NLP(一)
“自然语言处理”(Natural Language Processing 简称 NLP)包含所有用计算机对自然语言进行的操作。
自然语言工具包(NLTK)
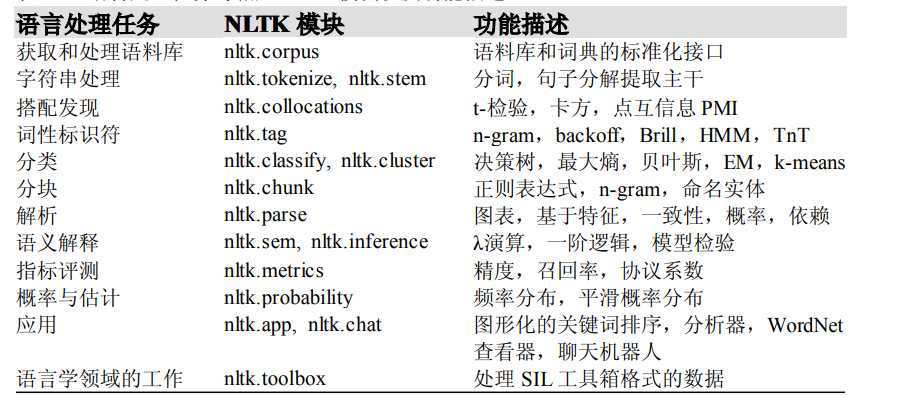
语言处理任务与相应 NLTK 模块以及功能描述
NLTK 频率分布类中定义的函数


示例:简单的语音对话系统的流程架构:
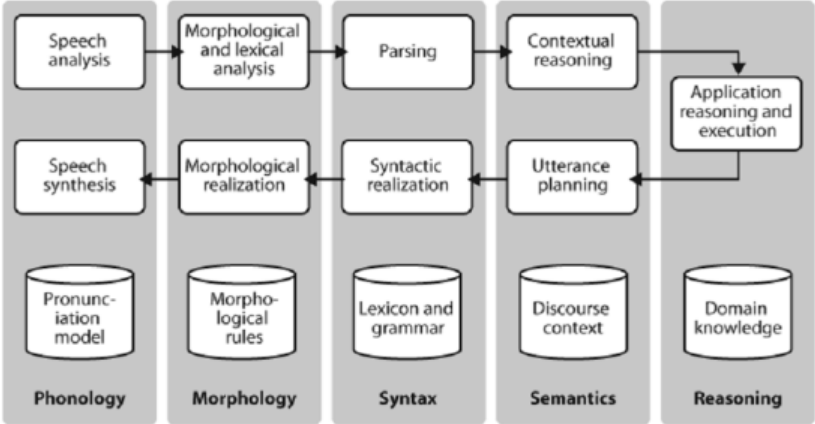
分析语音输入(左上),识别单词,文法分析和在 上下文中解释,应用相关的具体操作(右上);响应规划,实现文法结构,然后是适当的词 形变化,最后到语音输出;处理的每个过程都蕴含不同类型的语言学知识
在自然语言处理的实际项目中,通常要使用大量的语言数据或者语料库,
文本语料库的结构
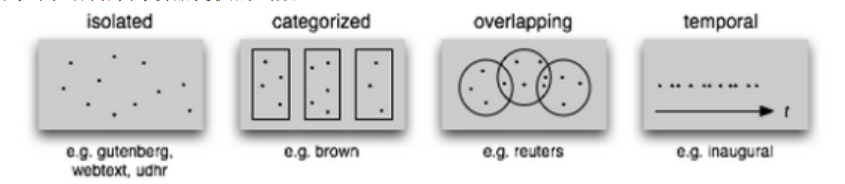
通常,文本会按照其可能对应的文体、来源、作者、 语言等分类。有时,这些类别会重叠,尤其是在按主题分类的情况下,因为一个文本可能与 多个主题相关。偶尔的,文本集有一个时间结构,新闻集合是最常见的例子
文本语料库的常见结构:最简单的一种语料库是一些孤立的没有什么特别的组织的 文本集合;一些语料库按如文体等分类组织结构;一些分类会重叠,如主题 类别;另外一些语料库可以表示随时间变化语言用法的改变。
NLTK 中定义的基本语料库函数



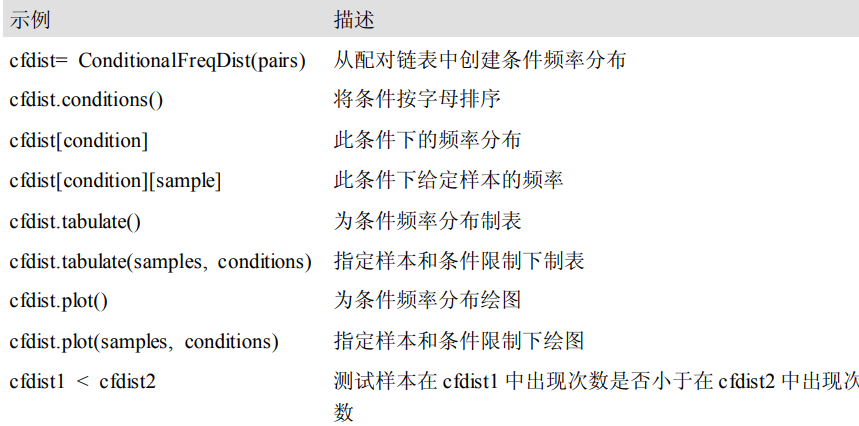
NLTK 中的条件频率分布:定义、访问和可视化一个计数的条件频率分布的常用方法和习惯用法
标注是典型的 NLP 流水线中分词之后的第二个步骤
