python爬虫随笔(2)—启动爬虫与xpath
启动爬虫
在上一节中,我们已经创建好了我们的scrapy项目,看着这一大堆文件,想必很多人都会一脸懵逼,我们应该怎么启动这个爬虫呢?

既然我们采用cmd命令创建了scrapy爬虫,那就得有始有终有逼格,我们仍然采用程序员的正统方式——cmd的方式运行它
scrapy crawl jobbole
当我们在cmd中输入这条命令后,我们的爬虫也就开始运行了。但是如果每次都需要这样才能启动,不仅费时费力,也难以在IDE中调试程序。面对这种情况,我们可以采取使用python来实现自动命令行的启动。好吧,真香!
于是我们在我们的项目中创建一个main.py文件
编写以下代码
# Author :Albert Shen
# -*- coding: utf-8 -*-
from scrapy.cmdline import execute
import sys
import os
if __name__ == '__main__':
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "jobbole"])
运行main.py,我们就会发现,scrapy成功开始运行,并将运行结果输出到了console窗口,此时我们也就可以充分利用IDE的优势,进行便捷的调试与运行。
初尝爬虫
既然我们的爬虫已经可以运行了,那么应该如何编写逻辑才能爬取到我们想要的数据呢?
首先我们打一个断点
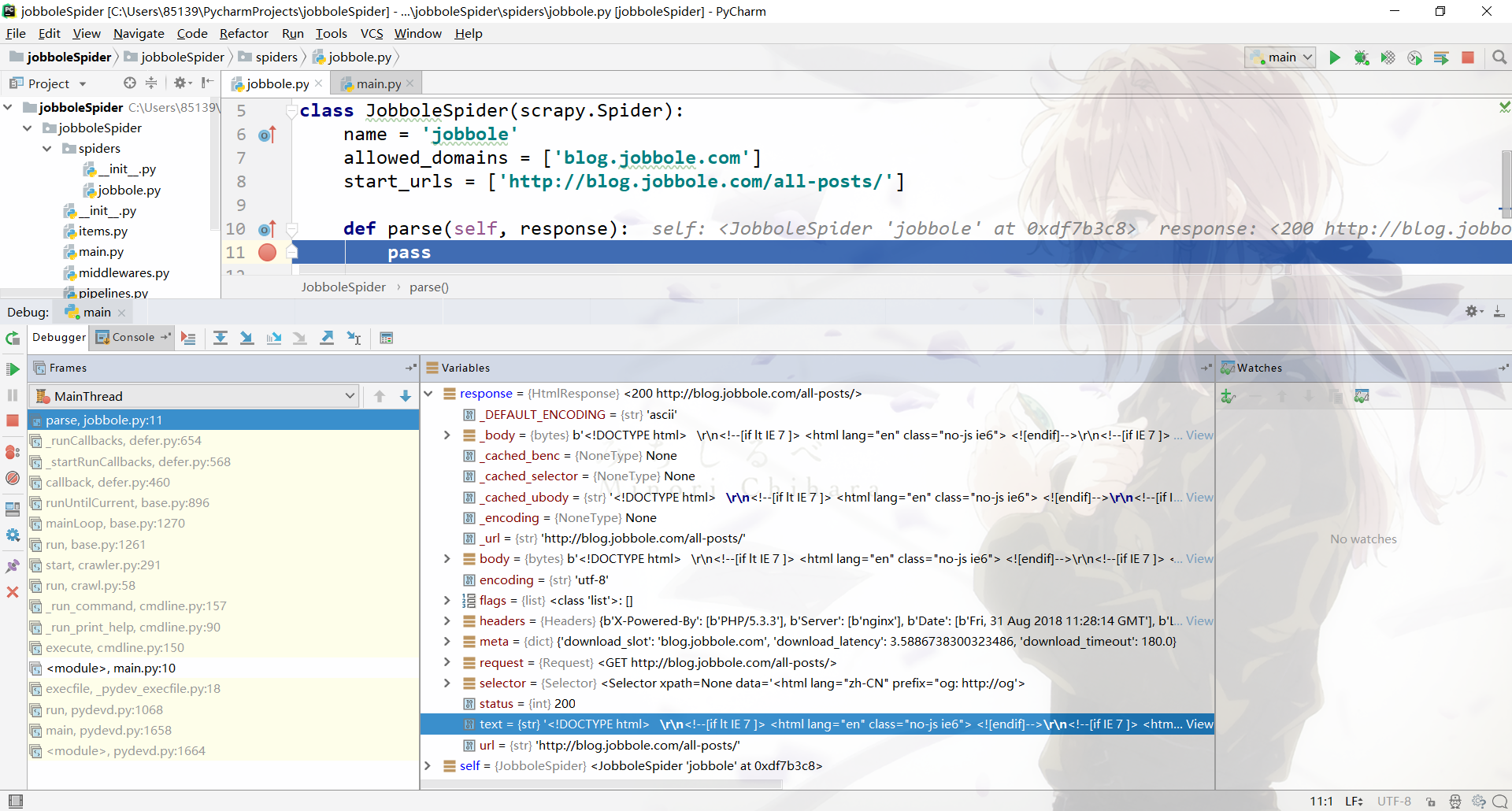
此时大家注意response对象的text变量,看起来是否很像网页的html代码。为了确认这个猜测是否正确,我们可以将text变量的值复制出来,拷贝到一个html文件中,打开发现确实是目标网页的html源代码。
这是因为当程序开始运行,scrapy获取网页数据后,调用了此文件中的parse函数,同时将获取到的数据传递给了resposne参数。这正是scrapy框架的强大之处,将前面一系列与目标网页相关的操作进行了封装,我们只需要关心怎么从网页源代码中获得想要的信息即可,所以我们后续的操作将主要围绕这response参数来进行。
如果大家尝试一些其他网页,可能会出现获得的网页与我们想要的网页不同的情况,这多是因为目标网页需要登录验证或采取了反爬虫策略,这一部分我们将在后续的文章中涉及。
