Pandas基础使用
Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。
1、导入pandas
import pandas as pd
2、pandas数据类型:
1)Series:一维数据类型,其中每个元素都有一个标签
2)DataFrame:二维数据类型,它可以存储各种不同类型的数据,每个元素都有自己的标签
3、Series对象的创建
s = pd.Series([-1.234,2.354,1.256,-5.235])

可以看到如果我们没有指定行索引,pandas将会默认给它创建0,1,2,...等作为行索引
当然我们也可以给它指定行索引index,如下:

注意上面两个例子中打印出来的的type,下面我们将其中一个数字改为字符串,这时候,它就不再是单纯的数字了,它的dtype就变成了object

也就是说,我们可以指定dtype输出,如下,指定dtype为int,输出值就全部去掉小数部分,只打印出了整数部分的值:

除了上面的以list创建Series外,还可以通过字典方式,常量值等来创建Series


4、Series对象的访问
s.values:获取所有的值列表
s.index:获取所有的行索引列表
s['a'] :访问索引为'a'的元素
s[0] : 访问第1个元素
s[['a', 'b']]:访问索引为a和b的两个元素
s[:2]:访问前两个元素
5、DataFrame对象的生成
pd.DataFrame(data, index, column)
data数据类型:列表嵌套的列表,列表组成的字典,Series组成的字典,字典组成的字典等
index:行索引列表
column:列索引列表
行索引和列索引都可以为为空,pandas会自动以0,1,2,...等为它创建索引
1)以列表嵌套列表的方式生成DataFrame,外层列表长度表示行数,内层列表最大长度表示列数

