【PRML读书笔记-Chapter1-Introduction】1.6 Information Theory
熵
给定一个离散变量,我们观察它的每一个取值所包含的信息量的大小,因此,我们用
来表示信息量的大小,概率分布为
。当p(x)=1时,说明这个事件一定会发生,因此,它带给我的信息为0.(因为一定会发生,毫无悬念)
如果x和y独立无关,那么:
他们之间的关系为:
(p(x)=1时,h(x)=0,负号为了确保h(x)为正,这里取2为底是随机的,可以取其他的正数(除了1))
因此,对于所有x的取值,它的熵有:
注:
,当遇到
时,
这里插一段信息熵的解释:
———————————————————————————————信息熵—————————————————————————————————————————————————
信息熵是对信息的度量,那什么又是信息呢? 直观上的理解就是,知道我们原来不知道的事物就是获得信息的过程,因此对于个人来说,一件事的未知性越大,即不确定性越大,相应的信息就应该越大,传输或者存储应该付出更多的代价。例如我们说太阳从东边升起,这是一件必然的事,听到这句话没有获得任何信息,因此它的熵是0,信息论中信息与不确定性等价。
有了这个直观认识,可以对其数学化,在数学中表达不确定性的就是概率。在上面的例子中,我们讨论信息的时候,实质上是在说一件事发生的概率大小,这件事有一定概率发生。我们说信息熵是大是小,要明确是哪个随机变量的信息熵,这样才不至于迷糊。一件事发生的概率大,那么它的熵就小,一件事发生的概率小,那么它的熵就大。
问32支球队哪个得冠军,我们可以设一个随机变量X表示得冠军的球队,假设每个球队得冠军的概率相等,那么一个球队的熵x1 表示为 h(x1) = logp(x1), 所有球队求和得到X的熵:
一般情况对数取2为底,表示X对应的比特数。
总之,信息熵可以让我们定量的说出信息有多少,让一个抽象的概念可以定量的描述。另外,当我们说到信息熵的时候首先明确一下是哪个随机变量的信息熵,该随机变量的样本空间是什么,然后运用概率论的知识就可以求出来了。需要注意的是信息量的多少和信息的重要性没有必然的联系,信息熵只是在数量上给了一个数值,并非表示该信息的重要性。
———————————————————————————————————————————————————————————————————————————————————
举个例子:
假设你要发送一个离散变量给别人,这个离散变量有8个取值,并且这8个取值取到的概率相同,那么,这个变量的熵为:
另外举个例子:
一个变量含有8个状态值,
,相应的概率为:
,那么,它的熵为:
从上面的例子可以看出,不均匀分布的信息熵小于均匀分布的信息熵。这是为什么呢?
因为,如果我们想要吧这个变量发送给别人,一种方法就是用3位来表示每一个数,那么它的平均译码长度为3.
这里还有一种别的方法就是:
用
来表示。
平均的译码长度为2即可:
为了消除二异性,没有比这个更短的了。
(再次感受到了数学之美)
我们可以从另一个角度去理解信息熵:
假设有N个相同的物品,第i个箱子中有
个物品。对于第i个箱子,首先它有N种选择去取第一件物品,N-1种选择去取第二件物品,因此,对于一个箱子而言,它有N!种选择。但是,对于同一个箱子中的物品,我们并不希望加以区分,因此,对于第i个箱子而言,它有
种排序方式,因此,总的组合方法数multiplicity 为:
其中,熵为其取对数:
当
时,
,
因此,
。
对于一个特定的状态,即一个实例,称作一个“微观状态”;
对于所有的状态而言,即称作一个“宏观状态”,而w就是一个宏观状态。
对于一个特定的状态xi而言,它的概率为:
当每个微观状态发生的概率集中出现在少数值附近,往往它的熵会较小。
如图所示:
假设有M个状态,我们试图去最大化熵:
我们发现,当
相等时,相应的熵为:
,这个状态下,熵达到了最大值。
现在,我们假设x为连续型变量,我们求偏导:
其中,Iij为单位矩阵。
根据中值定理,我们可以得出:
假设变量x落在第i个箱子中的概率为:
其中:
而当
趋近于0时,上式最右侧第二项趋近于0,而第一个项则趋近的表达式称为微分熵(differential entropy):
对于连续变量而言,熵如何取最大?
首先,它满足如下约束:
使用拉格朗日乘子法可以得到:
简化得到:
可以发现,微分熵最大的概率分布为高斯分布。
我们在计算时,并没有假定微分熵一定是非负的,因此,它并不是一个必要条件。
正态分布的微分熵表达式:
可以发现,随着方差的增大,熵变大。



















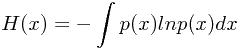





相对熵(Relative entropy)和互信息(mutual information)
相对熵(relative entropy)又称为KL散度(Kullback–Leibler divergence,簡稱KLD),信息散度(information divergence),信息增益(information gain)。
这并非是对称的,即
,仅仅在p(x)=q(x)的时候成立
—————————————————————————————————————————————————————————————————————————


—————————————————————————————————————————————————————————————————————————
凸函数:
性质:
其中,
且





琴生不等式(Jensen's inequality)
琴生不等式(Jensen's inequality)以丹麦数学家约翰·琴生(Johan Jensen)命名。它给出积分的凸函数值和凸函数的积分值间的关系。琴生不等式有以下推论:过一个凸函数上任意两点所作割线一定在这两点间的函数图象的上方,即:
概率论的版本
以概率论的名词,
是个概率测度。函数
换作实值随机变数
(就纯数学而言,两者没有分别)。在
空间上,任何函数相对于概率测度
是任一凸函数,则
。
E表示期望。连续型变量的jensen不等式为:
把jensen不等式应用在相对熵上面,得到:
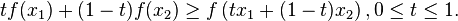