xpath
既然我们已经获得了网页的源代码,那么我们应该怎么解析数据呢?可能细心的读者会注意到response.text的值是一个字符串,那么采用正则表达式不失为一种可靠的方式。但是作为一个成熟的爬虫框架,scrapy为我们提供了一种更加简便准确的方式——xpath。将我们的jobbole.py文件修改为这样
# -*- coding: utf-8 -*-
import scrapy
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
articles = response.xpath('//a[@class="archive-title"]/text()').extract()
print(articles)
pass
运行程序,打断点调试,我们发现,articles变量是一个list,包含20个字符串,正好就是目标网页的20篇文章的标题。通过一行即能实现精确的目标数据提取,正是依靠xpath。
在学习xpath之前,读者最好能对前端,尤其是HTML语言有一定了解,至少需要知道一些基本的概念。
HTML语言是一种超级文本标记语言,与后端的C,java,python等不同,HTML不是编程语言,而是标记语言,是通过一系列标签来描述网页。如果对此没有概念的读者可以简单的将其理解为HTML语言是通过一句句话告诉浏览器,首先我在这要放一段文字,然后要在这那一张图片等等,类似于画图。
HTML标记标签通常被称为HTML标签。是由尖括号<>包围的关键字,如<html>,<h1></h1>等。标签之间的部分被称为元素,同时每个标签也有属性,例如
<a href="http://www.w3school.com.cn">This is a link</a>
其中<a></a>标签表示这是一个链接,This is a link 是显示给阅读者的字符,href是它的一个属性,表示目标网址是http://www.w3school.com.cn。真实的显示效果如下图所示

点击它就能跳转到目标网页。
如果想要深入的了解HTML的知识,可以在w3school上进行学习:http://www.w3school.com.cn/
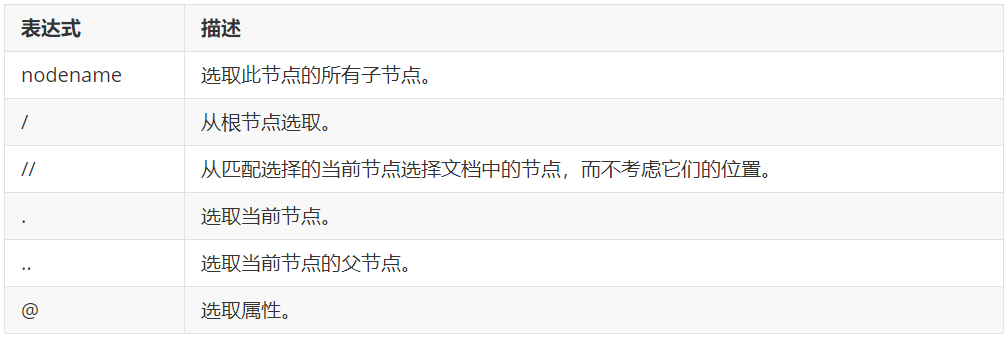