2)以列表组成的字典,列表长度需要相同,将会默认以字典的key作为列索引

3)Series组成的字典生成DataFrame

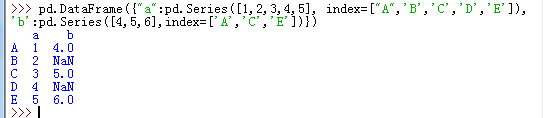
以字典形式生成的DataFrame对象,会以key的并集作为列索引,index的并集作为行索引,不存在的赋值为NaN
6、DataFrame对象的读取
df.index:获取行索引列表
df.values:获取值列表
df.columns:获取列索引列表
df.a/ df['a']:获取列索引为first的元素
df[0:1]:获取第一行元素
df[:3]:获取前三行元素
df.loc[:, :]:访问所有行,所有列元素
df.loc[:, ['a', 'b']]:访问所有行,列为a和b的元素
df.loc[['a'], ['b']]:访问行为a,列为b的元素
df.iloc[:,:]:访问所有行,所有列元素
df.iloc[0:2, :2]:访问前两行,前两列元素
df.iloc[[0,2], 0:2]:访问第1行,第3行及前两列元素
df.ix[:,:]:访问所有行,所有列元素
df.ix[:2, ['a','b']]:访问前两行,列索引为a和b的元素
df.ix[df.a>1, :2]:访问所有列索引为a的元素中,大于1的元素的行和前两列的元素
7、下面我们以股票交易数据为例来分析:
我这里有一个csv格式的近两年来的股票数据( table.csv )
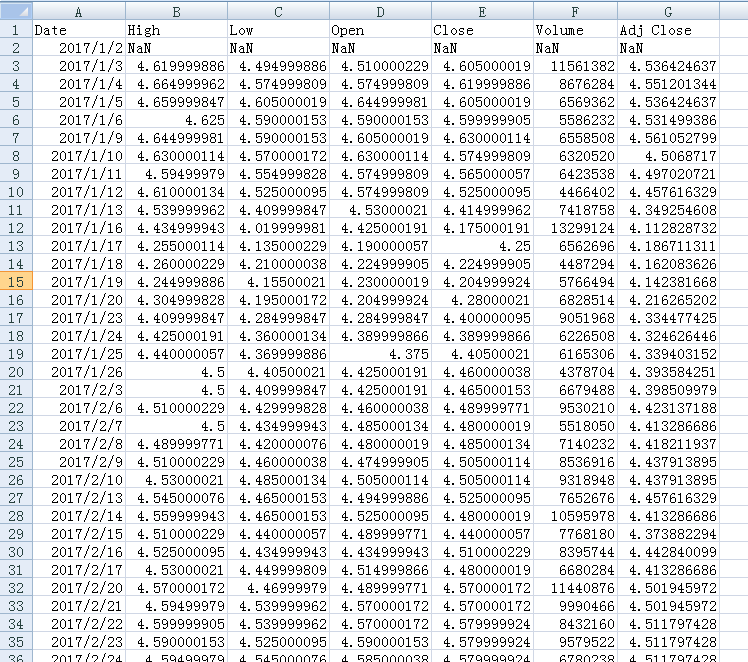
1)读取csv文件
df = pd.read_csv("C:\\Users\\admin\\Desktop\\table.csv",parse_dates=True, header=0,index_col=0,encoding="gb2312")
2)数据内容查看方法:
df.head(n):查看前n行数据
df.tail(n):查看后n行数据
df.columns:查看所有的索引列列表
df.index:查看所有的行索引列表
df.values:查看所有的值列表
df.shape:查看行数和列数
df.describe():查看基本信息,如总条数,最小值,最大值,平均数等
df.info():可以查看有几条非空数据
df.isnull():查看所有数据是否为空
df[df.isnull().T.any()]:查看含有空元素的行
df.fillna(method='bfill', axis=0, inplace=True):用下一行的数据替换掉NaN(用上一行method='ffill', 指定值替换用value=指定值)
3、特殊值处理方法
df.round(n):四舍五入,保留n位小数
df.astype(type):按照指定的格式转换数值
df.Volume.astype(int):将volume列的数值转换为int类型
applymap:可以搭配lambda使用,做数据格式转换
df.applymap(lambda x: '%0.2f' % x):保留两位小数
df.ix[:, ['Volume']].apply(lambda x: '%0.0f' % x):保留0位小数
df[df.values==0]:查找值为0的数据
df.loc[df.loc[:, high]==0, 'High'] = df.High.median():将High列为0的数值替换为High列的中间值
Pandas基础使用的更多相关文章
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- Pandas 基础(1) - 初识及安装 yupyter
Hello, 大家好, 昨天说了我会再更新一个关于 Pandas 基础知识的教程, 这里就是啦......Pandas 被广泛应用于数据分析领域, 是一个很好的分析工具, 也是我们后面学习 machi ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- python学习笔记(四):pandas基础
pandas 基础 serise import pandas as pd from pandas import Series, DataFrame obj = Series([4, -7, 5, 3] ...
- 数据分析02 /pandas基础
数据分析02 /pandas基础 目录 数据分析02 /pandas基础 1. pandas简介 2. Series 3. DataFrame 4. 总结: 1. pandas简介 numpy能够帮助 ...
随机推荐
- Docker Data Center系列(五)- 使用自定义的TLS安全认证
本系列文章演示如何搭建一个mini的云平台和DevOps实践环境. 基于这套实践环境,可以部署微服务架构的应用栈,演练提升DevOps实践能力. 1 名词说明 CSR: Certificate Sig ...
- javascript中(function($){...})(jQuery)写法是什么意思
这里实际上是匿名函数function(arg){...}这就定义了一个匿名函数,参数为arg 而调用函数 时,是在函数后面写上括号和实参的,由于操作符的优先级,函数本身也需要用括号,即:(functi ...
- 高通 NXP NFC(PN547PN548) 移植流程 android6.0
一.驱动部分 首先向NXP 的 fae要android 6.0 bring up的代码,如:NFC_NCIHALx_AR0F.4.3.0_M_NoSE 结构目录如下: 1. 添加驱动文件 高通平台需使 ...
- win10同时安装 office2016和visio2016
一.下载镜像文件 因为office 2016和 visio2016 镜像文件是一样的,只是名称不一样,所以只需要下载一个即可. 二.下载Office 2016 Deployment Tool工具 到微 ...
- Servlet(三):获取表单数据、解决乱码和报错问题
在了解了servlet的生命周期以及运行过程后,再来动手写一个小例子,加深对servlet的理解. 一.需求说明 在用户注册信息页面,输入用户名.密码.性别.邮箱等一些信息后,页面返回刚刚填写的信息. ...
- zTree获取当前节点的下一级子节点数
使用zTree插件实现树形图中,需要获取当前点击的父节点的子节点数的需求,使用treeNode.children获取子节点数据集合,使用length方法获取集合长度.将当前节点的treeNode传入即 ...
- css点滴2—六种方式实现元素水平居中
本文参考文章<六种方式实现元素水平居中> 元素水平居中的方法,最常见的莫过于给元素一个显式的宽度,然后加上margin的左右值为auto.这种方式给固定宽度的元素设置居中是最方便不过的.但 ...
- 转 CSS3+js实现多彩炫酷旋转圆环时钟效果
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...
- echarts设置y轴值间隔
其中min.max可以自定义可以动态获取数据 yAxis : [ { type : 'value', axi ...
- 【CQOI2011】放棋子
[CQOI2011]放棋子 在一个n行m列的棋盘里放一些彩色的棋子,使得每个格子最多放一个棋子,且不同颜色的棋子不能在同一行或者同一列.有多少种方法? 例如\(,n=m=3\),有两个白棋子和一个灰棋 ...