k-近邻算法原理入门-机器学习
//2019.08.01下午
机器学习算法1——k近邻算法
1、k近邻算法是学习机器学习算法最为经典和简单的算法,它是机器学习算法入门最好的算法之一,可以非常好并且快速地理解机器学习的算法的框架与应用。
2、kNN机器学习算法具有以下的特点:
(1)思想极度简单
(2)应用的数学知识非常少
(3)解决相关问题的效果非常好
(4)可以解释机器学习算法使用过程中的很多细节问题
(5)更加完整地刻画机器学习应用的流程
其原理图如下:在所有的原有数据集基础上判断新的点的属性分类时,指定k的值,然后找到所有原始数据点中与其新输入需要判断的点的最近的k的点,然后根据这k个点的属性分类来确定新的点的属性。

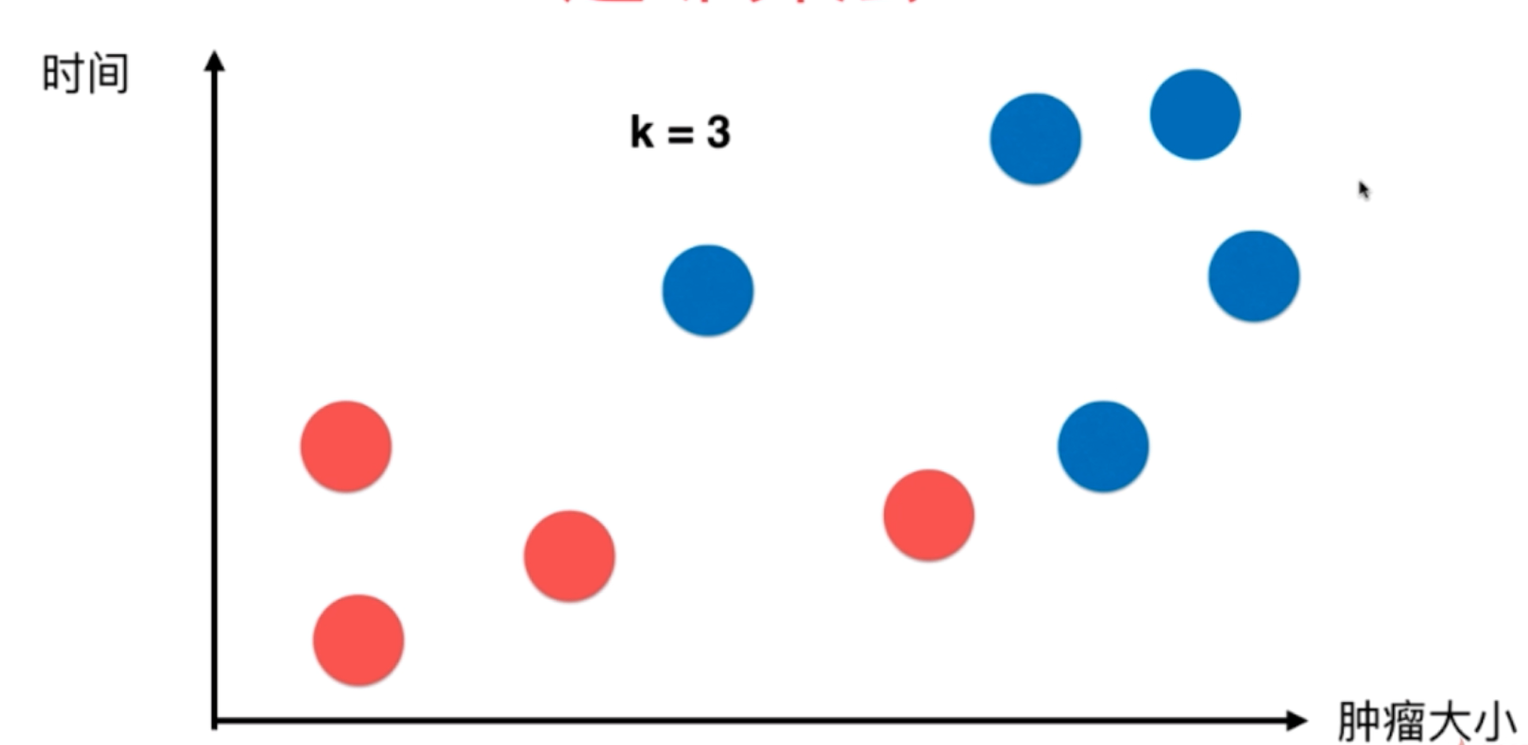
图1 原始数据点
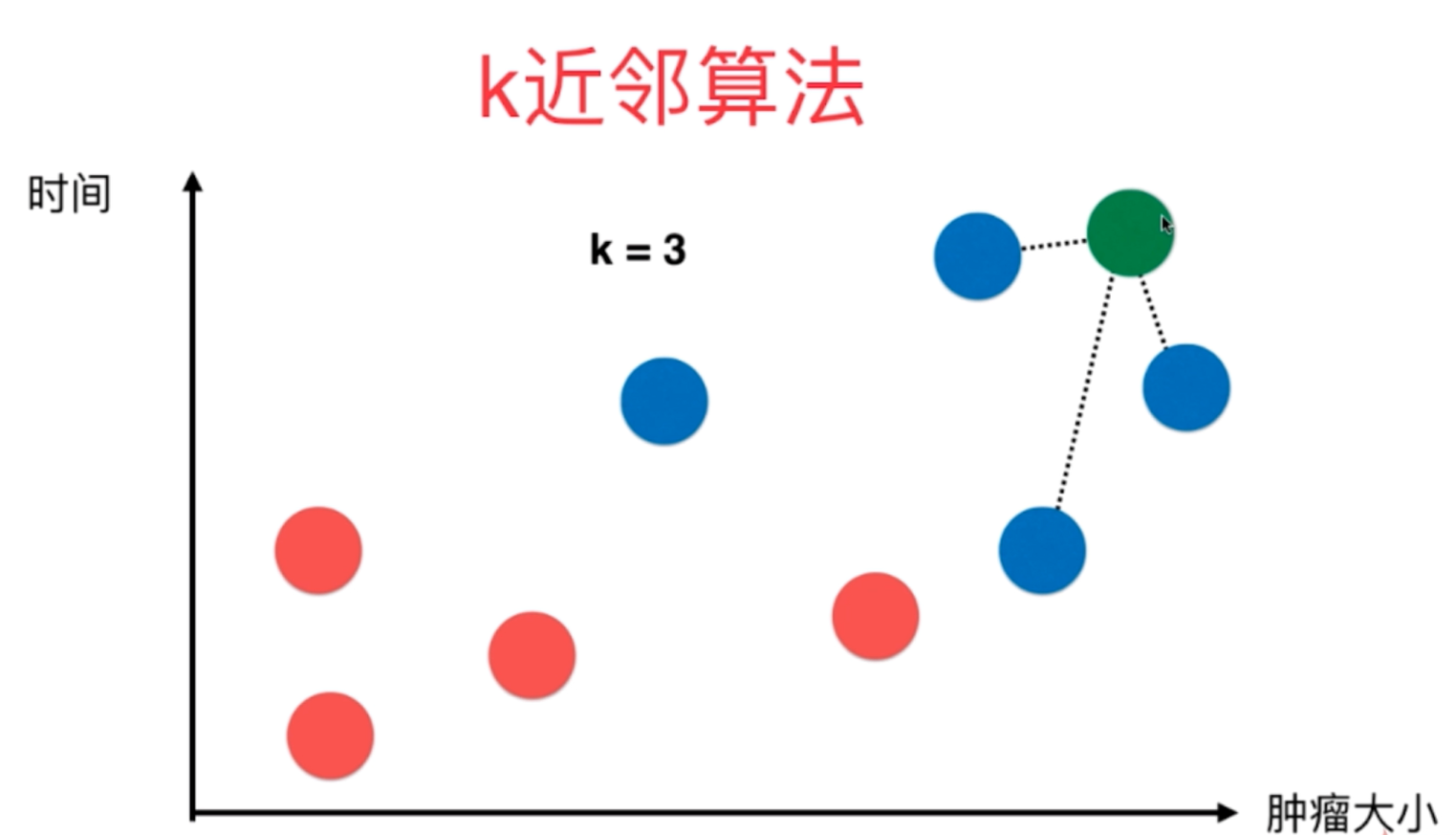
图2 新输入点的分布位置,指定k为3,即找到最近的三个点
4、KNN算法原理介绍及其训练学习代码实现:
import numpy as np
import matplotlib.pyplot as plt #导入相应的数据可视化模块
raw_data_X=[[3.393533211,2.331273381],
[3.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
raw_data_Y=[0,0,0,0,0,1,1,1,1,1]
print(raw_data_X)
print(raw_data_Y)
x_train=np.array(raw_data_X)
y_train=np.array(raw_data_Y) #数据的预处理,需要将其先转换为矩阵,并且作为训练数据集
print(x_train)
print(y_train)
plt.figure(1)
plt.scatter(x_train[y_train==0,1],x_train[y_train==0,0],color="g")
plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1],color="r") #将其散点图输出
x=np.array([8.093607318,3.365731514]) #定义一个新的点,需要判断它到底属于哪一类数据类型
plt.scatter(x[0],x[1],color="b") #在算点图上输出这个散点,看它在整体散点图的分布情况
