Hadoop2.0环境安装
0. Hadoop源码包下载
http://mirror.bit.edu.cn/apache/hadoop/common
1. 集群环境
操作系统
CentOS7
集群规划
Master 192.168.1.210
Slave1 192.168.1.211
Slave2 192.168.1.203
2. 关闭系统防火墙及内核防火墙
#Execute in Master、Slave1、Slave2
#关闭一次防火墙
systemctl stop firewalld
#永久关闭防火墙
systemctl disable firewalld
#临时关闭内核防火墙
setenforce 0
#永久关闭内核防火墙
vim /etc/selinux/config
SELINUX=disabled

3. 修改主机名
#Execute in Master
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master
#Execute in Slave1
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave1
#Execute in Slave2
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=slave2
4. 修改IP地址
#Execute in Master、Slave1、Slave2
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:50:56:89:25:3E
TYPE=Ethernet
UUID=de38a19e-4771-4124-9792-9f4aabf27ec4
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
#下列信息需要根据实际情况设置
IPADDR=192.168.1.101
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=119.29.29.29
5. 修改主机文件
#Execute in Master、Slave1、Slave2
vim /etc/hosts
172.16.11.97 master
172.16.11.98 slave1
172.16.11.99 slave2
6. SSH互信配置
#Execute in Master、Slave1、Slave2
#生成密钥对(公钥和私钥)
ssh-keygen -t rsa
#三次回车生成密钥
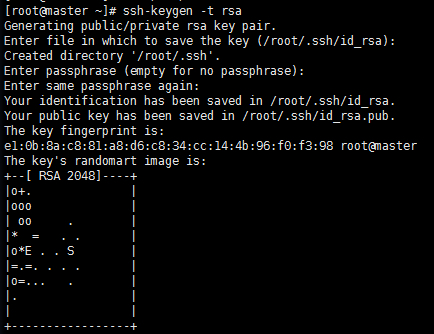
#Execute in Maste
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
chmod 600 /root/.ssh/authorized_keys
#追加密钥到Master
ssh slave1 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
ssh slave2 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
#复制密钥到从节点
scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/authorized_keys
scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/authorized_keys
7. 安装JDK
http://www.oracle.com/technetwork/java/javase/downloads/index.html
#Master
cd /usr/local/src
wget 具体已上面的链接地址为准
tar zxvf jdk1.8.0_152.tar.gz
8. 配置JDK环境变量
#Executer in Maste
#配置JDK环境变量
vim ~/.bashrc
JAVA_HOME=/usr/local/src/jdk1.8.0_152
JAVA_BIN=/usr/local/src/jdk1.8.0_152/bin
JRE_HOME=/usr/local/src/jdk1.8.0_152/jre
CLASSPATH=/usr/local/jdk1.8.0_152/jre/lib:/usr/local/jdk1.8.0_152/lib:/usr/local/jdk1.8.0_152/jre/lib/charsets.jar
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
#分发到其他节点
scp /root/.bashrc root@slave1:/root/.bashrc
scp /root/.bashrc root@slave2:/root/.bashrc
9. JDK拷贝到Slave主机
#Executer in Master
scp -r /usr/local/src/jdk1.8.0_152 root@slave1:/usr/local/src/jdk1.8.0_152
scp -r /usr/local/src/jdk1.8.0_152 root@slave2:/usr/local/src/jdk1.8.0_152
10. 下载安装包
#Master
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.2/hadoop-2.8.2.tar.gz
tar zxvf hadoop-2.8.2.tar.gz
11. 修改Hadoop配置文件
#Master
cd hadoop-2.8.2/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim yarn-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
vim slaves
slave1
slave2
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.16.11.97:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop-2.8.2/tmp</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop-2.8.2/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop-2.8.2/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
#创建临时目录和文件目录
mkdir /usr/local/src/hadoop-2.8.2/tmp
mkdir -p /usr/local/src/hadoop-2.8.2/dfs/name
mkdir -p /usr/local/src/hadoop-2.8.2/dfs/data
12. 配置环境变量
#Master、Slave1、Slave2
vim ~/.bashrc
HADOOP_HOME=/usr/local/src/hadoop-2.8.2
export PATH=$PATH:$HADOOP_HOME/bin::$HADOOP_HOME/sbin
#刷新环境变量
source ~/.bashrc
13. 拷贝安装包
#Master
scp -r /usr/local/src/hadoop-2.8.2 root@slave1:/usr/local/src/hadoop-2.8.2
scp -r /usr/local/src/hadoop-2.8.2 root@slave2:/usr/local/src/hadoop-2.8.2
14. 启动集群
#Master
#初始化Namenode
hadoop namenode -format
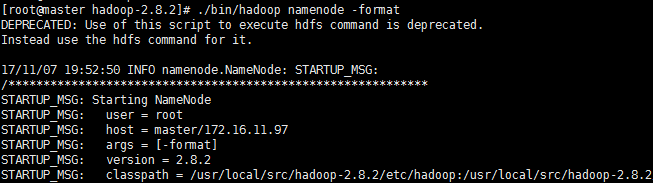