假设未知真实分布为
,我们希望使用一个参数模型
结合N个观测数据来确定一个最优的
来模拟真实分布。一种自然的方法是使用KL距离做为误差函数,以最小化
将上面的误差函数相对于参数
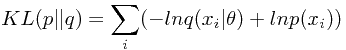
互信息(mutual information)
互信息描述了两个变量之间互相包含关于对方的信息量。定义为两个分布
和
之间的KL距离
根据相对熵的非负性可知,互信息是非负的,当仅且当两个变量相互独立时互信息为零。
由此可知,互信息可以看作,当已知一个变量的情况下,另一个变量不确定性降低的程度。
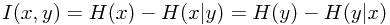
【PRML读书笔记-Chapter1-Introduction】1.6 Information Theory的更多相关文章
- 【PRML读书笔记-Chapter1-Introduction】1.5 Decision Theory
初体验: 概率论为我们提供了一个衡量和控制不确定性的统一的框架,也就是说计算出了一大堆的概率.那么,如何根据这些计算出的概率得到较好的结果,就是决策论要做的事情. 一个例子: 文中举了一个例子: 给定 ...
- 【PRML读书笔记-Chapter1-Introduction】1.2 Probability Theory
一个例子: 两个盒子: 一个红色:2个苹果,6个橘子; 一个蓝色:3个苹果,1个橘子; 如下图: 现在假设随机选取1个盒子,从中.取一个水果,观察它是属于哪一种水果之后,我们把它从原来的盒子中替换掉. ...
- PRML读书笔记——Introduction
1.1. Example: Polynomial Curve Fitting 1. Movitate a number of concepts: (1) linear models: Function ...
- PRML读书笔记——机器学习导论
什么是模式识别(Pattern Recognition)? 按照Bishop的定义,模式识别就是用机器学习的算法从数据中挖掘出有用的pattern. 人们很早就开始学习如何从大量的数据中发现隐藏在背后 ...
- PRML读书笔记——3 Linear Models for Regression
Linear Basis Function Models 线性模型的一个关键属性是它是参数的一个线性函数,形式如下: w是参数,x可以是原始的数据,也可以是关于原始数据的一个函数值,这个函数就叫bas ...
- 【PRML读书笔记-Chapter1-Introduction】1.3 Model Selection
在训练集上有个好的效果不见得在测试集中效果就好,因为可能存在过拟合(over-fitting)的问题. 如果训练集的数据质量很好,那我们只需对这些有效数据训练处一堆模型,或者对一个模型给定系列的参数值 ...
- 《深入PHP与jQuery开发》读书笔记——Chapter1
由于去实习过后,发现真正的后台也要懂前端啊,感觉javascript不懂,但是之前用过jQuery感觉不错,很方便,省去了一些内部函数的实现. 看了这一本<深入PHP与jQuery开发>, ...
- PRML读书笔记——2 Probability Distributions
2.1. Binary Variables 1. Bernoulli distribution, p(x = 1|µ) = µ 2.Binomial distribution + 3.beta dis ...
- PRML读书笔记——Mathematical notation
x, a vector, and all vectors are assumed to be column vectors. M, denote matrices. xT, a row vcetor, ...
随机推荐
- Leetcode 166. Fraction to Recurring Decimal 弗洛伊德判环
分数转小数,要求输出循环小数 如2 3 输出0.(6) 弗洛伊德判环的原理是在一个圈里,如果一个人的速度是另一个人的两倍,那个人就能追上另一个人.代码中one就是速度1的人,而two就是速度为2的人. ...
- shell日期的应用
#!bin/bash del_table() { #月初的第一天 month_first_day=`date +%Y%m01` #要删除的日期 last_7day_ago=`date -d " ...
- NXP LPC 状态可配置的定时器(SCT)
状态可配置的定时器(SCT) 前言正在申请专利的状态可配置的定时器(SCT),是一个复杂的,但易于配置的定时器,它提供前所未有的灵活性,使工程师们在未来证明他们的设计,并减少进入市场的时间.在其最简单 ...
- 关于PF_RING/Intel 82599/透明VPN的一些事
接近崩溃的边缘,今天这篇文章构思地点在医院,小小又生病了,宁可吊瓶不吃药,带了笔记本却无法上网,我什么都不能干,想了解一些东西,只能用3G,不敢 开热点,因为没人给我报销流量,本周末我只有一天时间,因 ...
- Install MongoDB driver for PHP on XAMPP for Mac OSX
试了不少方法,最后还是这个最有效. [转自:http://thatsimplecode.com/install-mongodb-driver-for-php-on-xampp-for-mac-osx] ...
- Andriod Studio 开发环境安装和配置
Android Studio安装配置详细步骤(图文):http://www.2cto.com/kf/201604/500642.html第一次使用Android Studio时你应该知道的一切配置 : ...
- jackson readTree
String jsonstr = "{\"msg\":{\"head\":{\"version\":\"1.0\&quo ...
- webstorm 配合IIS使用
添加名称之后 点击apply 再点击ok 然后在打开设置 就可以配置下图的信息 我们需要在webstorm里面打开IIS部署的地址怎么设置呢? 技术交流QQ群:15129679
- Maven - 项目结构
一个基础的Maven Java项目结构图如下所示: Project Name |__________ pom.xml |__________ src | |__ ...
- 频域分辨率与DFT,DCT,MDCT理解
搞了这么久音频算法,有些细节还没有很清楚. 比如DFT和DCT有哪些区别,DFT系数为什么会是对称的,同样帧长的数据,各自的频域分辨率是多少? 今天决定搞清楚这些问题, 首先DFT的系数对称(2N点的 ...