将词汇按它们的词性(parts-of-speech,POS)分类以及相应的标注它们的过程被称为词 性标注(part-of-speech tagging, POS tagging)或干脆简称标注。词性也称为词类或词汇范 畴。用于特定任务的标记的集合被称为一个标记集。
分类是为给定的输入选择正确的类标签的任务。在基本的分类任务中,每个输入被认为 是与所有其它输入隔离的,并且标签集是预先定义的
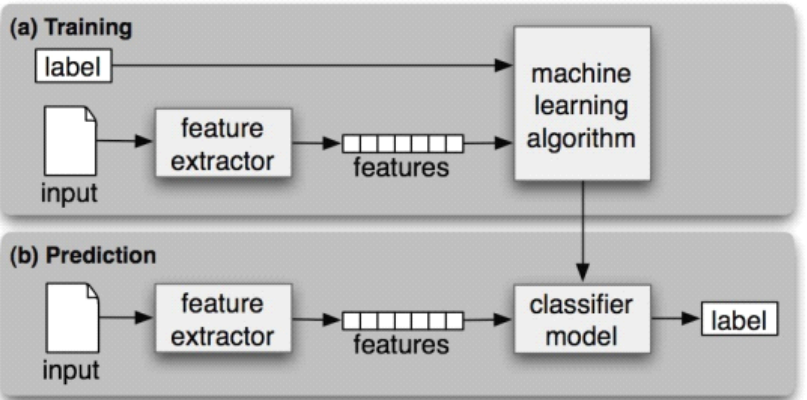
(a)在训练过程中,特征提取器用来将每一个输入值转换为特征集。 这些特征集捕捉每个输入中应被用于对其分类的基本信息,我们将在下一节中讨论它。特征 集与标签的配对被送入机器学习算法,生成模型。(b)在预测过程中,相同的特征提取器被 用来将未见过的输入转换为特征集。之后,这些特征集被送入模型产生预测标签
分类器可以帮助我们理解自然语言中存在的语言模式,允许我们建立明确的模型捕捉这些模式。
自动生成分类模型的三种机器学习方法:决策树、朴素贝叶斯分类器和最大熵分类器
NLP(一)的更多相关文章
- 【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理
干货!详述Python NLTK下如何使用stanford NLP工具包 作者:白宁超 2016年11月6日19:28:43 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的 ...
- 【NLP】十分钟快览自然语言处理学习总结
十分钟学习自然语言处理概述 作者:白宁超 2016年9月23日00:24:12 摘要:近来自然语言处理行业发展朝气蓬勃,市场应用广泛.笔者学习以来写了不少文章,文章深度层次不一,今天因为某种需要,将文 ...