xpath正是基于此的。常用的xpath语法如下图所示(来源:w3school)
w3school关于xpath的教程:http://www.w3school.com.cn/xpath/index.asp
举一些例子

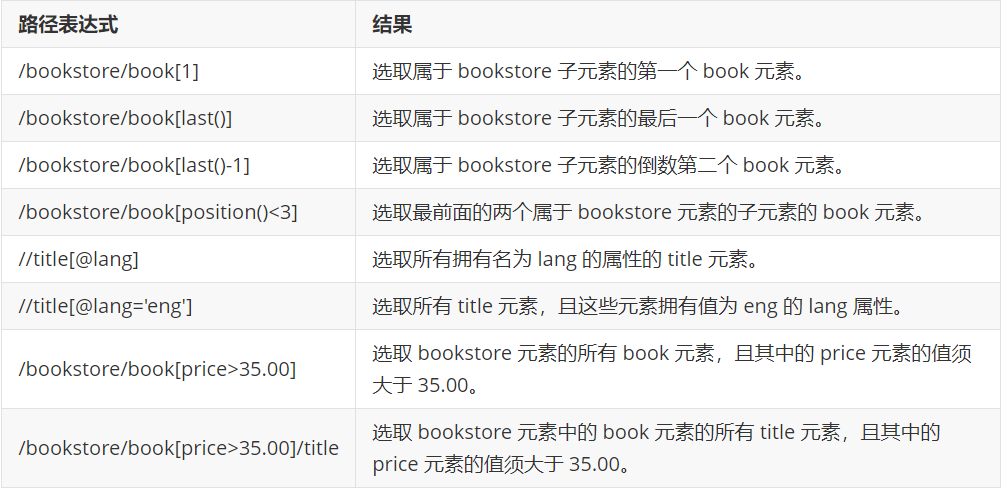
大家如果想要深入了解xpath,也建议到w3school进行进一步学习。如果对前端实在不熟悉的读者,也可以跟着笔者这个系列的教程,相信经过一段时间的练习,也能够熟练掌握相关知识。
有了上面的知识,我们来分析一下我们是怎么得到目标网页的所有标题的呢?
在浏览器中打开目标网页http://blog.jobbole.com/all-posts/,按f12(Chrome浏览器)打开开发者工具
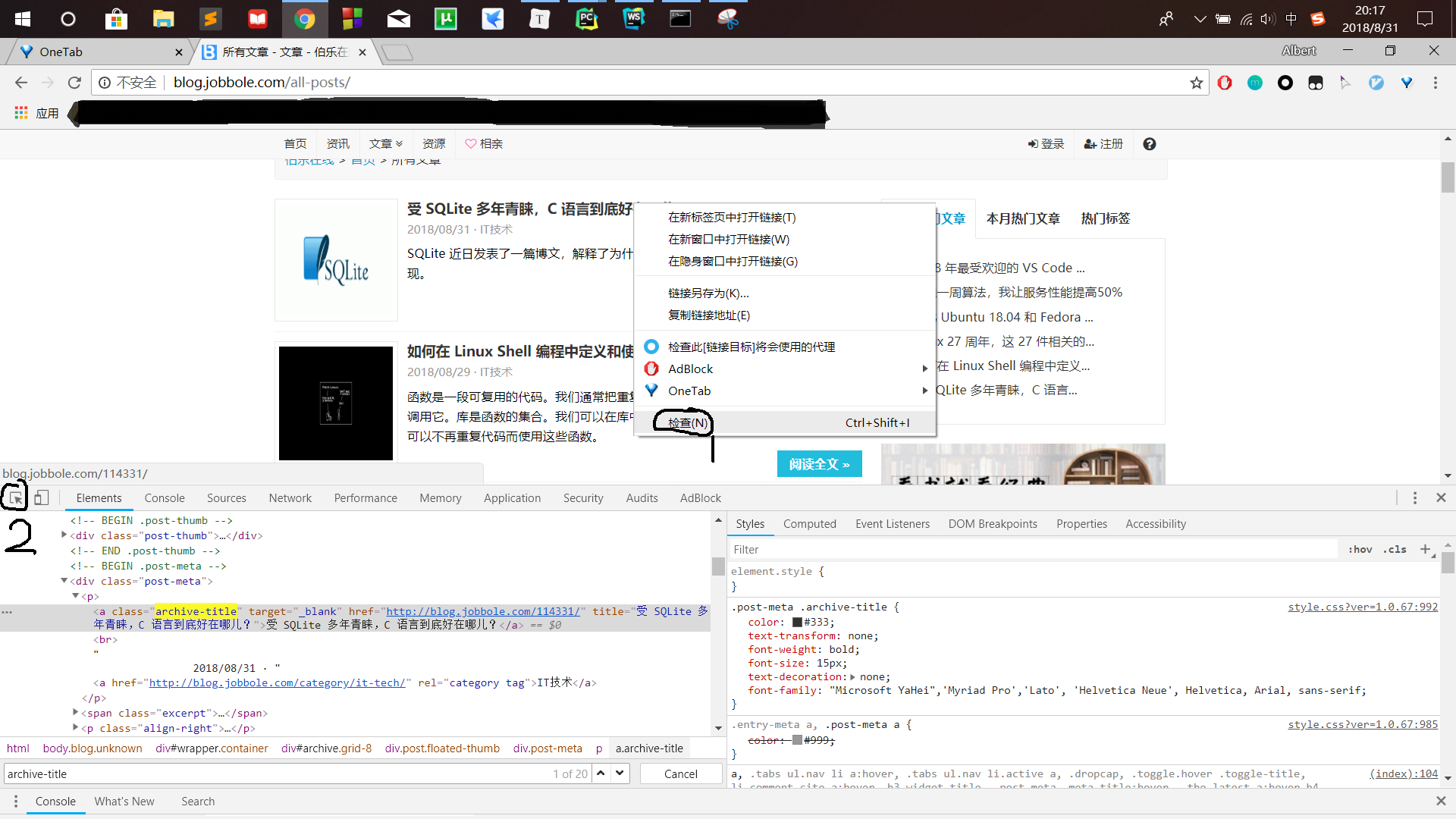
1.我们可以在想要查看的元素处右击,选择“检查”
2.在开发者攻击中点击2位置的图标,然后点击我们想要查看的元素
Chrome就会自动跳转到目标元素的源代码处。
<a class="archive-title" target="_blank" href="http://blog.jobbole.com/114331/" title="受 SQLite 多年青睐,C 语言到底好在哪儿?">受 SQLite 多年青睐,C 语言到底好在哪儿?</a>
目标元素几个比较重要的信息为
1.这是一个<a></a> (链接)
2.目标元素包含多个属性,其中一个属性为class,值为archive-title,一个属性为href,值为点击这个标题将会跳转的目标网页的网址
3.包含一个属性为title,其值与标签之间的“元素”值相同。
articles = response.xpath('//a[@class="archive-title"]/text()').extract()
我们上述代码中的 //a[@class="archive-title"] 表示取整个文档中所有( // 表示整个文档中的所有节点)包含class属性(中括号[]表示对前面标签的限制,如包含什么属性),且属性值为“archive-title”的a节点(标签)。
我们可以搜索网页的所有代码,就会发现所有包含 archive-title 字符串的只有20处,正好是本页所有文章的标题<a></a> 标签的class属性值,也就是说我们仅凭这一句话就精确地选到了我们想要的数据。
