logistic回归和最大熵
回顾发现,李航的《统计学习方法》有些章节还没看完,为了记录,特意再水一文。
0 - logistic分布
如《统计学习方法》书上,设X是连续随机变量,X服从logistic分布是指X具有以下分布函数和密度函数:
\[F(x) = P(X \leq x)=\frac{1}{1+e^{-(x-\mu)/\gamma}}\]
\[f(x) = F'(x) = \frac{e^{-(x-\mu)/\gamma}}{1+e^{-(x-\mu)/\gamma}}\]
其中\(\mu\)是位置参数,\(\gamma\)是形状参数,logistic分布函数是一条S形曲线,该曲线以点\((\mu,\frac{1}{2})\)为中心对称,即:
\[F(-x+\mu)-\frac{1}{2} = -F(x-\mu)+\frac{1}{2}\]
\(\gamma\)参数越小,那么该曲线越往中间缩,则中心附近增长越快

图0.1 logistic 密度函数和分布函数
1 - 二项logistic回归
我们通常所说的逻辑回归就是这里的二项logistic回归,它有如下的式子:
\[h_\theta(\bf x)=g(\theta^T\bf x) = \frac{1}{1+e^{-\theta^T\bf x }}\]
这个函数叫做logistic函数,也被称为sigmoid函数,其中\(x_i\in{\bf R}^n,y_i\in\{0,1\}\)且有如下式子:
\(P(y=1|\bf x;\theta) = h_\theta(\bf x)\)
\(P(y=0|\bf x;\theta) =1- h_\theta(\bf x)\)
\(\log\frac{P(y=1|\bf x;\theta) }{1-P(y=1|\bf x;\theta) }=\theta^T\bf x\)
即紧凑的写法为:
\[p(y|\bf x; \theta) = (h_\theta(x))^y(1-h_\theta(\bf x))^{1-y}\]
基于\(m\)个训练样本,通过极大似然函数来求解该模型的参数:
\[\begin{eqnarray}L(\theta)
&=&\prod_{i=1}^mp(y^{(i)}|x^{(i)};\theta)\\
&=&\prod_{i=1}^m(h_\theta(x^{(i)}))^{y^{(i)}}(1-h_\theta(\bf x^{(i)}))^{1-y^{(i)}}
\end{eqnarray}\]
将其转换成log最大似然:
\[\begin{eqnarray}\it l(\theta)
&=&\log L(\theta)\\
&=&\sum_{i=1}^my^{(i)}\log h(x^{(i)})+(1-y^{(i)})\log (1-h(x^{(i)}))
\end{eqnarray}\]
而该sigmoid函数的导数为:\(g'(z) = g(z)(1-g(z))\),假设\(m=1\)(即随机梯度下降法),将上述式子对关于\(\theta_j\)求导得:
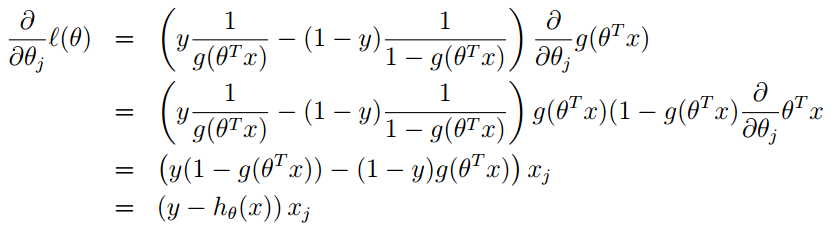
ps:上述式子是单样本下梯度更新过程,且基于第\(j\)个参数(标量)进行求导,即涉及到输入样本\(x\)的第\(j\)个元素\(x_j\)
而关于参数\(\theta\)的更新为:\(\theta:=\theta+\alpha\nabla_\theta\it l(\theta)\)
ps:上面式子是加号而不是减号,是因为这里是为了最大化,而不是最小化
通过多次迭代,使得模型收敛,并得到最后的模型参数。
2 - 多项logistic回归
假设离散型随机变量\(Y\)的取值集合为\({1,2,...,K}\),那么多项logistic回归模型为:
\[P(Y=k|x) = \frac{e^{(\theta_k* \bf x)}}{1+\sum_{k=1}^{K-1}e^{(\theta_k* \bf x)}},k=1,2,...K-1\]
而第\(K\)个概率为:
\[P(Y=K|x) = \frac{1}{1+\sum_{k=1}^{K-1}e^{(\theta_k* \bf x)}}\]
这里\(x\in{\bf R}^{n+1},\theta_k\in {\bf R}^{n+1}\),即引入偏置。
3 - softmax
logistic回归模型的代价函数为:
\[J(\theta) = -\frac{1}{m}\left[\sum_{i=1}^{m} y^{(i)}\log h_\theta({\bf x}^{(i)})+(1-y^{(i)})\log (1-h_\theta({\bf x}^{(i)})) \right]\]
而softmax是当多分类问题,即\(y^{(i)}\in \{1,2,...,K\}\)。对于给定的样本向量\(\bf x\),模型对每个类别都会输出一个概率值\(p(y=j|\bf x)\),则如下图:
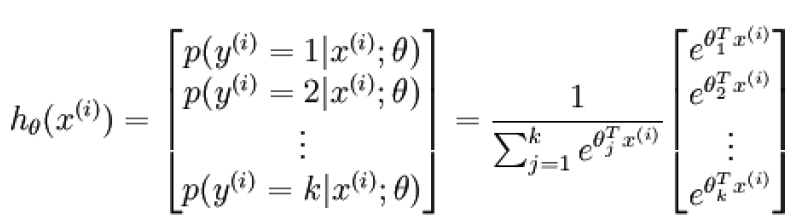
其中\(\theta_1,\theta_2,...\theta_k \in R^{n+1}\)都是模型的参数,其中分母是为了归一化使得所有概率之和为1.
