是要发送字节数。结果数据以单条消息的形式发出,然后调用c.recv_bytes()函数进行接收 conn1.recv_bytes_into(buffer [, offset]):接收一条完整的字节消息,并把它保存在buffer对象中,该对象支持可写入的缓冲区接口(即bytearray对象或类似的对象)。offset指定缓冲区中放置消息处的字节位移。返回值是收到的字节数。如果消息长度大于可用的缓冲区空间,将引发BufferTooShort异常。
创建管道过程的示意图
%E3%80%90s9day38%E3%80%91\%E7%AE%A1%E9%81%93%E5%88%9B%E5%BB%BA%E7%A4%BA%E6%84%8F%E5%9B%BE.jpg?lastModify=1556467586)


%E3%80%90s9day38%E3%80%91\%E7%AE%A1%E9%81%93%E5%88%9B%E5%BB%BA%E7%A4%BA%E6%84%8F%E5%9B%BE2.jpg?lastModify=1556467586)
例子
# 主进程写,子进程读
from multiprocessing import Pipe,Process
def func(out_pipe, in_pipe):
in_pipe.close()
# 关闭复制过来的管道的输入端
while True:
try :
msg = out_pipe.recv() #子进程的管道端口接收主进程的数据
print(msg)
except EOFError:
out_pipe.close()
break
if __name__ == '__main__':
out_pipe, in_pipe = Pipe()
Process(target=func,args = (out_pipe, in_pipe)).start() #启动子进程
out_pipe.close() #关闭主进程的输出管道端口
for i in range(20):
in_pipe.send('hello world!') #通过管道的端口向子进程写入
in_pipe.close()
例子2
# 出现EOF错误的情况
# 当pipe的输入端被关闭,且无法接收到输入的值,那么就会抛出EOFError。
from multiprocessing import Pipe, Process
def func(out_pipe, in_pipe):
in_pipe.close()
# 关闭复制过来的管道的输入端
while True:
msg = out_pipe.recv() # 子进程的管道端口接收主进程的数据
print(msg)
if __name__ == '__main__':
out_pipe, in_pipe = Pipe()
Process(target=func, args=(out_pipe, in_pipe)).start() # 启动子进程
out_pipe.close() # 关闭主进程的输出管道端口
for i in range(20):
in_pipe.send('hello world!') # 通过管道的端口向子进程写入
in_pipe.close()
基于管道实现生产者消费者模型
from multiprocessing import Process,Pipe
import time,random
def consumer(p,name):
in_pipe,out_pipe=p
out_pipe.close()
while True:
try:
# time.sleep(random.uniform(0,1))
baozi=in_pipe.recv()
print('%s 收到包子:%s' %(name,baozi))
except EOFError:
in_pipe.close()
break
def producer(p,name):
in_pipe,out_pipe=p
in_pipe.close()
for i in range(10):
# print(i)
str ='%s生产的包子%s'%(name,i)
out_pipe.send(str)
# time.sleep(1)
else:
out_pipe.close()
if __name__ == '__main__':
in_pipe,out_pipe=Pipe()
p = Process(target=producer,args=((in_pipe,out_pipe),'jack'))
c1=Process(target=consumer,args=((in_pipe,out_pipe),'c1'))
c2=Process(target=consumer,args=((in_pipe,out_pipe),'c2'))
c1.start()
c2.start()
p.start()
in_pipe.close()
out_pipe.close()
c1.join()
c2.join()
print('主进程')
# 基于管道实现进程间通信(与队列的方式是类似的,队列就是管道加锁实现的)
## 加锁来控制操作管道的行为,来避免进程之间争抢数据造成的数据不安全现象
这里需要加锁来解决数据不安全的情况
from multiprocessing import Process,Pipe,Lock
def consumer(produce, consume,name,lock):
produce.close()
while True:
lock.acquire()
baozi=consume.recv()
lock.release()
if baozi:
print('%s 收到包子:%s' %(name,baozi))
else:
consume.close()
break
def producer(produce, consume,n):
consume.close()
for i in range(n):
produce.send(i)
produce.send(None)
produce.send(None)
produce.close()
if __name__ == '__main__':
produce,consume=Pipe()
lock = Lock()
c1=Process(target=consumer,args=(produce,consume,'c1',lock))
c2=Process(target=consumer,args=(produce,consume,'c2',lock))
p1=Process(target=producer,args=(produce,consume,30))
c1.start()
c2.start()
p1.start()
produce.close()
consume.close()
二、进程间的数据共享manager
使用Manager可以方便的进行多进程数据共享,事实上Manager的功能远不止于此 。Manager支持的类型有list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Queue,Value和Array。
但与管道类似,这里的数据也是不安全的。需要用锁来解决。
from multiprocessing import Manager,Process
def main(dic):
dic['count'] -= 1
# print(dic)
if __name__ == '__main__':
m = Manager()#为这个manager类注册存储容器,也就是通过这个manager类实现的共享的变量
dic=m.dict({'count':100})
p_lst = []
for i in range(50):
p = Process(target=main, args=(dic,))
p_lst.append(p)
p.start()
for p in p_lst:
p.join()
print("主进程",dic['count'])
分析:多运行几次可以看到,每次输出的结果都基本是不同的,因此这里还是需要用锁来解决。
from multiprocessing import Manager,Process,Lock
def main(dic,lock):
# with lock:可以这样写,也可以写成下面的样子
lock.acquire()
dic['count'] -= 1
lock.release()
if __name__ == '__main__':
m = Manager()
l = Lock()
dic=m.dict({'count':100})
p_lst = []
for i in range(50):
p = Process(target=main,args=(dic,l))
p.start()
p_lst.append(p)
for i in p_lst: i.join()
print('主进程',dic)
参考资料
[1]https://segmentfault.com/a/1190000008122273
[2]http://www.th7.cn/system/lin/201605/165994.shtml
[3]https://blog.csdn.net/weixin_39859512/article/details/80898340
Python之路(第三十九篇)管道、进程间数据共享Manager的更多相关文章
- Python之路【第十九篇】:爬虫
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
- Python之路(第三十八篇) 并发编程:进程同步锁/互斥锁、信号量、事件、队列、生产者消费者模型
一.进程锁(同步锁/互斥锁) 进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的, 而共享带来的是竞争,竞争带来的结果就是错乱,如何控制,就是加锁处理. 例 ...
