Erlang 程序引发共享内存 bug 的一个例子
虽然 Erlang 的广告说得非常好,functional、share-nothing、消息传递,blah blah 的,好像用 Erlang 写并发程序就高枕无忧了,但是由于 Erlang 信奉高度实用主义的哲学,所以 Erlang 中有各种各样的后门,使得 Erlang 是一个不那么 pure 的 functional 语言,而且也是允许 share something 的。
比如说,ETS 就是一个大后门。ETS 本是为实现 Mnesia 数据库而实现的一个“基于哈希表的无结构化 term 存储”,但是 ETS 太好用了,能满足高性能的字典需求,而且还可以全局访问,完全摆脱 Erlang 设置的 share nothing、immutable variable 之类的 functional 束缚,所以很多程序会喜欢使用 ETS。
Erlang 的(为了避免错误而设置的)种种约束在这些使用了这些后门的情况下也会丧失威力。这不,我在标准库的 digraph 模块中就发现了一个潜在的 bug。下面先说一下使用 ETS 造成并发 bug 的模式,然后再看 digraph 中的这个潜在 bug。
Erlang 中有很多这样的代码:V2 = do_something(V1),如果 V1 和 V2 是同样类型的复杂数据结构,根据 Erlang 的语义,do_something 对 V1 只是读操作,然后生成新的字段,最后创建出新的 V2 返回,V1 应该是不动的。这样其他进程也可以放心地访问 V1,至少 V1 的状态在系统中是一致的(consistent)。如果 V1 中使用了 ETS,并且 do_something 对 ETS 做操作了,那么这个函数就产生副作用了,以上的一致性可能就无法保证了,例如假设 V1 是这样的数据结构:
-record(some_struct, {tab1 = ets:tab(),
tab2 = ets:tab(),
var1 = integer()}).
这个数据结构中有两个 ETS 表,说明这个数据结构的状态是由两个 ETS 表的状态决定的。虽然 Erlang 运行时能保证单个 ETS 表的并发访问,但是多个表的一致性还需要程序自己来维护,因此这个数据结构在多进程访问的情况下就会出现竞争条件。下面我们看看 digraph 模块中的潜在 bug。
digraph 模块是用来表示有向图(directed graph)的。有向图就是在一个图中,要考虑边(edge)中顶点(vertex)的顺序。有向图的数据结构中要保存顶点的集合以及边的集合。某个顶点的邻居(neighbour)指的是和这个顶点相连的顶点,由于有向图是有方向的,所以一个顶点会有入邻居(in-neighbour)和出邻居(out-neighbour),前者指的是有边射入当前顶点的顶点,后者指的是当前顶点有边射出到的顶点。好了这是基本概念。下面我们看 digraph 模块使用的数据结构:
-record(digraph, {vtab = notable :: ets:tab(),
etab = notable :: ets:tab(),
ntab = notable :: ets:tab(),
cyclic = true :: boolean()}).
digraph 记录体中连续 3 个 ETS 表,看上去就有不好的事情可能发生。vtab 是顶点的表,etab 是边的表,ntab 维护了邻居的关系。digraph 模块对 digraph 数据结构并发访问做了控制,允许设置两种模式:protected 和 private。前者只允许 digraph 的所有者进程修改,但是其他进程都可以访问;后者只允许所有者进程修改和访问,其他进程不能访问(其实就是设置了 ETS 表的访问权限)。
下面创建一个简单的有向图,创建几个节点和边:

5> DG = digraph:new().
{digraph,28692,32789,36886,true}
6> digraph:add_vertex(DG, v1).
v1
省略...
11> digraph:add_edge(DG, v1, v2).
['$e'|0]
省略...
16> digraph:in_neighbours(DG, v1).
[]
17> digraph:in_neighbours(DG, v2).
[v1]
省略...
21> digraph:out_neighbours(DG, v1).