#kNN机器算法的使用
from math import sqrt
distance=[]
for x_train in x_train:
d=sqrt(np.sum((x_train-x)**2))
distance.append(d)
print(distance)
d1=np.argsort(distance) #输出distance排序的索引值
print(d1)
k=6
n_k=[y_train[(d1[i])] for i in range(0,k)]
print(n_k)
from collections import Counter #导入Counter模块
c=Counter(n_k).most_common(1)[0][0] #Counter模块用来输出一个列表中元素的个数,输出的形式为列表,其里面的元素为不同的元组
#另外的话对于Counter模块它有.most_common(x)可以输出统计数字出现最多的前x个元组,其中元组的key是其元素值,后面的值是出现次数
y_predict=c
print(y_predict)
plt.show() #输出点的个数
实现代码及其结果如下:

k-近邻算法原理入门-机器学习的更多相关文章
- AI小记-K近邻算法
K近邻算法和其他机器学习模型比,有个特点:即非参数化的局部模型. 其他机器学习模型一般都是基于训练数据,得出一般性知识,这些知识的表现是一个全局性模型的结构和参数.模型你和好了后,不再依赖训练数据,直 ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- K近邻算法:机器学习萌新必学算法
摘要:K近邻(k-NearestNeighbor,K-NN)算法是一个有监督的机器学习算法,也被称为K-NN算法,由Cover和Hart于1968年提出,可以用于解决分类问题和回归问题. 1. 为什么 ...
- 机器学习算法之K近邻算法
0x00 概述 K近邻算法是机器学习中非常重要的分类算法.可利用K近邻基于不同的特征提取方式来检测异常操作,比如使用K近邻检测Rootkit,使用K近邻检测webshell等. 0x01 原理 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
随机推荐
- inode节点使用率过大处理
当发现某个分区下的inode使用率过大时,需要找到该分区下的某些目录里有哪些文件可以清理. 查找某个目录下一个月或两个月之前的文件,然后删除# find . -type f -mtime +30 |w ...