- Python之路(第三十六篇)并发编程:进程、同步异步、阻塞非阻塞
一.理论基础 进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一.操作系统的其他所有内容都是围绕进程的概念展开的. 即使可以利用的cpu只有一个(早期的 ...
- 【Python之路】第十九篇--Python操作MySQL
本篇对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy pymsql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb ...
- Python之路【第二十九篇】:django ORM模型层
ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的 ...
- Python之路【第十九篇】自定义分页实现(模块化)
自定义分页 1.目的&环境准备 目的把分页写成一个模块的方式然后在需要分页的地方直接调用模块就行了. 环境准备Django中生成一个APP并且注册,配置URL&Views 配置URL ...
- Python之路(第三十五篇) 并发编程:操作系统的发展史、操作系统的作用
一.操作系统发展史 第一阶段:手工操作 —— 真空管和穿孔卡片 第一代之前人类是想用机械取代人力,第一代计算机的产生是计算机由机械时代进入电子时代的标志,从Babbage失败之后一直到第二次世界大 ...
- Python之路(第三十二篇) 网络编程:udp套接字、简单文件传输
一.UDP套接字 服务端 # udp是无链接的,先启动哪一端都不会报错 # udp没有链接,与tcp相比没有链接循环,只有通讯循环 server = socket.socket(socket.AF_I ...
- Python之路【第十九篇】:前端CSS
CSS 一.CSS概述 CSS是Cascading Style Sheets的简称,中文称为层叠式样式表,用来控制网页数据的表现,可以使网页的表现与数据内容分离. 学CSS后我们需要掌握的技能: 1. ...
随机推荐
- Idea spring 配置文件报红 URI is not registered
把报错的加到如下忽略列表中
- jedisCluster 报错: redis.clients.jedis.exceptions.JedisClusterException: No way to dispatch this command to Redis Cluster because keys have different slots.
根本原因:jedisCluster不支持mget/mset等跨槽位的操作. 版本:2.9.0 解决办法,推荐更改redis的驱动修改为: lettuce lettuce 项目地址:https://gi ...
- __name__ __main__ 作用
1 __name__ 在自己文件下面执行 就显示__main__ 2 如果__name__是在其他文件里面,然后通过当前文件调用到其他文件执行,就会显示的当前文件路劲的文件名结果: if __name ...
- sql server 新语法 收藏
1.行转列 PIVOT函数,行转列,列转换UNPIVOT select * from ShoppingCart as C PIVOT(count(TotalPrice) FOR [Week] IN([ ...
- log4net的简单使用记录一下,防止下次忘记
1.在程序的assembly.cs下添加: [assembly: log4net.Config.XmlConfigurator(Watch = true)] (忘记这一步,弄了半天,上次好像也是这样 ...
- Mac系统如何显示隐藏文件?
显示全部文件 defaults write com.apple.finder AppleShowAllFiles -bool true osascript -e 'tell application & ...
- 49.字符串转int
面360的时候这道题目加了一个要求就是要求小数输出整数,故增加一个关于小数点的判断 要注意转义字符:"."和"|"都是转义字符,必须得加"\\&quo ...
- MongoDB 集合(Collection)对应的物理文件
dbpath下是清一色的collection-n-***与index-n-***开头的物理文件,如何知道某一个集合与其对应与其对应的物理文件? db.collection_name.stats() 返 ...
- hbase-hive整合及sqoop的安装配置使用
从hbase中拿数据,然后整合到hbase中 上hive官网 -- 点击wiki--> hive hbase integation(整合) --> 注意整合的时候两个软件的版本要能进行整 ...
- Android 网络编程的陷阱
陷阱一,不要在主线程或者UI线程中建立网络连接 Androd4.0以后,不允许在主线程中建立网络连接,不然会出现莫名其妙的程序退出情况.正确的做法是在主线程中,创建新的线程来运行网络连接程序. // ...