[v5,v4,v3,v2]
命令 5> 创建了新的 digraph,输出的 DG 值中包含了几个 ETS id,然后添加顶点和边。v1 顶点的入邻居没有,出邻居包括 v2、v3、v4 和 v5。下面展示了这几个 ETS 表中的项:
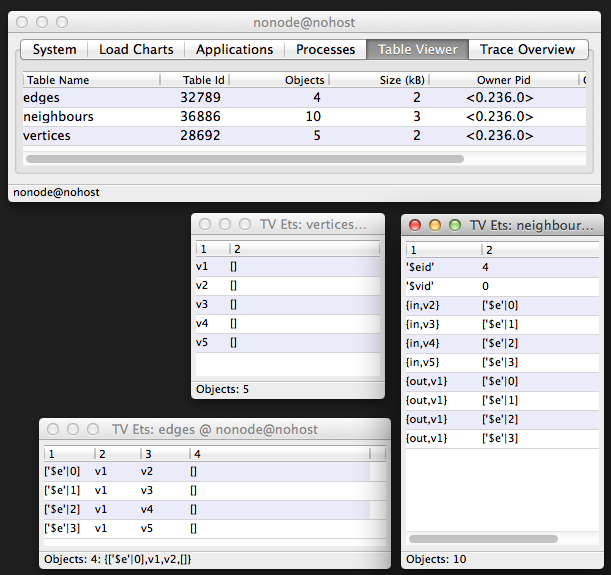
vertices 表中是顶点,edges 表中是边,neighbour 表中保存了 in 和 out 的关系。其实 neighbour 表中的内容可以从 edges 表中推导出来,但是这个表在这里可以做一个缓存作用,迅速查出一个节点的邻居关系,而不用扫描 edges 表。
从这里我们应该可以嗅到 bug 的味道了:edges 表和 neighbour 表有映射关系,如果修改一个表,那么另一个表也需要修改,否则就会出现数据不一致(inconsistent)的情况。我们来看插入边的代码:
add_edge(G, V1, V2) ->
do_add_edge({new_edge_id(G), V1, V2, []}, G). do_add_edge({E, V1, V2, Label}, G) ->
case ets:member(G#digraph.vtab, V1) of
false -> {error, {bad_vertex, V1}};
true ->
case ets:member(G#digraph.vtab, V2) of
false -> {error, {bad_vertex, V2}};
true ->
case other_edge_exists(G, E, V1, V2) of
true -> {error, {bad_edge, [V1, V2]}};
false when G#digraph.cyclic =:= false ->
acyclic_add_edge(E, V1, V2, Label, G);
false ->
do_insert_edge(E, V1, V2, Label, G)
end
end
end. do_insert_edge(E, V1, V2, Label, #digraph{ntab=NT, etab=ET}) ->
ets:insert(NT, [{{out, V1}, E}, {{in, V2}, E}]),
ets:insert(ET, {E, V1, V2, Label}),
E.
diagraph:add_edge/3 是发布的接口,do_add_edge/2 做一些顶点是否存在的判断,检查是否能添加边,最后 do_insert_edge/5 真正负责把边插入相应的 ETS 表。可以看出,第 22 行插入邻居表,第 23 行插入边表。
这里就可能出现问题了:根据 Erlang 调度器的规则,第 22 行执行完成之后,由于 ets:insert/2 是一个 BIF 调用,因此进程有可能会被抢占。如果此时进程被抢占,那么 digraph 就处于一个 inconsistent 状态了。如下图所示:
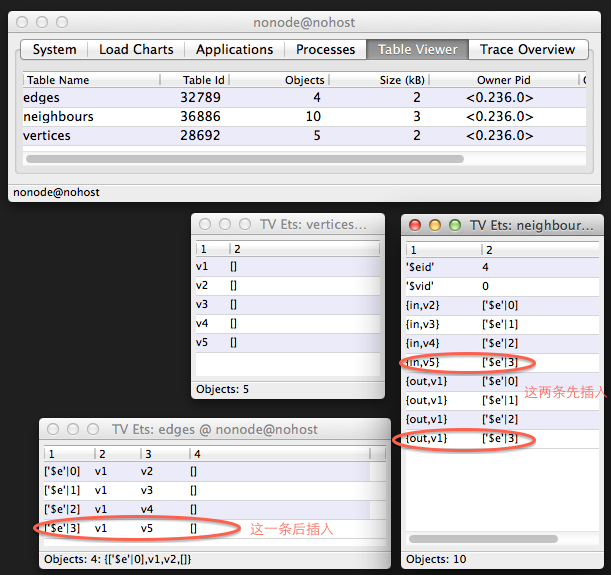
假设这个 digraph 是 protected,那么其他进程是可以访问的。如果其他进程需要 joint 访问这两个表的话,有可能就会出问题。果然,访问邻居的接口 digraph:in_neighbours/2 就是这样一个函数,下面来看代码:
in_neighbours(G, V) ->
ET = G#digraph.etab,
NT = G#digraph.ntab,
collect_elems(ets:lookup(NT, {in, V}), ET, 2). collect_elems(Keys, Table, Index) ->
collect_elems(Keys, Table, Index, []). collect_elems([{_,Key}|Keys], Table, Index, Acc) ->
collect_elems(Keys, Table, Index,
[ets:lookup_element(Table, Key, Index)|Acc]);
collect_elems([], _, _, Acc) -> Acc.