/text()表示我们想要获得这些标签的“元素”值(即标签之间的内容,也就是会在网页上显示出来的内容),如果想要获得标签的某个属性值,如href,则可以使用如下语句
response.xpath('//a[@class="archive-title"]/@href').extract()
因为我们取的是属性,所以一定不要忘了@来表示属性,如果没有a,则会认为是目标a标签下的href标签,显然是错误的。
extract()表示获得 提取出来的数据的data变量,即我们指定的标签中的内容。如果觉得这一句难以理解,读者也可以将程序中的.extract()删除,观察结果。
彩蛋:在开发者工具中,右击源代码,我们可以选择复制目标标签的xpath。同理,由于动态网页等原因,这种方式获得的xpath可能与scrapy获得的网页不匹配。这种方式可以帮助大家更深入的理解xpath,但在后续的编程过程中,笔者还是建议大家自己进行分析。
As Albert says: 既然写程序是为了偷懒,那写程序的时候就不要偷懒了。
结语
在这一节中,我们了解了如何快捷地启动scrapy,xpath基本语法,并尝试进行了scrapy爬虫的初次尝试。在后面的章节中,我们将会对整篇网页进行解析,并采用深度优先搜索遍历jobbole的所有文章,解析数据,下载封面图等。同时我们将使用到正则表达式以分析字符串来获得我们想要的数据,由于篇幅限制,笔者将不会对正则表达式进行详细介绍,建议大家提前了解一些正则表达式的基本知识。
python爬虫随笔(2)—启动爬虫与xpath的更多相关文章
- python 爬虫每天定时启动爬虫任务
# coding=utf-8 import datetime import time def doSth(): # 这里是执行爬虫的main程序 print '爬虫要开始运转了....' ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python爬虫基础04-网页解析库xpath
更简单高效的HTML数据提取-Xpath 本文地址:https://www.jianshu.com/p/90e4b83575e2 XPath 是一门在 XML 文档中查找信息的语言.XPath 用于在 ...