#启动集群
./sbin/start-all.sh

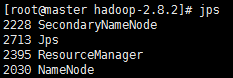
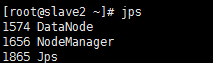
15. 集群状态
jps
#Master
#Slave1

#Slave2
16. 监控网页
http://master:8088
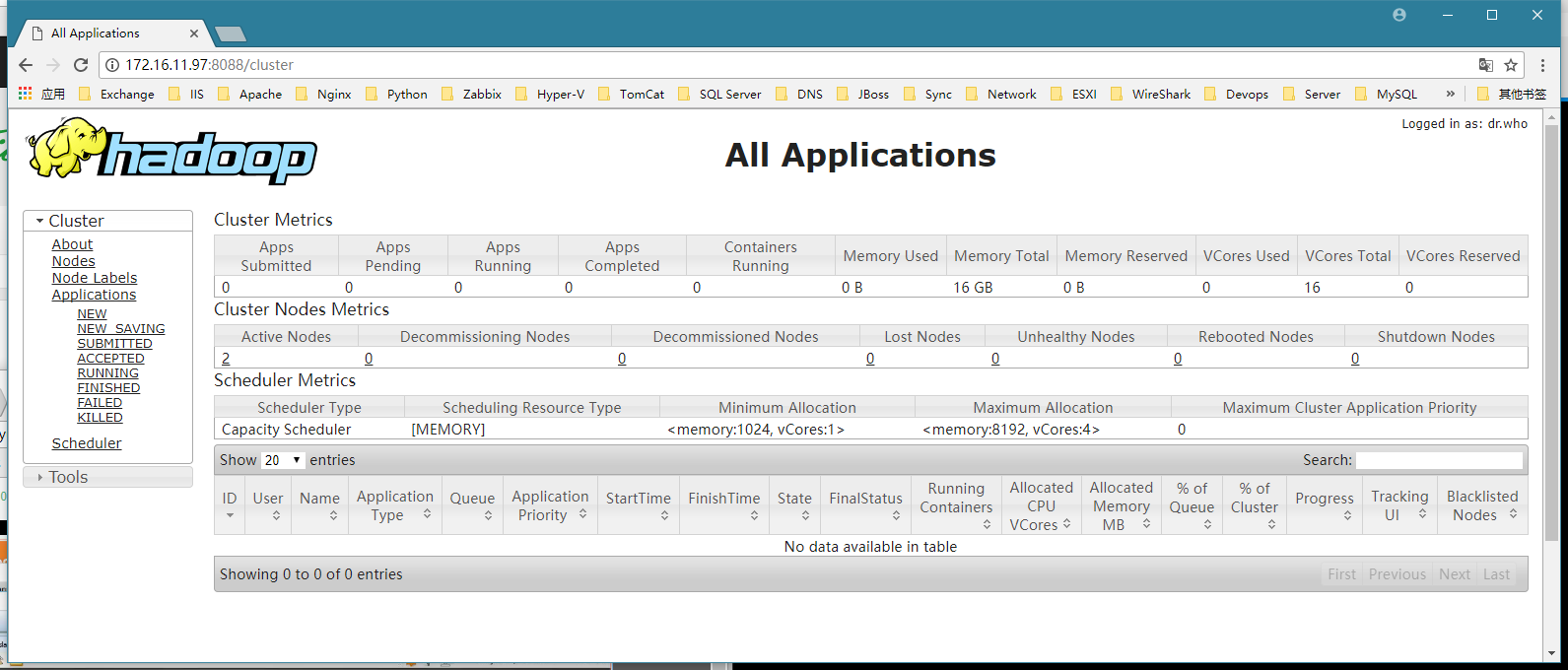
17. 操作命令
#和Hadoop1.0操作命令是一样的