- 【NLP】前戏:一起走进条件随机场(一)
前戏:一起走进条件随机场 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有 ...
- 【NLP】蓦然回首:谈谈学习模型的评估系列文章(一)
统计角度窥视模型概念 作者:白宁超 2016年7月18日17:18:43 摘要:写本文的初衷源于基于HMM模型序列标注的一个实验,实验完成之后,迫切想知道采用的序列标注模型的好坏,有哪些指标可以度量. ...
- 【NLP】Python NLTK处理原始文本
Python NLTK 处理原始文本 作者:白宁超 2016年11月8日22:45:44 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开 ...
- 【NLP】Python NLTK获取文本语料和词汇资源
Python NLTK 获取文本语料和词汇资源 作者:白宁超 2016年11月7日13:15:24 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集 ...
- NLP点滴——文本相似度
[TOC] 前言 在自然语言处理过程中,经常会涉及到如何度量两个文本之间的相似性,我们都知道文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性.而有了文本之间相似性的度 ...
- 【NLP】Python NLTK 走进大秦帝国
Python NLTK 走进大秦帝国 作者:白宁超 2016年10月17日18:54:10 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公 ...
- 【NLP】基于自然语言处理角度谈谈CRF(二)
基于自然语言处理角度谈谈CRF 作者:白宁超 2016年8月2日21:25:35 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】基于机器学习角度谈谈CRF(三)
基于机器学习角度谈谈CRF 作者:白宁超 2016年8月3日08:39:14 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都 ...
随机推荐
- java实现漏掉的账目明细
某财务部门结账时发现总金额不对头.很可能是从明细上漏掉了某1笔或几笔.如果已知明细账目清单,能通过编程找到漏掉的是哪1笔或几笔吗? 如果有多种可能,则输出所有可能的情况. 我们规定:用户输入的第一行是 ...
- PAT 跟奥巴马一起编程
美国总统奥巴马不仅呼吁所有人都学习编程,甚至以身作则编写代码,成为美国历史上首位编写计算机代码的总统.2014 年底,为庆祝“计算机科学教育周”正式启动,奥巴马编写了很简单的计算机代码:在屏幕上画一个 ...
- org.openqa.selenium.WebDriverException: It is impossible to create a new session because 'createSession' which takes HttpClient, InputStream and long was not found or it is not accessible 异常
检查项目配置的jdk版本是否过低,修改一下配置就解决了.如果是jdk版本过低的就升级一下jdk.
- 微信小程序 简单获取屏幕视口高度
由于小程序的宽度是固定的 750rpx,我们可以先用wx.getSystemInfo 来获取可使用窗口的宽高(并非rpx),结合750rpx的宽度算出比例,再用比例来算出高度 let that = t ...
- 【String注解驱动开发】如何按照条件向Spring容器中注册bean?这次我懂了!!
写在前面 当bean是单实例,并且没有设置懒加载时,Spring容器启动时,就会实例化bean,并将bean注册到IOC容器中,以后每次从IOC容器中获取bean时,直接返回IOC容器中的bean,不 ...
- kafka能做什么?kafka集群配置 (卡夫卡 大数据)
什么是Kafka 官网介绍: 几个概念: 详细介绍 : 操作kafka: kafka集群 消息测试 问题检测 什么是Kafka 官网介绍: ApacheKafka是一个分布式流媒体平台.这到底是什么意 ...
- Markdown 主题修改
加粗字体的颜色修改 strong, b{ color: #111111; } 斜体的颜色修改 em, i { color: #111111; } 高亮字体的背景颜色修改 #write mark { b ...
- 2.Go--hello world
编写一个hello world package main import ( "fmt" "time" ) func main(){ fmt.Println(&q ...
- DML_Data Modification_DELETE
DML_Data Modification_Delete删除记录比较简单,但是需要特别注意,一不小心,就变成了 “从删库到跑路“ 就掉的大了 /* Microsoft SQL Server 2008 ...
- 五个Taurus垃圾回收compactor优化方案,减少系统资源占用
简介 TaurusDB是一种基于MySQL的计算与存储分离架构的云原生数据库,一个集群中包含多个存储几点,每个存储节点包含多块磁盘,每块磁盘对应一个或者多个slicestore的内存逻辑结构来管理. ...