- 「JSOI2011」分特产
「JSOI2011」分特产 传送门 计数题. 考虑容斥掉每人至少一个的限制. 就直接枚举至少有多少人没有分到特产,然后剩下的随便分. \[Ans = \sum_{i = 0}^n (-1)^i {n ...
- Python - 同时运行两个以上的脚本
在c.py中 import os os.system("python a.py") os.system("python b.py")
- Duilib 窗口之间的消息传递
转载:https://www.cnblogs.com/Alberl/p/3404240.html 1.定义消息ID #define WM_USER_POS_CHANGED WM_USER + 2 2. ...
- Windows对应的"Hello,world"程序
<Windows程序设计>(第五版)(美Charles Petzold著) https://docs.microsoft.com/zh-cn/windows/desktop/apiinde ...
- linux中cp指令前面加反斜杠
在cp指令前面加反斜杠可以不弹出是否覆盖的询问而直接覆盖! 如:cp /app/WEB-INF/com/cfg.properties /app_bak/WEB-INF/com/cfg.properti ...
- uniapp - 导航切换(样式)
<view class="text-area" v-for="(menu,i) in menus" :key="i" v-show=& ...
- ORACLE varchar2类型的字段更改为clob
将varchar2类型字段改成clob类型 --增加临时新字段 alter table base_temp add temp clob; --将需要改成大字段的项内容copy到大字段中updat ...
- Linux centosVMware LNMP架构介绍、MySQL安装、PHP安装、Nginx介绍
一. LNMP架构介绍 和LAMP不同的是,提供web服务的是Nginx 并且php是作为一个独立服务存在的,这个服务叫做php-fpm Nginx直接处理静态请求,动态请求会转发给php-fpm ...
- 手机号----IP api
/* *手机号码API */ $fPArr = iconv("gbk","utf-8",file_get_contents($fphone)); echo $f ...