18. 关闭集群
./sbin/hadoop stop-all.sh
Hadoop2.0环境安装的更多相关文章
- Hadoop2.0环境搭建
需准备的前提条件: 1. 安装JDK(自行安装) 2. 关闭防火墙(centos): systemctl stop firewalld.service systemctl disable firewa ...
- 吉特仓库管理系统-.NET4.0环境安装不上问题解决
在给客户实施软件的过程中要,要安装.NET 4.0 环境,而且是在XP的系统上. 目前的客户中仍然有大量使用XP的机器,而且极为不稳定,在安装吉特仓库管理系统客户端的时候出现了如下问题: 产品: Mi ...
- 集群架构03·MySQL初识,mysql8.0环境安装,mysql多实例
官方网址 https://dev.mysql.com/downloads/mysql/社区版本分析 MySQL5.5:默认存储引擎改为InnoDB,提高性能和可扩展性,增加半同步复制 MySQL5.6 ...
- VC6.0环境安装STLport-5.2.1
今天安装STLport,网上搜资料安装好久,都不行,因为STLport 的版本不对,我这是STLport-5.2.1新版本. (注意:下面的步骤都在一个cmd里操作,很简单的原因:环境变量啊) 1.首 ...
- 大数据笔记(三)——Hadoop2.0的安装与配置
一.Hadoop安装部署的预备条件 准备:1.安装Linux和JDK. 安装JDK 解压:tar -zxvf jdk-8u144-linux-x64.tar.gz -C ~/training/ 设置环 ...
- hadoop2.0单机安装
hadoop发行的版本:apache hadoop;HDP;CDH -----这里只使用apache hadoop---可以在网站hadoop.apache.org网站上找到 hadoop安装方式:自 ...
- vue2.0环境安装
参考网站http://www.open-open.com/lib/view/open1476240930270.html (以上博客vue init webpack-simple 工程名字<工程 ...
- fedora gtk+ 2.0环境安装配置
1.安装gtk yum install gtk2 gtk2-devel gtk2-devel-docs 2.测试是否安装成功 pkg-config --cflags --libs gtk+-2.0 执 ...
- 第一节 —— vue2.0 环境安装,工程化开发
vue的开发有两种,一种是直接的在script标签里引入vue.js文件即可,这样子引入的话个人感觉做小型的多页面会比较舒坦,一旦做大型一点的项目,还是离不开webpack. 所以另一种方法也就是基于 ...
随机推荐
- vpdn1
在使用L2TP协议构建的VPDN典型组网中,包含LAC和LNS两部分. 1.LAC LAC表示L2TP访问集中器(L2TP Access Concentrator),是附属在交换网络上的具有PPP端系 ...
- Spark源码系列:RDD repartition、coalesce 对比
在上一篇文章中 Spark源码系列:DataFrame repartition.coalesce 对比 对DataFrame的repartition.coalesce进行了对比,在这篇文章中,将会对R ...
- C++ 自定义时间
今天精神状态不好,和公司的领导请了假.为了抵抗我的痛苦,我在床上打坐冥想,从早上九点到下午三点二十六.嗯,感觉好多了.这种温和的暴力果然有效. 之后吃了点东西,然后无聊的我就在想,明天的工作该 ...
- Spring Cloud(Dalston.SR5)--Config 集群配置中心-加解密
实际应用中会涉及很多敏感的数据,这些数据会被加密保存到 SVN 仓库中,最常见的就是数据库密码.Spring Cloud Config 为这类敏感数据提供了加密和解密的功能,加密后的密文在传输给客户端 ...
- Git从库中移除已删除大文件
写在前面大家一定遇到过在使用Git时,不小心将一个很大的文件添加到库中,即使删除,记录中还是保存了这个文件.以后不管是拷贝,还是push/pull都比较麻烦.今天在上传工程到github上,发现最大只 ...
- VSFTP的使用
一.基本安装 1.安装服务 yum -y install vsftpd //centos Redhat apt-get install vsftpd //debian ubuntu 2.开启服务 se ...
- python基础知识17---装饰器2
函数式编程复习: def map_test(func,array): array_new=[] for i in array: array_new.append(func(i)) return arr ...
- JavaScript 环境和作用域
作用域 1. 全局环境 window: JS的全局执行环境,顶层对象.this指针在全局执行环境时就指向window. console.log(this===window); //true 2. 局部 ...
- 虚拟机中的linux系统文件突然全部变成只读的问题
当宿主系统和虚拟机的IO都比较繁忙时,虚拟机的IO请求得不到及时的响应.虚拟机Linux不知道自己运行在虚拟机里面,会认为是磁盘IO错误,为了保护磁盘数据会remount分区为只读. 这时候如果只是对 ...
- 读完这一篇,字符串格式化界的“白富美”(f-strings)抱回家!
f-strings 从Python 3.6开始,新引入了一种字符串格式化方法,称为“格式化字符串常量”(formatted string literal),简称f-strings.相比于%.str.f ...