in_neighbours/2 先提取出两个表 ET 和 NT,分别是边表和邻居表,然后调用 collect_elems/3,相当于做一个 joint 查询。第 4 行首先查询邻居表 ets:lookup(NT, {in, V}),也就是在邻居表中查询节点 V 入边。查到边之后,collect_elems/4 的第 11 行再从边表中去查这条边的顶点。那么如果出现上图中的情况,在添加边的时候在邻居表中插入完成之后进程被切出,那么 edges 表中的第 4 行还不存在,而 neighbours 表中圈出的那两行是存在的。那么 collect_elems/4 执行到 11 行的 ets:lookup_element 就会抛出异常。
以上就是在标准库的 digraph 模块中发生竞争条件的一个例子。对于这个具体的问题来说,把 do_insert_edge/5 中那两行 insert 换一下位置就好了,先插入边表,再插入邻居表,毕竟后面的表可以由前面的表推导出来,所以在访问的时候先访问后面的表在访问前面的表不会出现查不到的情况,尽管本质上看数据还是有可能不一致。所以虽然可以修掉这个 bug,但是这种风格还是有风险的,比如说有 3 个或更多的表需要一致的情况。其实 digraph 模块这种风格:创建一个数据结构,得到一个句柄,然后大家都可以修改和访问的风格不是非常“Erlangic”。应该是像这样的设计:DG = digraph:new(), DG1 = digraph:add_vertex(DG, v1)... 。也就是说,每次修改之后就产生一个新的变量。当然,这样在内部就不能用 ETS 来实现了,因为每次修改的是 ETS 表,而 DG 变量绑定的 #digraph{} 里面的表 id 字段的值又没变,所以 DG 和 DG1 的值实际还是一样的,只是表示的意义不同了,可怕的副作用啊。
至于这是不是 bug,可能有人会争论了:至少 ETS 查询会抛 badarg 啊,然后这个异常会传播到 in_neighours/2 的调用者啊,所以在调用的时候要捕捉异常啊。可是 digraph 文档又没说会抛异常,看源码的时候,也没有语法结构注明一个函数会抛什么异常,那我怎么知道什么时候要捉异常呢?就算我养成调什么函数都捉异常的习惯,可是我捉到了异常又怎么知道是怎么回事呢?特别是这种并发相关的问题,下次复现的几率又像中奖一样。所以 Erlang 这门语言真是让人又爱又恨啊。
不过不争论语言本身了,言归正传,本文的结论就是:在使用 ETS 的时候要注意 ETS 是全局共享的内存,要注意数据一致性的问题。
Erlang 程序引发共享内存 bug 的一个例子的更多相关文章
- DELPHI编写服务程序总结(在系统服务和桌面程序之间共享内存,在服务中使用COM组件)
DELPHI编写服务程序总结 一.服务程序和桌面程序的区别 Windows 2000/XP/2003等支持一种叫做“系统服务程序”的进程,系统服务和桌面程序的区别是:系统服务不用登陆系统即可运行:系统 ...
- linux下共享内存mmap和DMA(直接访问内存)的使用 【转】
转自:http://blog.chinaunix.net/uid-7374279-id-4413316.html 介绍Linux内存管理和内存映射的奥秘.同时讲述设备驱动程序是如何使用“直接内存访问” ...
- Linux环境进程间通信(五): 共享内存(上)
linux下进程间通信的几种主要手段: 管道(Pipe)及有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允 ...