从而softmax的代价函数为:
\[\begin{eqnarray}J(\theta)
&=& -\frac{1}{m}\left[\sum_{i=1}^{m} \sum_{j=1}^K1\{y^{(i)}=j\}\log \frac{e^{\theta_j^T{\bf x}^{(i)}}}{\sum_{l=1}^Ke^{\theta_l^T{\bf x}^{(i)}}}\right]\\
&=& -\frac{1}{m}\left[\sum_{i=1}^{m} \sum_{j=1}^K1\{y^{(i)}=j\}\left[\log {e^{\theta_j^T{\bf x}^{(i)}}}-\log{\sum_{l=1}^Ke^{\theta_l^T{\bf x}^{(i)}}}\right]\right]
\end{eqnarray}\]
其中,\(p(y^{(i)}=j|{\bf x}^{(i)};\theta)=\frac{e^{\theta_j^T{\bf x}^{(i)}}}{\sum_{l=1}^Ke^{\theta_l^T{\bf x}^{(i)}}}\)该代价函数关于第j个参数的导数为:
\[\begin{eqnarray}\nabla_{\theta_j}J(\theta)
&=&-\frac{1}{m}\sum_{i=1}^{m}1\{y^{(i)}=j\}\left[\frac{e^{\theta_j^T{\bf x}^{(i)}}* {\bf x}^{(i)}}{e^{\theta_j^T{\bf x}^{(i)}}}-\frac{e^{\theta_j^T{\bf x}^{(i)}}* {\bf x}^{(i)}}{\sum_{l=1}^Ke^{\theta_l^T{\bf x}^{(i)}}}\right]\\
&=&-\frac{1}{m}\sum_{i=1}^{m}1\{y^{(i)}=j\}\left[{\bf x}^{(i)}-\frac{e^{\theta_j^T{\bf x}^{(i)}}* {\bf x}^{(i)}}{\sum_{l=1}^Ke^{\theta_l^T{\bf x}^{(i)}}}\right]\\
&=&-\frac{1}{m}\sum_{i=1}^{m}{\bf x}^{(i)}\left(1\{y^{(i)}=j\}-\frac{e^{\theta_j^T{\bf x}^{(i)}}}{\sum_{l=1}^Ke^{\theta_l^T{\bf x}^{(i)}}}\right)\\
&=&-\frac{1}{m}\sum_{i=1}^{m}{\bf x}^{(i)}\left[1\{y^{(i)}=j\} - p(y^{(i)}=j|{\bf x}^{(i)};\theta)\right]
\end{eqnarray}\]
ps:因为在关于\(\theta_j\)求导的时候,其他非\(\theta_j\)引起的函数对该导数为0。所以\(\sum_{j=1}^K\)中省去了其他部分
ps:这里的\(\theta_j\)不同于逻辑回归部分,这里是一个向量;
4 - softmax与logistic的关系
将逻辑回归写成如下形式:
\[\begin{eqnarray}J(\theta)
&=& -\frac{1}{m}\left[\sum_{i=1}^{m} y^{(i)}\log h_\theta({\bf x}^{(i)})+(1-y^{(i)})\log (1-h_\theta({\bf x}^{(i)})) \right]\\
&=& -\frac{1}{m}\left[\sum_{i=1}^{m} \sum_{j=0}^11\{y^{(i)}=j\}\log p(y^{(i)}=j|{\bf x}^{(i)};\theta)\right]
\end{eqnarray}\]
可以看出当k=2的时候,softmax就是逻辑回归模型
参考资料:
[] 李航,统计学习方法
[] 周志华,机器学习
[] CS229 Lecture notes Andrew Ng
[] ufldl
[] Foundations of Machine Learning
logistic回归和最大熵的更多相关文章
- 统计学习方法6—logistic回归和最大熵模型
目录 logistic回归和最大熵模型 1. logistic回归模型 1.1 logistic分布 1.2 二项logistic回归模型 1.3 模型参数估计 2. 最大熵模型 2.1 最大熵原理 ...