- Python爬虫合集:花6k学习爬虫,终于知道爬虫能干嘛了
爬虫Ⅰ:爬虫的基础知识 爬虫的基础知识使用实例.应用技巧.基本知识点总结和需要注意事项 爬虫初始: 爬虫: + Request + Scrapy 数据分析+机器学习 + numpy,pandas,ma ...
- 爬虫入门之爬取策略 XPath与bs4实现(五)
爬虫入门之爬取策略 XPath与bs4实现(五) 在爬虫系统中,待抓取URL队列是很重要的一部分.待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪 ...
- [Python3网络爬虫开发实战] 4.1-使用XPath
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言.它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索. 所以在做爬虫时,我们完全 ...
- Python 爬虫3——第一个爬虫脚本的创建
在进行真正的爬虫工程创建之前,我们先要明确我们所要操作的对象是什么?完成所有操作之后要获取到的数据或信息是什么? 首先是第一个问题:操作对象,爬虫全称是网络爬虫,顾名思义,它所操作的对象当然就是网页, ...
- python Cmd实例之网络爬虫应用
python Cmd实例之网络爬虫应用 标签(空格分隔): python Cmd 爬虫 废话少说,直接上代码 # encoding=utf-8 import os import multiproces ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
随机推荐
- cookie 和session 的区别(转)
二者的定义: 当你在浏览网站的时候,WEB 服务器会先送一小小资料放在你的计算机上,Cookie 会帮你在网站上所打的文字或是一些选择, 都纪录下来.当下次你再光临同一个网站,WEB 服务器会先看看有 ...
- mssql sqlserver 使用脚本输出excel文件的方法分享
转自:http://www.maomao365.com/?p=6683 摘要: 下文将分享使用sql脚本输出excel的方法 此脚本可以应用于 表或视图生成excel的方法,若需使用sql脚本输出ex ...
- 编译percona-server-locks-detail-5.7.22
yum install -y binutils compat-libstdc++ gcc gcc-c++ glibc glibc-devel ksh libaio libaio-devel libgc ...
- 使用concurrent.futures模块中的线程池与进程池
使用concurrent.futures模块中的线程池与进程池 线程池与进程池 以线程池举例,系统使用多线程方式运行时,会产生大量的线程创建与销毁,创建与销毁必定会带来一定的消耗,甚至导致系统资源的崩 ...
- C# -- 抽象类与抽象方法
C#: 抽象类与抽象方法 1.代码 class Program { static void Main(string[] args) { ; i < ; i++) { == ) { Storage ...
- 第10章 嵌入式Linux 的调试技术
10.1 打印内核调试信息:printk printk位函数运行在内核空间, printf函数运行在用户空间.也就是说,像Linux 驱动这样的Linux内核程序只能使用printk函数输出调试信息 ...
- LeetCode算法题-Move Zeroes(Java实现-三种解法)
这是悦乐书的第201次更新,第211篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第67题(顺位题号是283).给定一个数组nums,写一个函数将所有0移动到它的末尾,同 ...
- docker 私有仓库简易搭建
概要 本地私有仓库 局域网私有仓库 总结 概要 docker hub 使用非常方便,而且上面有大量的镜像可以使用. 但是,每次都远程下载镜像速度非常慢,如果能在本地做一个 docker 的仓库,多人协 ...
- Java操作Excel(使用JXL)
一.本地操作 1.读取 package com.ljf.mb; import java.io.FileInputStream; import java.io.InputStream; import j ...
- 英语进阶系列-A01-再别康桥
每天必读知识 音标 发音网页 人称代词与物主代词 时态 朗读50遍词汇系列1 Number word 1 be 2 have 3 get 4 give 5 take 诗歌欣赏 [原诗] [英文版] 再 ...