- 【转】Linux环境进程间通信(五) 共享内存(上)
转自:https://www.ibm.com/developerworks/cn/linux/l-ipc/part5/index1.html 采用共享内存通信的一个显而易见的好处是效率高,因为进程可以 ...
- mmap映射文件至内存( 实现 共享内存 与 文件的另类访问 )
Linux提供了内存映射函数mmap, 它把文件内容映射到一段内存上(准确说是虚拟内存上), 通过对这段内存的读取和修改, 实现对文件的读取和修改, 先来看一下mmap的函数声明: 头文件: < ...
- <转>Linux环境进程间通信(五): 共享内存(上)
http://www.ibm.com/developerworks/cn/linux/l-ipc/part5/index1.html 采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写 ...
- Linux环境进程间通信: 共享内存
Linux环境进程间通信: 共享内存 第一部分 共享内存可以说是最有用的进程间通信方式,也是最快的IPC形式.两个不同进程A.B共享内存的意思是,同一块物理内存被映射到进程A.B各自的进程地址空间.进 ...
- (转)Linux环境进程间通信系列(五):共享内存
原文地址:http://www.cppblog.com/mydriverc/articles/29741.html 共享内存可以说是最有用的进程间通信方式,也是最快的 IPC 形式.两个不同进程 A ...
- Linux学习笔记(14)-进程通信|共享内存
在Linux中,共享内存是允许两个不相关的进程访问同一个逻辑内存的进程间通信方法,是在两个正在运行的进程之间共享和传递数据的一种非常有效的方式. 不同进程之间共享的内存通常安排为同一段物理内存.进程可 ...
随机推荐
- 手把手教你从购买vps到搭建一个node服务器
要准备什么? 1.5刀 2.最好有FQ软件(可以用蓝灯) let's Go! 一.vps购买 vps可以选择digital ocean(do) 链接 ,由于是外国网站,响应比较慢,所以最好翻个墙. g ...
- Mysql学习笔记(三)运算符和控制流函数
本章学习内容: 1.操作符 2.控制流程函数 操作符: i.圆括号.. 简单的介绍一下圆括号,圆括号的使用的目的是规定计算表达式的顺序...这个想必大家都熟悉例如 mysql>select 1 ...
- 初涉SQL Server性能问题(4/4):列出最耗资源的会话
在上3篇文章里,我们讨论了列出反映服务器当前状态的不同查询. 初涉SQL Server性能问题(1/4):服务器概况 初涉SQL Server性能问题(2/4):列出等待资源的会话 初涉SQL Ser ...
- python内置模块(4)
这一部分是python内置模块系列的最后一部分,介绍了一些小巧有用的内置模块. 目录: 1.random 2.shelve 3.getpass 4.zipfile 5.tarfile 6.bisect ...
- 一个简单的3DTouch、Peek和Pop手势Demo,附github地址
参考文章:http://www.jianshu.com/p/74fe6cbc542b 下载链接:https://github.com/banchichen/3DTouch-PeekAndPopGest ...
- Scrum 项目 6.0
-------------------------6.0------------------------------------ sprint演示 1.坚持所有的sprint都结束于演示. 团队的成果 ...
- IIS启动网站出错的几个解决方法
在ASP.NET项目中使用了IIS服务器,由于系统是XP的,而在装系统的时候IIS没有一起装,所以从网上下载的IIS5.0版本(其它版本XP是用不了的).但是在使用的过程中老是出问题,每次调试好后,过 ...
- 重新想象 Windows 8.1 Store Apps (74) - 新增控件: Flyout, MenuFlyout, SettingsFlyout
[源码下载] 重新想象 Windows 8.1 Store Apps (74) - 新增控件: Flyout, MenuFlyout, SettingsFlyout 作者:webabcd 介绍重新想象 ...
- python peewee.ImproperlyConfigured: MySQLdb or PyMySQL must be installed.
最近在学习Python,打算先看两个在线教程,再在github上找几个开源的项目练习一下,在学到“被解放的姜戈”时遇到django同步数据库时无法执行的错误,记录一下. 错误现象: 执行python ...
- spring mvc 框架搭建及详解
现 在主流的Web MVC框架除了Struts这个主力 外,其次就是Spring MVC了,因此这也是作为一名程序员需要掌握的主流框架,框架选择多了,应对多变的需求和业务时,可实行的方案自然就多了.不 ...