- Logistic回归和SVM的异同
这个问题在最近面试的时候被问了几次,让谈一下Logistic回归(以下简称LR)和SVM的异同.由于之前没有对比分析过,而且不知道从哪个角度去分析,一时语塞,只能不知为不知. 现在对这二者做一个对比分 ...
- 机器学习之线性回归以及Logistic回归
1.线性回归 回归的目的是预测数值型数据的目标值.目标值的计算是通过一个线性方程得到的,这个方程称为回归方程,各未知量(特征)前的系数为回归系数,求这些系数的过程就是回归. 对于普通线性回归使用的损失 ...
- 神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词.看完后有一些自己的小想法,也想做一个玩儿一玩儿.用到的原理是深度学习里 ...
- 机器学习——Logistic回归
1.基于Logistic回归和Sigmoid函数的分类 2.基于最优化方法的最佳回归系数确定 2.1 梯度上升法 参考:机器学习--梯度下降算法 2.2 训练算法:使用梯度上升找到最佳参数 Logis ...
- logistic回归
logistic回归 回归就是对已知公式的未知参数进行估计.比如已知公式是$y = a*x + b$,未知参数是a和b,利用多真实的(x,y)训练数据对a和b的取值去自动估计.估计的方法是在给定训练样 ...
- Logistic回归 python实现
Logistic回归 算法优缺点: 1.计算代价不高,易于理解和实现2.容易欠拟合,分类精度可能不高3.适用数据类型:数值型和标称型 算法思想: 其实就我的理解来说,logistic回归实际上就是加了 ...
- Logistic回归的使用
Logistic回归的使用和缺失值的处理 从疝气病预测病马的死亡率 数据集: UCI上的数据,368个样本,28个特征 测试方法: 交叉测试 实现细节: 1.数据中因为存在缺失值所以要进行预处理,这点 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
随机推荐
- Linux应用和系统库的2种安装方式---源码安装tarball和二进制rpm包
一.应用程序和系统库从哪里来? 两种机制,源码安装和二进制安装. 二.源码安装 tarball 1.核心思想是:利用开源代码,自己编译生成应用程序或者库,要求系统上必须已安装TMG(tar, make ...
- Windows 批处理获取某路径下最新创建的文件的名称
批处理获取某路径下最新创建的文件的名称 by:授客 QQ:1033553122 echo off setlocal enabledelayedexpansion rem 设置文件所在目录 set sr ...
- loadrunner 脚本优化-参数化之Parameter List参数同行取值
脚本优化-参数化之Parameter List参数同行取值 by:授客 QQ:1033553122 select next row 记录选择方式 Same line as,这个选项只有当参数多余一个时 ...
- 四. Redis事务处理
Redis目前对事务的支持还是比较简单,Redis能保证一个Client发起的事务中的命令可以连续执行,而中间不会插入其他Client的命令:当一个Client在连接中发起一个multi命令的时候,这 ...
- setfont()函数
设计字体显示效果 Font mf = new Font(String 字体,int 风格,int 字号); 字体:TimesRoman, Courier, Arial等 风格:三个常量 lFont.P ...
- 洗礼灵魂,修炼python(82)--全栈项目实战篇(10)—— 信用卡+商城项目(模拟京东淘宝)
本次项目相当于对python基础做总结,常用语法,数组类型,函数,文本操作等等 本项目在博客园里其他开发者也做过,我是稍作修改来的,大体没变的 项目需求: 信用卡+商城: A.信用卡(类似白条/花呗) ...
- jQuery设置元素的readonly和disabled属性
jQuery的api中提供了对元素应用disabled和readonly属性的方法,如下: 1.readonly $('input').attr("readonly",&qu ...
- K-means算法的matlab程序(初步)
K-means算法的matlab程序 在https://www.cnblogs.com/kailugaji/p/9648369.html 文章中已经介绍了K-means算法,现在用matlab程序实现 ...
- CISCO 动态路由(RIP)
RIP(路由信息协议):是一种内部网关协议(IGP),是一种动态路由选择协议,基于距离矢量算法(DistanceVectorAlgorithms),使用“跳数”(即metric)来衡量到达目标地址的路 ...
- kafka-connect-hdfs连接hadoop hdfs时候,竟然是单点的,太可怕了。。。果断改成HA
2017-08-16 11:57:28,237 WARN [org.apache.hadoop.hdfs.LeaseRenewer][458] - <Failed to renew lease ...